 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generalized Vector Space Model for Ontology-Based Information Retrieval
Jul 20, 2018Named entities (NE) are objects that are referred to by names such as people, organizations and locations. Named entities and keywords are important to the meaning of a document. We propose a generalized vector space model that combines named entities and keywords. In the model, we take into account different ontological features of named entities, namely, aliases, classes and identifiers. Moreover, we use entity classes to represent the latent information of interrogative words in Wh-queries, which are ignored in traditional keyword-based searching. We have implemented and tested the proposed model on a TREC dataset, as presented and discussed in the paper.
Ontology-Based Query Expansion with Latently Related Named Entities for Semantic Text Search
Jul 15, 2018



Traditional information retrieval systems represent documents and queries by keyword sets. However, the content of a document or a query is mainly defined by both keywords and named entities occurring in it. Named entities have ontological features, namely, their aliases, classes, and identifiers, which are hidden from their textual appearance. Besides, the meaning of a query may imply latent named entities that are related to the apparent ones in the query. We propose an ontology-based generalized vector space model to semantic text search. It exploits ontological features of named entities and their latently related ones to reveal the semantics of documents and queries. We also propose a framework to combine different ontologies to take their complementary advantages for semantic annotation and searching. Experiments on a benchmark dataset show better search quality of our model to other ones.
WordNet-Based Information Retrieval Using Common Hypernyms and Combined Features
Jul 15, 2018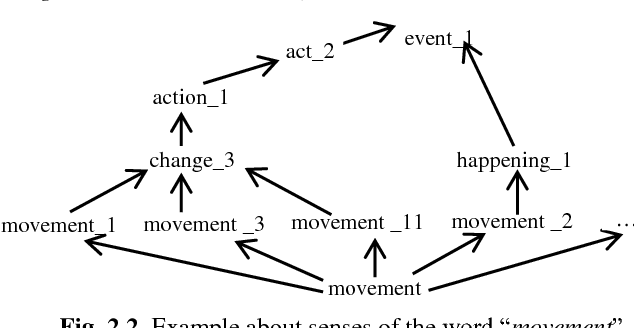
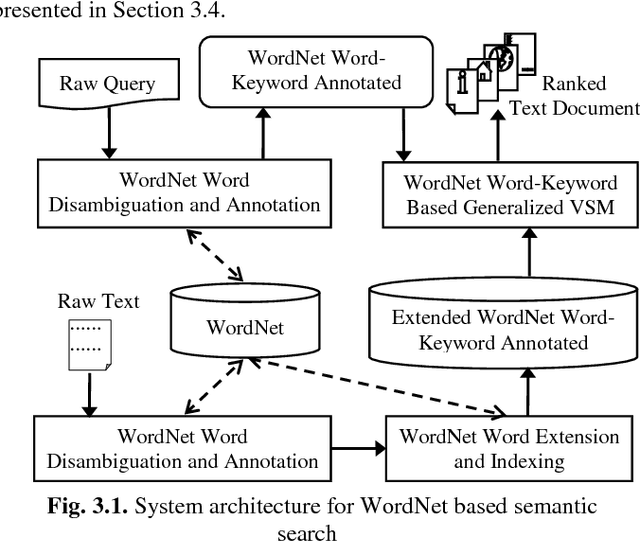
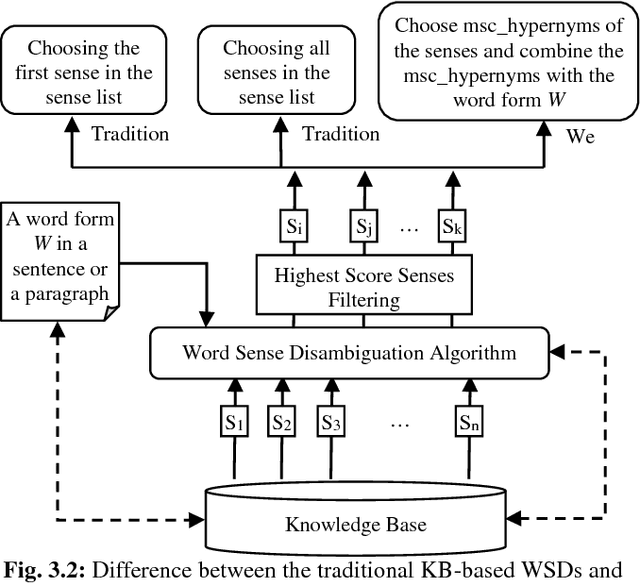
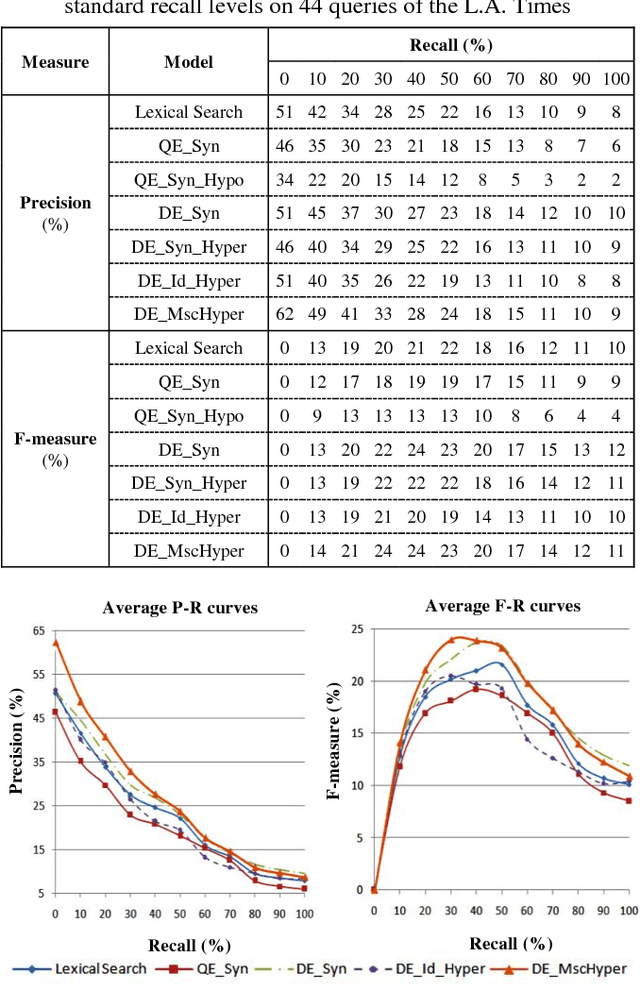
Text search based on lexical matching of keywords is not satisfactory due to polysemous and synonymous words. Semantic search that exploits word meanings, in general, improves search performance. In this paper, we survey WordNet-based information retrieval systems, which employ a word sense disambiguation method to process queries and documents. The problem is that in many cases a word has more than one possible direct sense, and picking only one of them may give a wrong sense for the word. Moreover, the previous systems use only word forms to represent word senses and their hypernyms. We propose a novel approach that uses the most specific common hypernym of the remaining undisambiguated multi-senses of a word, as well as combined WordNet features to represent word meanings. Experiments on a benchmark dataset show that, in terms of the MAP measure, our search engine is 17.7% better than the lexical search, and at least 9.4% better than all surveyed search systems using WordNet. Keywords Ontology, word sense disambiguation, semantic annotation, semantic search.