 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerifying Local Robustness of Pruned Safety-Critical Networks
Jan 19, 2026Formal verification of Deep Neural Networks (DNNs) is essential for safety-critical applications, ranging from surgical robotics to NASA JPL autonomous systems. However, the computational cost of verifying large-scale models remains a significant barrier to adoption. This paper investigates the impact of pruning on formal local robustness certificates with different ratios. Using the state-of-the-art $α,β$-CROWN verifier, we evaluate ResNet4 models across varying pruning ratios on MNIST and, more importantly, on the NASA JPL Mars Frost Identification datasets. Our findings demonstrate a non-linear relationship: light pruning (40%) in MNIST and heavy pruning (70%-90%) in JPL improve verifiability, allowing models to outperform unpruned baselines in proven $L_\infty$ robustness properties. This suggests that reduced connectivity simplifies the search space for formal solvers and that the optimal pruning ratio varies significantly between datasets. This research highlights the complex nature of model compression, offering critical insights into selecting the optimal pruning ratio for deploying efficient, yet formally verified, DNNs in high-stakes environments where reliability is non-negotiable.
Towards Rehearsal-Free Continual Relation Extraction: Capturing Within-Task Variance with Adaptive Prompting
May 20, 2025Memory-based approaches have shown strong performance in Continual Relation Extraction (CRE). However, storing examples from previous tasks increases memory usage and raises privacy concerns. Recently, prompt-based methods have emerged as a promising alternative, as they do not rely on storing past samples. Despite this progress, current prompt-based techniques face several core challenges in CRE, particularly in accurately identifying task identities and mitigating catastrophic forgetting. Existing prompt selection strategies often suffer from inaccuracies, lack robust mechanisms to prevent forgetting in shared parameters, and struggle to handle both cross-task and within-task variations. In this paper, we propose WAVE++, a novel approach inspired by the connection between prefix-tuning and mixture of experts. Specifically, we introduce task-specific prompt pools that enhance flexibility and adaptability across diverse tasks while avoiding boundary-spanning risks; this design more effectively captures variations within each task and across tasks. To further refine relation classification, we incorporate label descriptions that provide richer, more global context, enabling the model to better distinguish among different relations. We also propose a training-free mechanism to improve task prediction during inference. Moreover, we integrate a generative model to consolidate prior knowledge within the shared parameters, thereby removing the need for explicit data storage. Extensive experiments demonstrate that WAVE++ outperforms state-of-the-art prompt-based and rehearsal-based methods, offering a more robust solution for continual relation extraction. Our code is publicly available at https://github.com/PiDinosauR2804/WAVE-CRE-PLUS-PLUS.
RepLoRA: Reparameterizing Low-Rank Adaptation via the Perspective of Mixture of Experts
Feb 05, 2025Low-rank adaptation (LoRA) has emerged as a powerful method for fine-tuning large-scale foundation models. Despite its popularity, the theoretical understanding of LoRA has remained limited. This paper presents a theoretical analysis of LoRA by examining its connection to the Mixture of Experts models. Under this framework, we show that simple reparameterizations of the LoRA matrices can notably accelerate the low-rank matrix estimation process. In particular, we prove that reparameterization can reduce the data needed to achieve a desired estimation error from an exponential to a polynomial scale. Motivated by this insight, we propose Reparameterized Low-rank Adaptation (RepLoRA), which incorporates lightweight MLPs to reparameterize the LoRA matrices. Extensive experiments across multiple domains demonstrate that RepLoRA consistently outperforms vanilla LoRA. Notably, with limited data, RepLoRA surpasses LoRA by a margin of up to 40.0% and achieves LoRA's performance with only 30.0% of the training data, highlighting both the theoretical and empirical robustness of our PEFT method.
On Zero-Initialized Attention: Optimal Prompt and Gating Factor Estimation
Feb 05, 2025



