 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning-based Nutrient Application's Timeline Recommendation for Smart Agriculture: A Large-Scale Data Mining Approach
Oct 18, 2023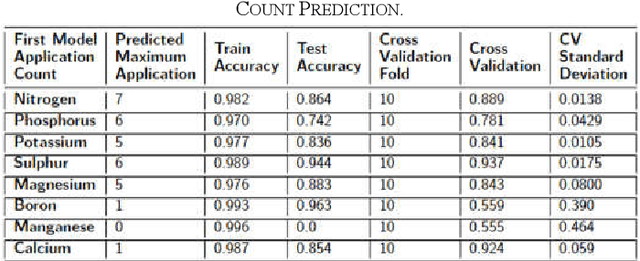
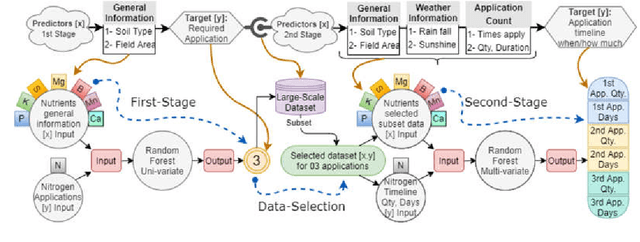
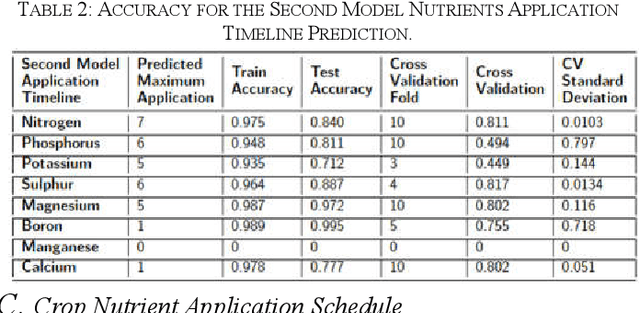
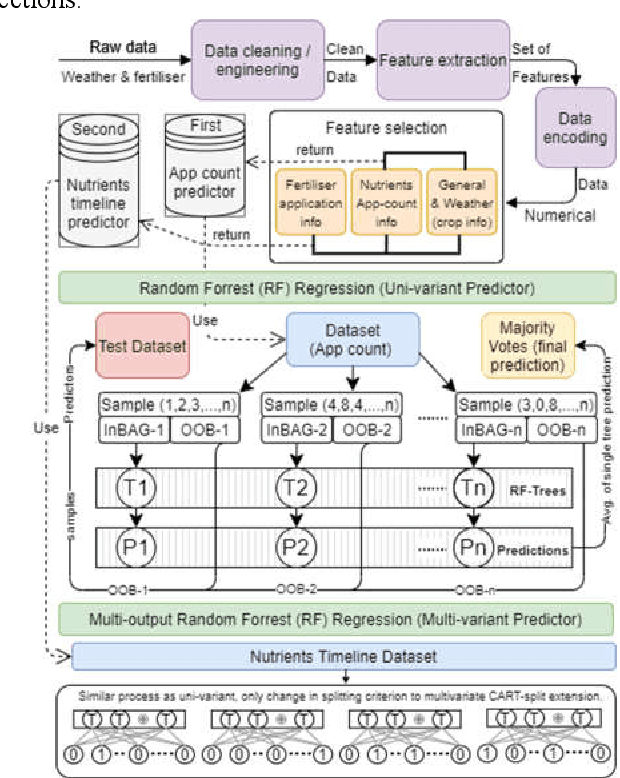
This study addresses the vital role of data analytics in monitoring fertiliser applications in crop cultivation. Inaccurate fertiliser application decisions can lead to costly consequences, hinder food production, and cause environmental harm. We propose a solution to predict nutrient application by determining required fertiliser quantities for an entire season. The proposed solution recommends adjusting fertiliser amounts based on weather conditions and soil characteristics to promote cost-effective and environmentally friendly agriculture. The collected dataset is high-dimensional and heterogeneous. Our research examines large-scale heterogeneous datasets in the context of the decision-making process, encompassing data collection and analysis. We also study the impact of fertiliser applications combined with weather data on crop yield, using the winter wheat crop as a case study. By understanding local contextual and geographic factors, we aspire to stabilise or even reduce the demand for agricultural nutrients while enhancing crop development. The proposed approach is proven to be efficient and scalable, as it is validated using a real-world and large dataset.
