 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOntology-based Solution for Building an Intelligent Searching System on Traffic Law Documents
Jan 26, 2023



In this paper, an ontology-based approach is used to organize the knowledge base of legal documents in road traffic law. This knowledge model is built by the improvement of ontology Rela-model. In addition, several searching problems on traffic law are proposed and solved based on the legal knowledge base. The intelligent search system on Vietnam road traffic law is constructed by applying the method. The searching system can help users to find concepts and definitions in road traffic law. Moreover, it can also determine penalties and fines for violations in the traffic. The experiment results show that the system is efficient for users' typical searching and is emerging for usage in the real-world.
OAK4XAI: Model towards Out-Of-Box eXplainable Artificial Intelligence for Digital Agriculture
Sep 29, 2022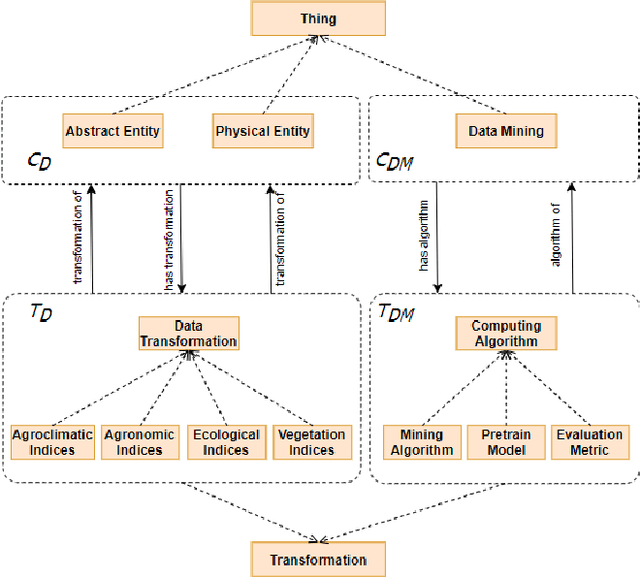

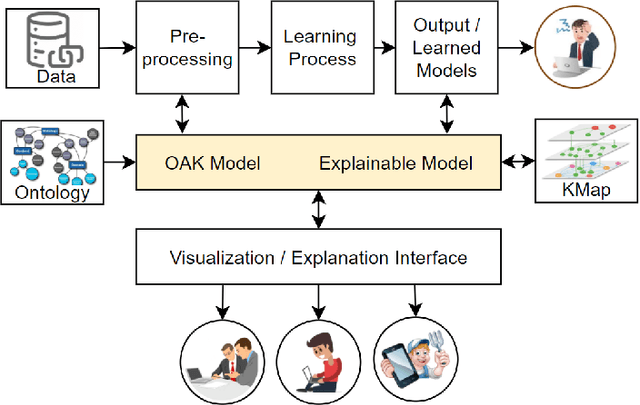
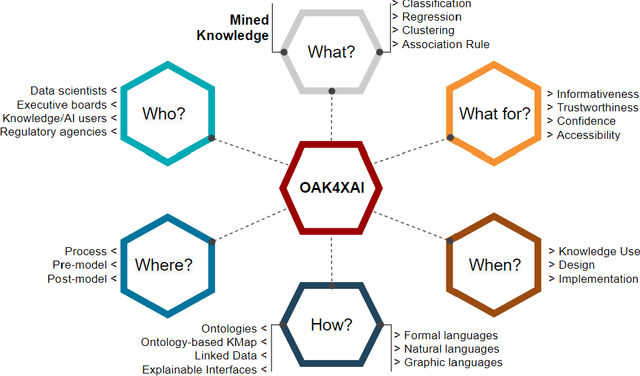
Recent machine learning approaches have been effective in Artificial Intelligence (AI) applications. They produce robust results with a high level of accuracy. However, most of these techniques do not provide human-understandable explanations for supporting their results and decisions. They usually act as black boxes, and it is not easy to understand how decisions have been made. Explainable Artificial Intelligence (XAI), which has received much interest recently, tries to provide human-understandable explanations for decision-making and trained AI models. For instance, in digital agriculture, related domains often present peculiar or input features with no link to background knowledge. The application of the data mining process on agricultural data leads to results (knowledge), which are difficult to explain. In this paper, we propose a knowledge map model and an ontology design as an XAI framework (OAK4XAI) to deal with this issue. The framework does not only consider the data analysis part of the process, but it takes into account the semantics aspect of the domain knowledge via an ontology and a knowledge map model, provided as modules of the framework. Many ongoing XAI studies aim to provide accurate and verbalizable accounts for how given feature values contribute to model decisions. The proposed approach, however, focuses on providing consistent information and definitions of concepts, algorithms, and values involved in the data mining models. We built an Agriculture Computing Ontology (AgriComO) to explain the knowledge mined in agriculture. AgriComO has a well-designed structure and includes a wide range of concepts and transformations suitable for agriculture and computing domains.