The LLaMA-Adapter has recently emerged as an efficient fine-tuning technique for LLaMA models, leveraging zero-initialized attention to stabilize training and enhance performance. However, despite its empirical success, the theoretical foundations of zero-initialized attention remain largely unexplored. In this paper, we provide a rigorous theoretical analysis, establishing a connection between zero-initialized attention and mixture-of-expert models. We prove that both linear and non-linear prompts, along with gating functions, can be optimally estimated, with non-linear prompts offering greater flexibility for future applications. Empirically, we validate our findings on the open LLM benchmarks, demonstrating that non-linear prompts outperform linear ones. Notably, even with limited training data, both prompt types consistently surpass vanilla attention, highlighting the robustness and adaptability of zero-initialized attention.
Adaptive Prompt: Unlocking the Power of Visual Prompt Tuning
Jan 31, 2025



Visual Prompt Tuning (VPT) has recently emerged as a powerful method for adapting pre-trained vision models to downstream tasks. By introducing learnable prompt tokens as task-specific instructions, VPT effectively guides pre-trained transformer models with minimal overhead. Despite its empirical success, a comprehensive theoretical understanding of VPT remains an active area of research. Building on recent insights into the connection between mixture of experts and prompt-based approaches, we identify a key limitation in VPT: the restricted functional expressiveness in prompt formulation. To address this limitation, we propose Visual Adaptive Prompt Tuning (VAPT), a new generation of prompts that redefines prompts as adaptive functions of the input. Our theoretical analysis shows that this simple yet intuitive approach achieves optimal sample efficiency. Empirical results on VTAB-1K and FGVC further demonstrate VAPT's effectiveness, with performance gains of 7.34% and 1.04% over fully fine-tuning baselines, respectively. Notably, VAPT also surpasses VPT by a substantial margin while using fewer parameters. These results highlight both the effectiveness and efficiency of our method and pave the way for future research to explore the potential of adaptive prompts.
Adaptive Prompting for Continual Relation Extraction: A Within-Task Variance Perspective
Dec 12, 2024



To address catastrophic forgetting in Continual Relation Extraction (CRE), many current approaches rely on memory buffers to rehearse previously learned knowledge while acquiring new tasks. Recently, prompt-based methods have emerged as potent alternatives to rehearsal-based strategies, demonstrating strong empirical performance. However, upon analyzing existing prompt-based approaches for CRE, we identified several critical limitations, such as inaccurate prompt selection, inadequate mechanisms for mitigating forgetting in shared parameters, and suboptimal handling of cross-task and within-task variances. To overcome these challenges, we draw inspiration from the relationship between prefix-tuning and mixture of experts, proposing a novel approach that employs a prompt pool for each task, capturing variations within each task while enhancing cross-task variances. Furthermore, we incorporate a generative model to consolidate prior knowledge within shared parameters, eliminating the need for explicit data storage. Extensive experiments validate the efficacy of our approach, demonstrating superior performance over state-of-the-art prompt-based and rehearsal-free methods in continual relation extraction.
Leveraging Hierarchical Taxonomies in Prompt-based Continual Learning
Oct 06, 2024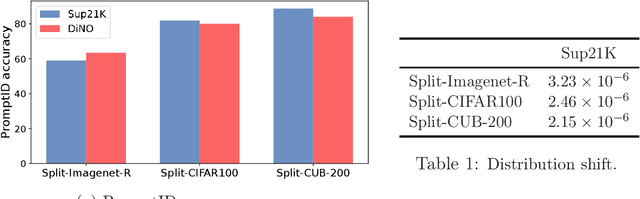
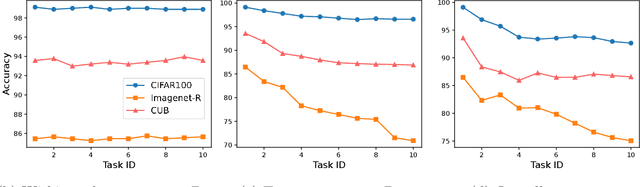
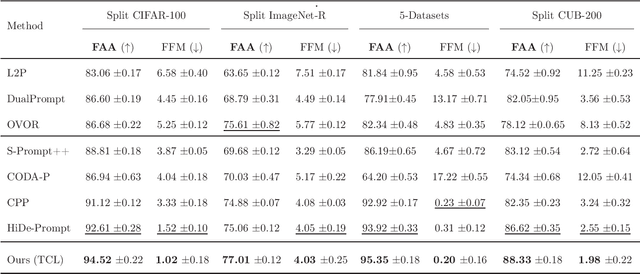
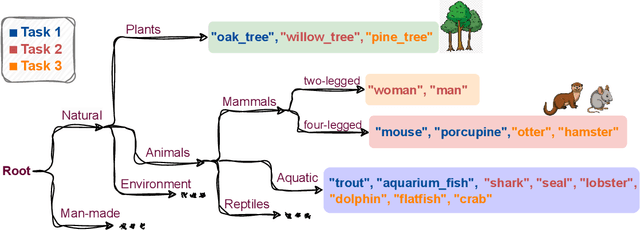
Drawing inspiration from human learning behaviors, this work proposes a novel approach to mitigate catastrophic forgetting in Prompt-based Continual Learning models by exploiting the relationships between continuously emerging class data. We find that applying human habits of organizing and connecting information can serve as an efficient strategy when training deep learning models. Specifically, by building a hierarchical tree structure based on the expanding set of labels, we gain fresh insights into the data, identifying groups of similar classes could easily cause confusion. Additionally, we delve deeper into the hidden connections between classes by exploring the original pretrained model's behavior through an optimal transport-based approach. From these insights, we propose a novel regularization loss function that encourages models to focus more on challenging knowledge areas, thereby enhancing overall performance. Experimentally, our method demonstrated significant superiority over the most robust state-of-the-art models on various benchmarks.
Revisiting Prefix-tuning: Statistical Benefits of Reparameterization among Prompts
Oct 03, 2024