IP-UNet: Intensity Projection UNet Architecture for 3D Medical Volume Segmentation
Aug 24, 2023

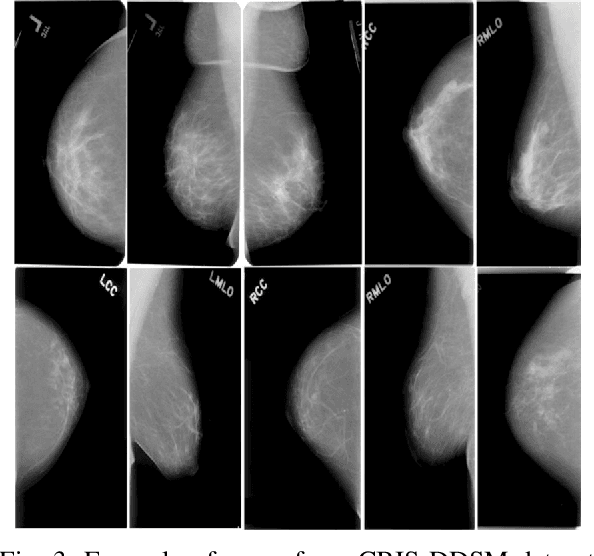
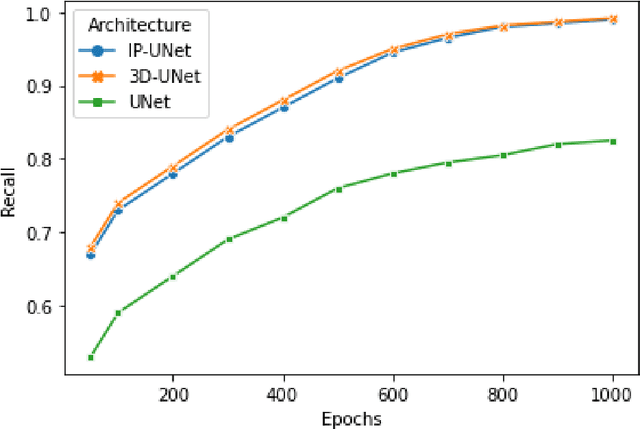
CNNs have been widely applied for medical image analysis. However, limited memory capacity is one of the most common drawbacks of processing high-resolution 3D volumetric data. 3D volumes are usually cropped or downsized first before processing, which can result in a loss of resolution, increase class imbalance, and affect the performance of the segmentation algorithms. In this paper, we propose an end-to-end deep learning approach called IP-UNet. IP-UNet is a UNet-based model that performs multi-class segmentation on Intensity Projection (IP) of 3D volumetric data instead of the memory-consuming 3D volumes. IP-UNet uses limited memory capability for training without losing the original 3D image resolution. We compare the performance of three models in terms of segmentation accuracy and computational cost: 1) Slice-by-slice 2D segmentation of the CT scan images using a conventional 2D UNet model. 2) IP-UNet that operates on data obtained by merging the extracted Maximum Intensity Projection (MIP), Closest Vessel Projection (CVP), and Average Intensity Projection (AvgIP) representations of the source 3D volumes, then applying the UNet model on the output IP images. 3) 3D-UNet model directly reads the 3D volumes constructed from a series of CT scan images and outputs the 3D volume of the predicted segmentation. We test the performance of these methods on 3D volumetric images for automatic breast calcification detection. Experimental results show that IP-Unet can achieve similar segmentation accuracy with 3D-Unet but with much better performance. It reduces the training time by 70\% and memory consumption by 92\%.