Knowledge Representation in Digital Agriculture: A Step Towards Standardised Model
Jul 15, 2022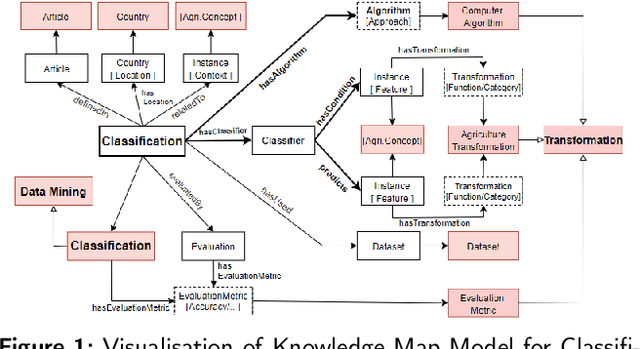
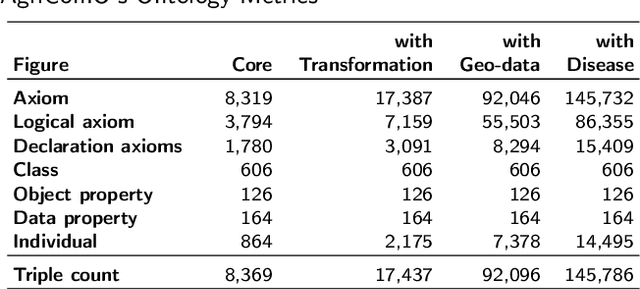
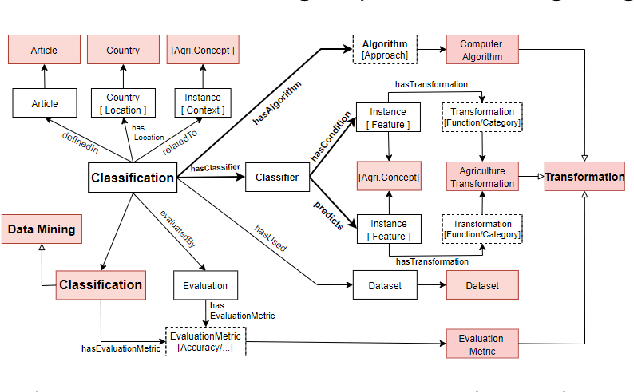

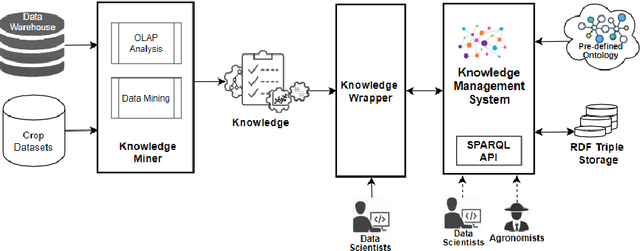
In recent years, data science has evolved significantly. Data analysis and mining processes become routines in all sectors of the economy where datasets are available. Vast data repositories have been collected, curated, stored, and used for extracting knowledge. And this is becoming commonplace. Subsequently, we extract a large amount of knowledge, either directly from the data or through experts in the given domain. The challenge now is how to exploit all this large amount of knowledge that is previously known for efficient decision-making processes. Until recently, much of the knowledge gained through a number of years of research is stored in static knowledge bases or ontologies, while more diverse and dynamic knowledge acquired from data mining studies is not centrally and consistently managed. In this research, we propose a novel model called ontology-based knowledge map to represent and store the results (knowledge) of data mining in crop farming to build, maintain, and enrich the process of knowledge discovery. The proposed model consists of six main sets: concepts, attributes, relations, transformations, instances, and states. This model is dynamic and facilitates the access, updates, and exploitation of the knowledge at any time. This paper also proposes an architecture for handling this knowledge-based model. The system architecture includes knowledge modelling, extraction, assessment, publishing, and exploitation. This system has been implemented and used in agriculture for crop management and monitoring. It is proven to be very effective and promising for its extension to other domains.
