 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficacy of Neural Prediction-Based Zero-Shot NAS
Sep 22, 2023



In prediction-based Neural Architecture Search (NAS), performance indicators derived from graph convolutional networks have shown remarkable success. These indicators, achieved by representing feed-forward structures as component graphs through one-hot encoding, face a limitation: their inability to evaluate architecture performance across varying search spaces. In contrast, handcrafted performance indicators (zero-shot NAS), which use the same architecture with random initialization, can generalize across multiple search spaces. Addressing this limitation, we propose a novel approach for zero-shot NAS using deep learning. Our method employs Fourier sum of sines encoding for convolutional kernels, enabling the construction of a computational feed-forward graph with a structure similar to the architecture under evaluation. These encodings are learnable and offer a comprehensive view of the architecture's topological information. An accompanying multi-layer perceptron (MLP) then ranks these architectures based on their encodings. Experimental results show that our approach surpasses previous methods using graph convolutional networks in terms of correlation on the NAS-Bench-201 dataset and exhibits a higher convergence rate. Moreover, our extracted feature representation trained on each NAS benchmark is transferable to other NAS benchmarks, showing promising generalizability across multiple search spaces. The code is available at: https://github.com/minh1409/DFT-NPZS-NAS
Fine-Tuning BERT for Sentiment Analysis of Vietnamese Reviews
Nov 20, 2020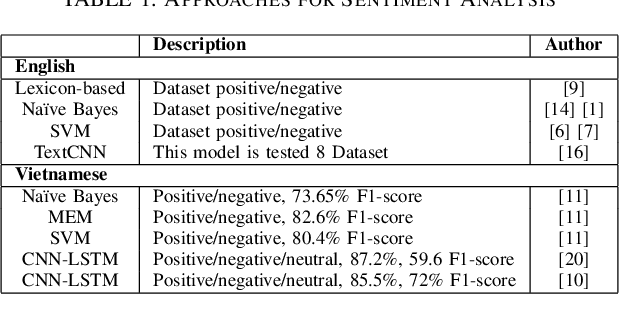
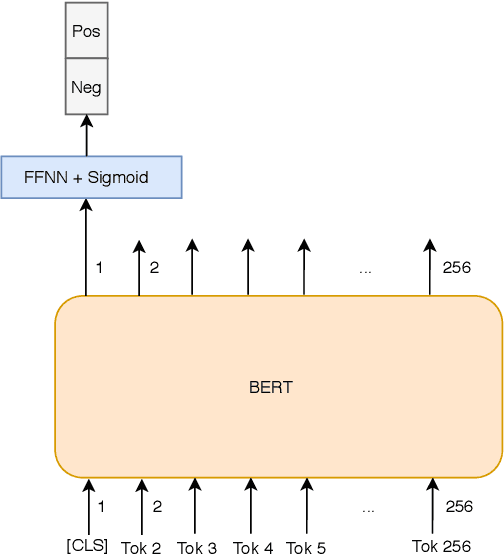

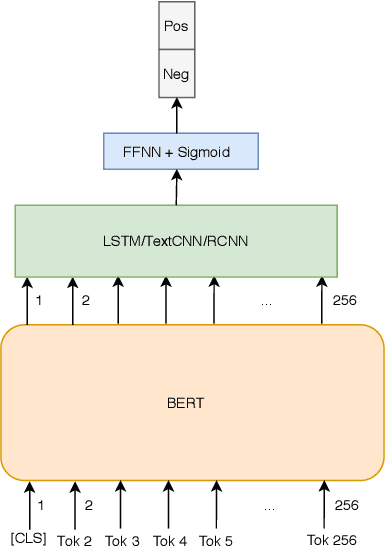
Sentiment analysis is an important task in the field ofNature Language Processing (NLP), in which users' feedbackdata on a specific issue are evaluated and analyzed. Manydeep learning models have been proposed to tackle this task, including the recently-introduced Bidirectional Encoder Rep-resentations from Transformers (BERT) model. In this paper,we experiment with two BERT fine-tuning methods for thesentiment analysis task on datasets of Vietnamese reviews: 1) a method that uses only the [CLS] token as the input for anattached feed-forward neural network, and 2) another methodin which all BERT output vectors are used as the input forclassification. Experimental results on two datasets show thatmodels using BERT slightly outperform other models usingGloVe and FastText. Also, regarding the datasets employed inthis study, our proposed BERT fine-tuning method produces amodel with better performance than the original BERT fine-tuning method.