OAK4XAI: Model towards Out-Of-Box eXplainable Artificial Intelligence for Digital Agriculture
Sep 29, 2022

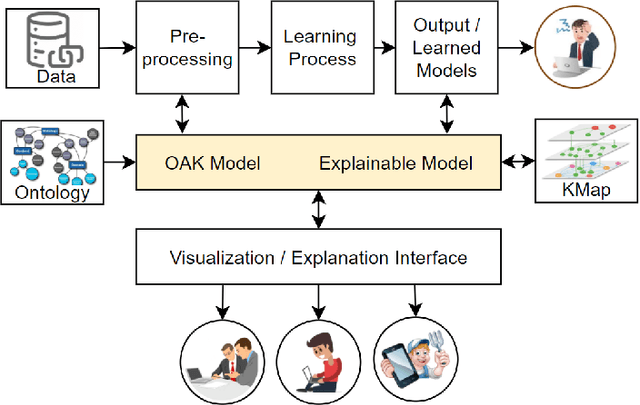
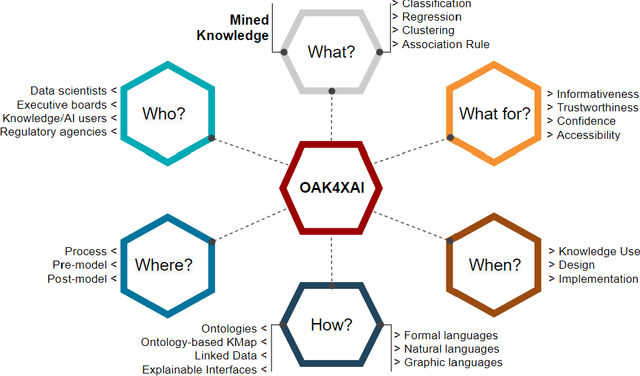
Recent machine learning approaches have been effective in Artificial Intelligence (AI) applications. They produce robust results with a high level of accuracy. However, most of these techniques do not provide human-understandable explanations for supporting their results and decisions. They usually act as black boxes, and it is not easy to understand how decisions have been made. Explainable Artificial Intelligence (XAI), which has received much interest recently, tries to provide human-understandable explanations for decision-making and trained AI models. For instance, in digital agriculture, related domains often present peculiar or input features with no link to background knowledge. The application of the data mining process on agricultural data leads to results (knowledge), which are difficult to explain. In this paper, we propose a knowledge map model and an ontology design as an XAI framework (OAK4XAI) to deal with this issue. The framework does not only consider the data analysis part of the process, but it takes into account the semantics aspect of the domain knowledge via an ontology and a knowledge map model, provided as modules of the framework. Many ongoing XAI studies aim to provide accurate and verbalizable accounts for how given feature values contribute to model decisions. The proposed approach, however, focuses on providing consistent information and definitions of concepts, algorithms, and values involved in the data mining models. We built an Agriculture Computing Ontology (AgriComO) to explain the knowledge mined in agriculture. AgriComO has a well-designed structure and includes a wide range of concepts and transformations suitable for agriculture and computing domains.