Fine-Tuning BERT for Sentiment Analysis of Vietnamese Reviews
Nov 20, 2020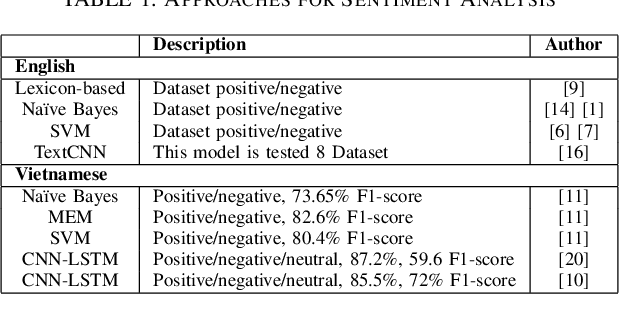
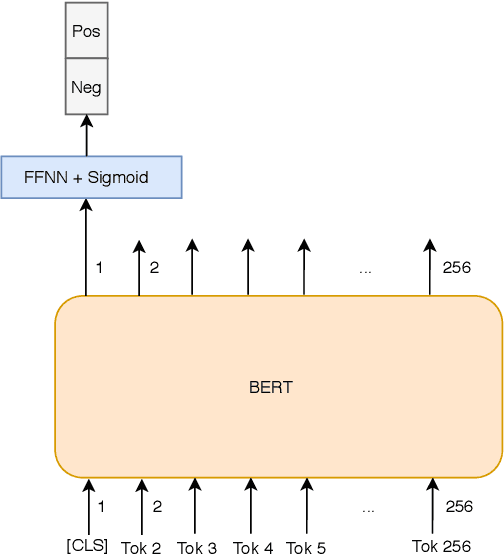

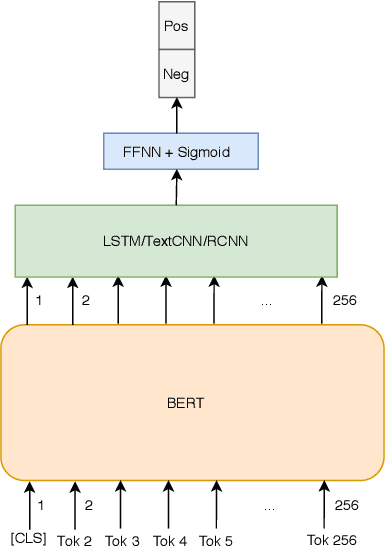
Sentiment analysis is an important task in the field ofNature Language Processing (NLP), in which users' feedbackdata on a specific issue are evaluated and analyzed. Manydeep learning models have been proposed to tackle this task, including the recently-introduced Bidirectional Encoder Rep-resentations from Transformers (BERT) model. In this paper,we experiment with two BERT fine-tuning methods for thesentiment analysis task on datasets of Vietnamese reviews: 1) a method that uses only the [CLS] token as the input for anattached feed-forward neural network, and 2) another methodin which all BERT output vectors are used as the input forclassification. Experimental results on two datasets show thatmodels using BERT slightly outperform other models usingGloVe and FastText. Also, regarding the datasets employed inthis study, our proposed BERT fine-tuning method produces amodel with better performance than the original BERT fine-tuning method.