Knowledge Representation in Digital Agriculture: A Step Towards Standardised Model
Jul 15, 2022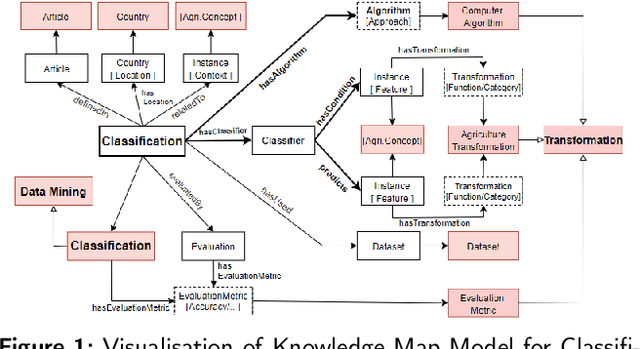
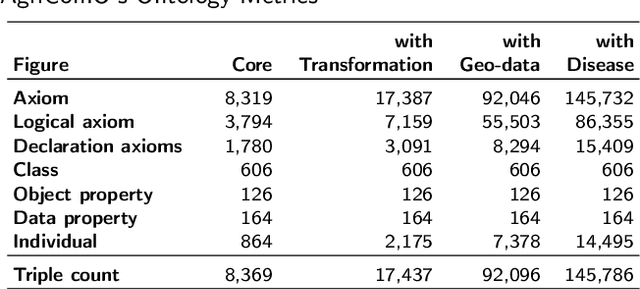
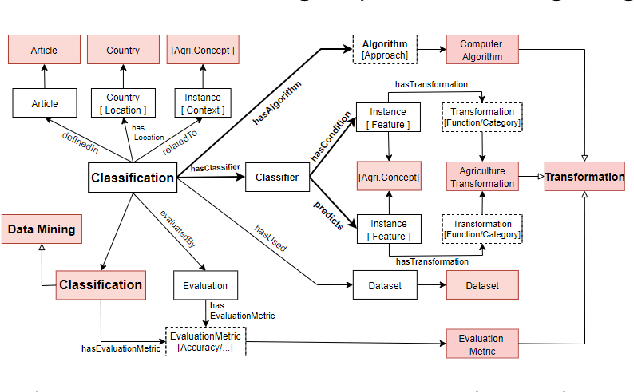

In recent years, data science has evolved significantly. Data analysis and mining processes become routines in all sectors of the economy where datasets are available. Vast data repositories have been collected, curated, stored, and used for extracting knowledge. And this is becoming commonplace. Subsequently, we extract a large amount of knowledge, either directly from the data or through experts in the given domain. The challenge now is how to exploit all this large amount of knowledge that is previously known for efficient decision-making processes. Until recently, much of the knowledge gained through a number of years of research is stored in static knowledge bases or ontologies, while more diverse and dynamic knowledge acquired from data mining studies is not centrally and consistently managed. In this research, we propose a novel model called ontology-based knowledge map to represent and store the results (knowledge) of data mining in crop farming to build, maintain, and enrich the process of knowledge discovery. The proposed model consists of six main sets: concepts, attributes, relations, transformations, instances, and states. This model is dynamic and facilitates the access, updates, and exploitation of the knowledge at any time. This paper also proposes an architecture for handling this knowledge-based model. The system architecture includes knowledge modelling, extraction, assessment, publishing, and exploitation. This system has been implemented and used in agriculture for crop management and monitoring. It is proven to be very effective and promising for its extension to other domains.
OAK: Ontology-Based Knowledge Map Model for Digital Agriculture
Nov 20, 2020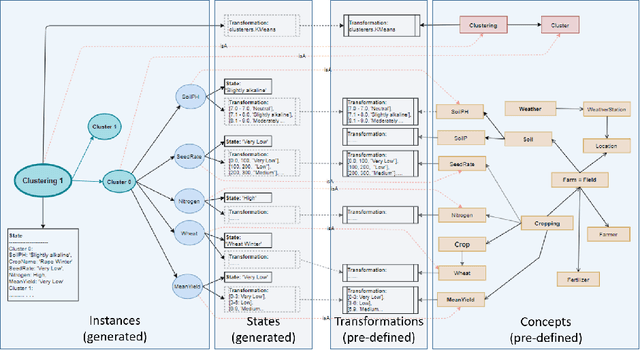
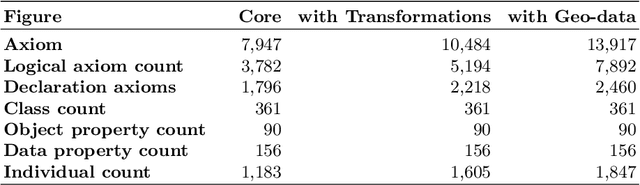
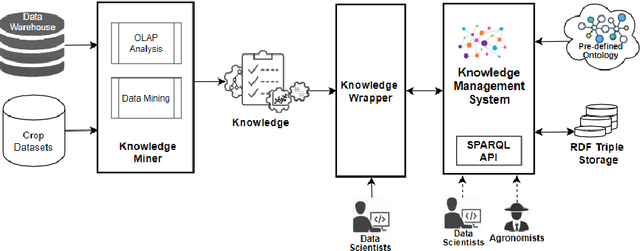
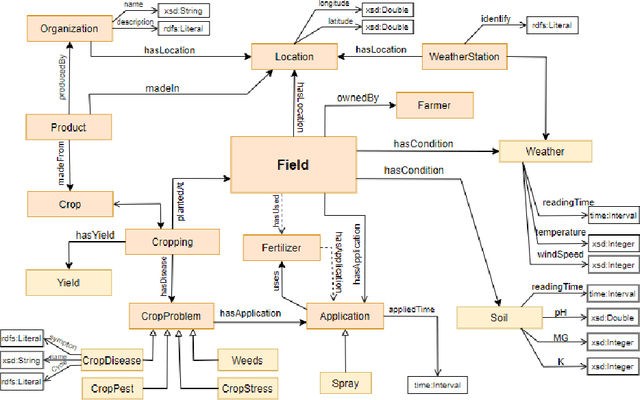
Nowadays, a huge amount of knowledge has been amassed in digital agriculture. This knowledge and know-how information are collected from various sources, hence the question is how to organise this knowledge so that it can be efficiently exploited. Although this knowledge about agriculture practices can be represented using ontology, rule-based expert systems, or knowledge model built from data mining processes, the scalability still remains an open issue. In this study, we propose a knowledge representation model, called an ontology-based knowledge map, which can collect knowledge from different sources, store it, and exploit either directly by stakeholders or as an input to the knowledge discovery process (Data Mining). The proposed model consists of two stages, 1) build an ontology as a knowledge base for a specific domain and data mining concepts, and 2) build the ontology-based knowledge map model for representing and storing the knowledge mined on the crop datasets. A framework of the proposed model has been implemented in agriculture domain. It is an efficient and scalable model, and it can be used as knowledge repository a digital agriculture.
Predicting Soil pH by Using Nearest Fields
Dec 03, 2019
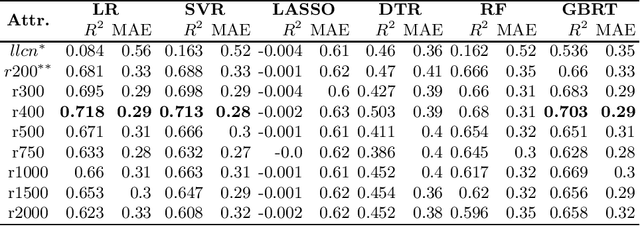
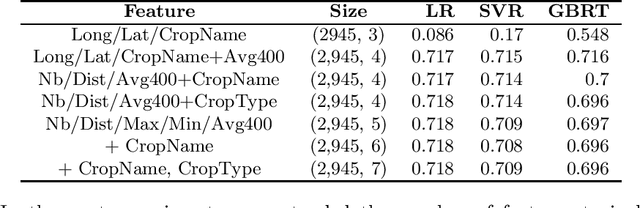

In precision agriculture (PA), soil sampling and testing operation is prior to planting any new crop. It is an expensive operation since there are many soil characteristics to take into account. This paper gives an overview of soil characteristics and their relationships with crop yield and soil profiling. We propose an approach for predicting soil pH based on nearest neighbour fields. It implements spatial radius queries and various regression techniques in data mining. We use soil dataset containing about 4,000 fields profiles to evaluate them and analyse their robustness. A comparative study indicates that LR, SVR, and GBRT techniques achieved high accuracy, with the R_2 values of about 0.718 and MAE values of 0.29. The experimental results showed that the proposed approach is very promising and can contribute significantly to PA.