OAK: Ontology-Based Knowledge Map Model for Digital Agriculture
Nov 20, 2020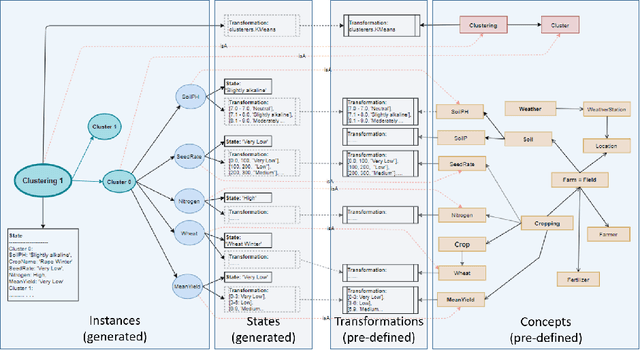
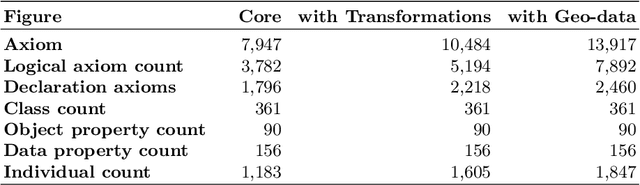
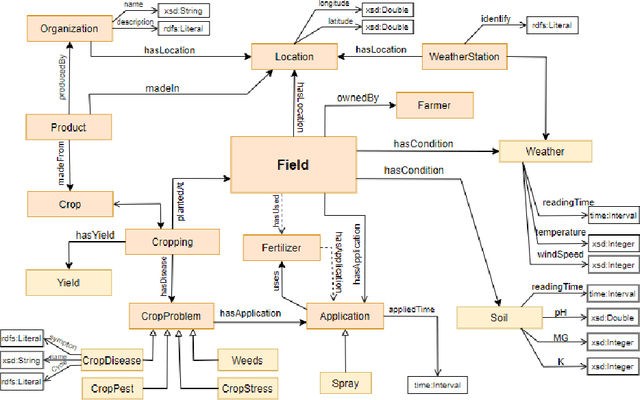
Nowadays, a huge amount of knowledge has been amassed in digital agriculture. This knowledge and know-how information are collected from various sources, hence the question is how to organise this knowledge so that it can be efficiently exploited. Although this knowledge about agriculture practices can be represented using ontology, rule-based expert systems, or knowledge model built from data mining processes, the scalability still remains an open issue. In this study, we propose a knowledge representation model, called an ontology-based knowledge map, which can collect knowledge from different sources, store it, and exploit either directly by stakeholders or as an input to the knowledge discovery process (Data Mining). The proposed model consists of two stages, 1) build an ontology as a knowledge base for a specific domain and data mining concepts, and 2) build the ontology-based knowledge map model for representing and storing the knowledge mined on the crop datasets. A framework of the proposed model has been implemented in agriculture domain. It is an efficient and scalable model, and it can be used as knowledge repository a digital agriculture.