Human Activity Recognition with Convolutional Neural Netowrks
Jun 05, 2019
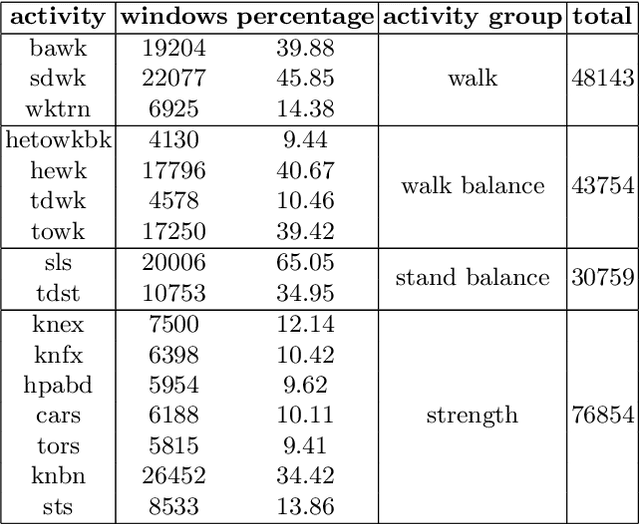

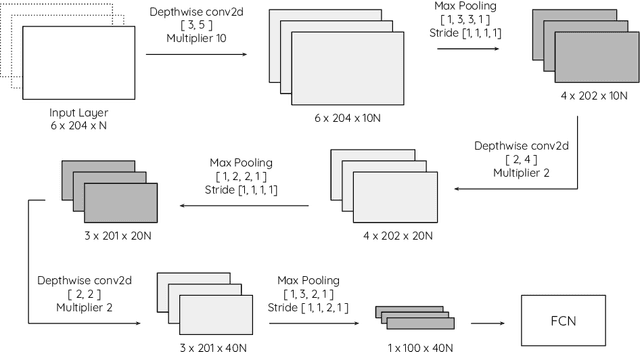
The problem of automatic identification of physical activities performed by human subjects is referred to as Human Activity Recognition (HAR). There exist several techniques to measure motion characteristics during these physical activities, such as Inertial Measurement Units (IMUs). IMUs have a cornerstone position in this context, and are characterized by usage flexibility, low cost, and reduced privacy impact. With the use of inertial sensors, it is possible to sample some measures such as acceleration and angular velocity of a body, and use them to learn models that are capable of correctly classifying activities to their corresponding classes. In this paper, we propose to use Convolutional Neural Networks (CNNs) to classify human activities. Our models use raw data obtained from a set of inertial sensors. We explore several combinations of activities and sensors, showing how motion signals can be adapted to be fed into CNNs by using different network architectures. We also compare the performance of different groups of sensors, investigating the classification potential of single, double and triple sensor systems. The experimental results obtained on a dataset of 16 lower-limb activities, collected from a group of participants with the use of five different sensors, are very promising.
DIALOG: A framework for modeling, analysis and reuse of digital forensic knowledge
Feb 21, 2019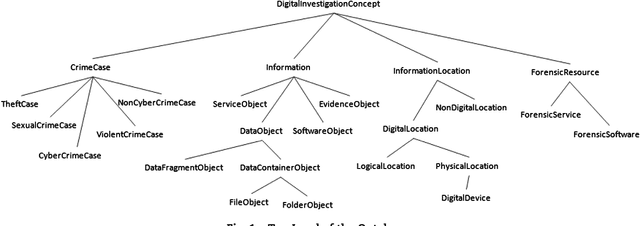
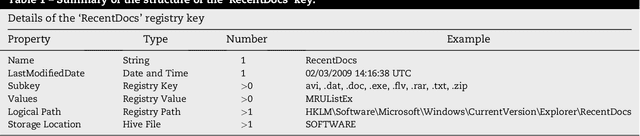

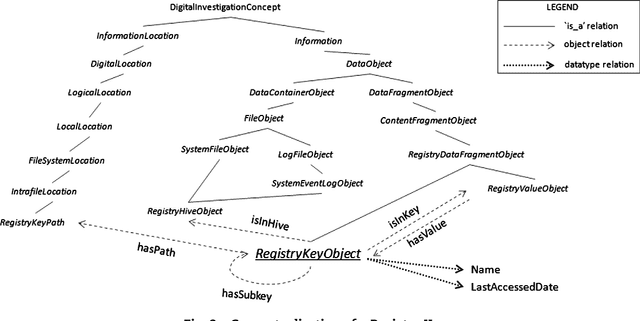
This paper presents DIALOG (Digital Investigation Ontology); a framework for the management, reuse, and analysis of Digital Investigation knowledge. DIALOG provides a general, application independent vocabulary that can be used to describe an investigation at different levels of detail. DIALOG is defined to encapsulate all concepts of the digital forensics field and the relationships between them. In particular, we concentrate on the Windows Registry, where registry keys are modeled in terms of both their structure and function. Registry analysis software tools are modeled in a similar manner and we illustrate how the interpretation of their results can be done using the reasoning capabilities of ontology
A complete formalized knowledge representation model for advanced digital forensics timeline analysis
Feb 21, 2019
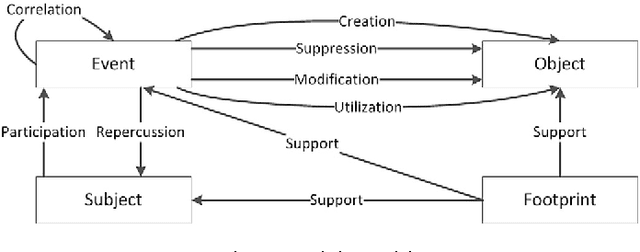
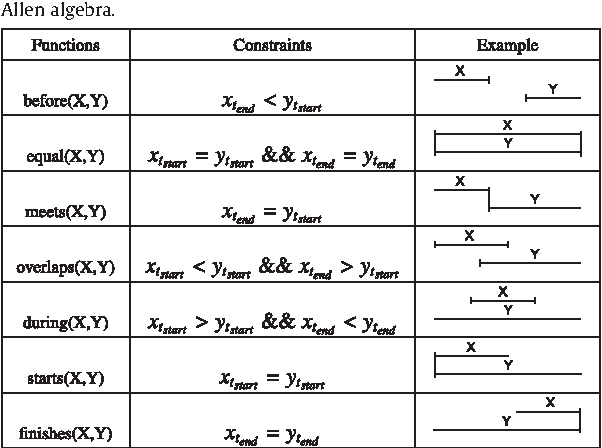
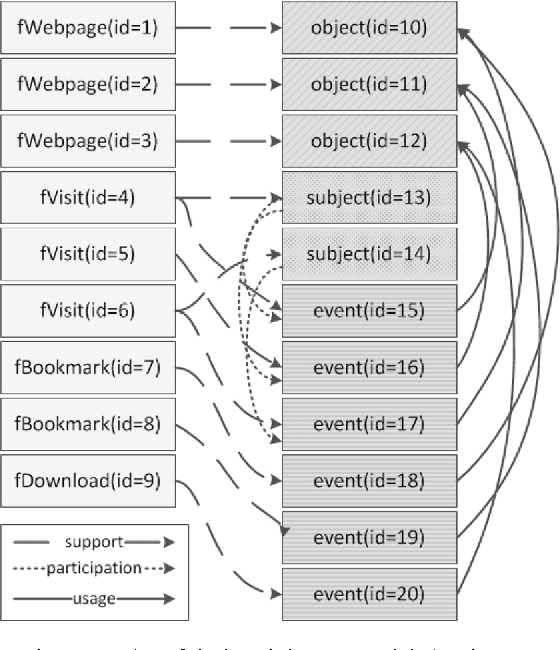
Having a clear view of events that occurred over time is a difficult objective to achieve in digital investigations (DI). Event reconstruction, which allows investigators to understand the timeline of a crime, is one of the most important step of a DI process. This complex task requires exploration of a large amount of events due to the pervasiveness of new technologies nowadays. Any evidence produced at the end of the investigative process must also meet the requirements of the courts, such as reproducibility, verifiability, validation, etc. For this purpose, we propose a new methodology, supported by theoretical concepts, that can assist investigators through the whole process including the construction and the interpretation of the events describing the case. The proposed approach is based on a model which integrates knowledge of experts from the fields of digital forensics and software development to allow a semantically rich representation of events related to the incident. The main purpose of this model is to allow the analysis of these events in an automatic and efficient way. This paper describes the approach and then focuses on the main conceptual and formal aspects: a formal incident modelization and operators for timeline reconstruction and analysis.