Predicting Soil pH by Using Nearest Fields
Dec 03, 2019
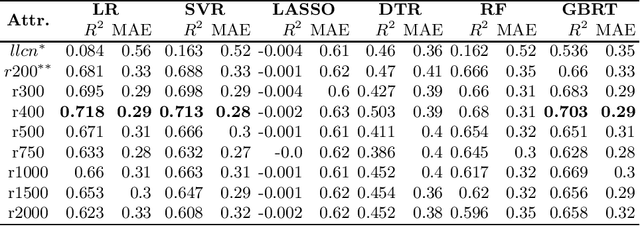
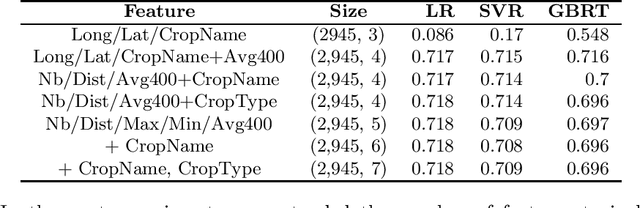

In precision agriculture (PA), soil sampling and testing operation is prior to planting any new crop. It is an expensive operation since there are many soil characteristics to take into account. This paper gives an overview of soil characteristics and their relationships with crop yield and soil profiling. We propose an approach for predicting soil pH based on nearest neighbour fields. It implements spatial radius queries and various regression techniques in data mining. We use soil dataset containing about 4,000 fields profiles to evaluate them and analyse their robustness. A comparative study indicates that LR, SVR, and GBRT techniques achieved high accuracy, with the R_2 values of about 0.718 and MAE values of 0.29. The experimental results showed that the proposed approach is very promising and can contribute significantly to PA.
State-of-the-Art Vietnamese Word Segmentation
Jun 18, 2019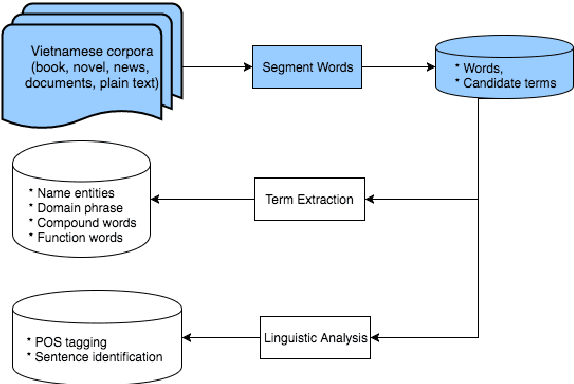
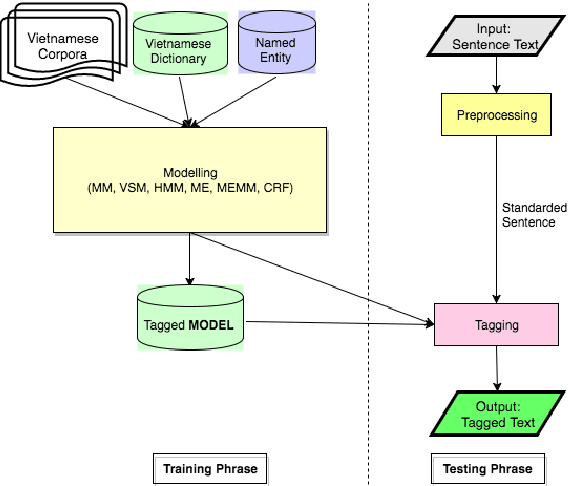
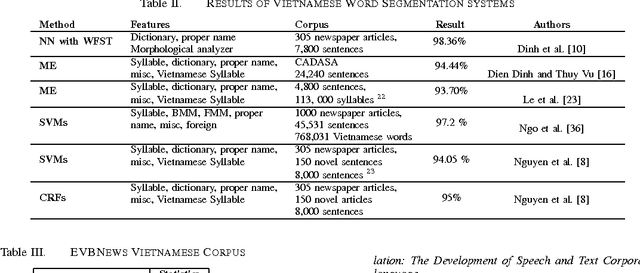
Word segmentation is the first step of any tasks in Vietnamese language processing. This paper reviews stateof-the-art approaches and systems for word segmentation in Vietnamese. To have an overview of all stages from building corpora to developing toolkits, we discuss building the corpus stage, approaches applied to solve the word segmentation and existing toolkits to segment words in Vietnamese sentences. In addition, this study shows clearly the motivations on building corpus and implementing machine learning techniques to improve the accuracy for Vietnamese word segmentation. According to our observation, this study also reports a few of achivements and limitations in existing Vietnamese word segmentation systems.