Automatic Classification of Knee Rehabilitation Exercises Using a Single Inertial Sensor: a Case Study
Dec 10, 2018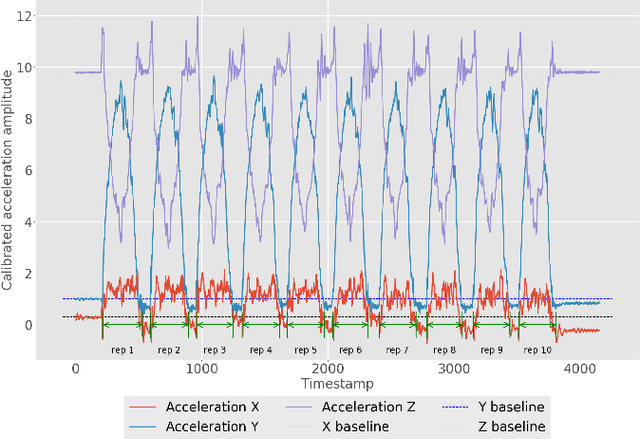
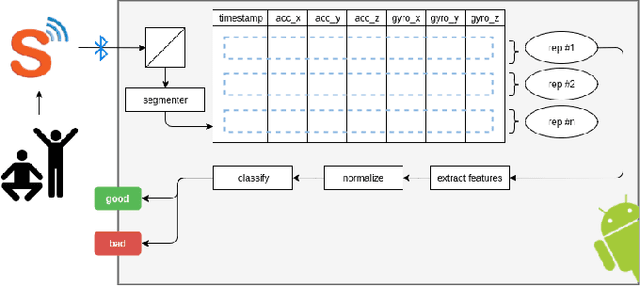
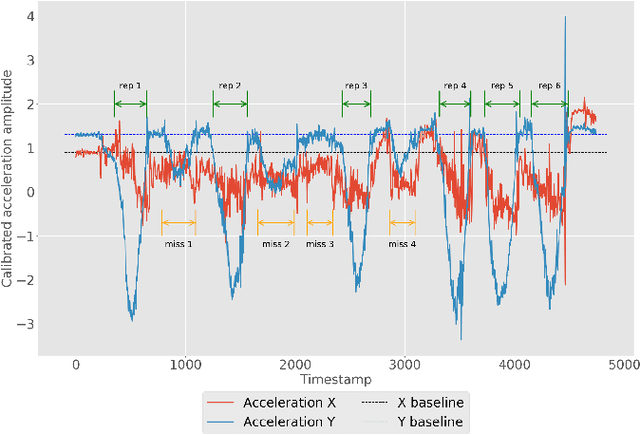
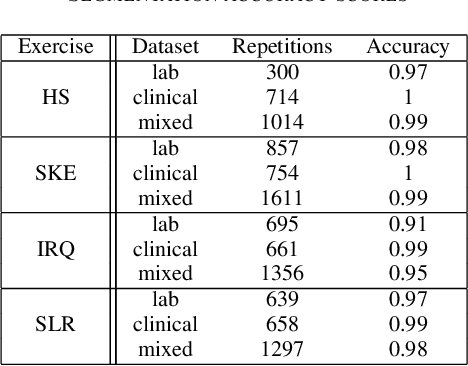
Inertial measurement units have the ability to accurately record the acceleration and angular velocity of human limb segments during discrete joint movements. These movements are commonly used in exercise rehabilitation programmes following orthopaedic surgery such as total knee replacement. This provides the potential for a biofeedback system with data mining technique for patients undertaking exercises at home without physician supervision. We propose to use machine learning techniques to automatically analyse inertial measurement unit data collected during these exercises, and then assess whether each repetition of the exercise was executed correctly or not. Our approach consists of two main phases: signal segmentation, and segment classification. Accurate pre-processing and feature extraction are paramount topics in order for the technique to work. In this paper, we present a classification method for unsupervised rehabilitation exercises, based on a segmentation process that extracts repetitions from a longer signal activity. The results obtained from experimental datasets of both clinical and healthy subjects, for a set of 4 knee exercises commonly used in rehabilitation, are very promising.