Prompt-based techniques, such as prompt-tuning and prefix-tuning, have gained prominence for their efficiency in fine-tuning large pre-trained models. Despite their widespread adoption, the theoretical foundations of these methods remain limited. For instance, in prefix-tuning, we observe that a key factor in achieving performance parity with full fine-tuning lies in the reparameterization strategy. However, the theoretical principles underpinning the effectiveness of this approach have yet to be thoroughly examined. Our study demonstrates that reparameterization is not merely an engineering trick but is grounded in deep theoretical foundations. Specifically, we show that the reparameterization strategy implicitly encodes a shared structure between prefix key and value vectors. Building on recent insights into the connection between prefix-tuning and mixture of experts models, we further illustrate that this shared structure significantly improves sample efficiency in parameter estimation compared to non-shared alternatives. The effectiveness of prefix-tuning across diverse tasks is empirically confirmed to be enhanced by the shared structure, through extensive experiments in both visual and language domains. Additionally, we uncover similar structural benefits in prompt-tuning, offering new perspectives on its success. Our findings provide theoretical and empirical contributions, advancing the understanding of prompt-based methods and their underlying mechanisms.
Mixture of Experts Meets Prompt-Based Continual Learning
May 23, 2024Exploiting the power of pre-trained models, prompt-based approaches stand out compared to other continual learning solutions in effectively preventing catastrophic forgetting, even with very few learnable parameters and without the need for a memory buffer. While existing prompt-based continual learning methods excel in leveraging prompts for state-of-the-art performance, they often lack a theoretical explanation for the effectiveness of prompting. This paper conducts a theoretical analysis to unravel how prompts bestow such advantages in continual learning, thus offering a new perspective on prompt design. We first show that the attention block of pre-trained models like Vision Transformers inherently encodes a special mixture of experts architecture, characterized by linear experts and quadratic gating score functions. This realization drives us to provide a novel view on prefix tuning, reframing it as the addition of new task-specific experts, thereby inspiring the design of a novel gating mechanism termed Non-linear Residual Gates (NoRGa). Through the incorporation of non-linear activation and residual connection, NoRGa enhances continual learning performance while preserving parameter efficiency. The effectiveness of NoRGa is substantiated both theoretically and empirically across diverse benchmarks and pretraining paradigms.
Efficacy of Neural Prediction-Based Zero-Shot NAS
Sep 22, 2023



In prediction-based Neural Architecture Search (NAS), performance indicators derived from graph convolutional networks have shown remarkable success. These indicators, achieved by representing feed-forward structures as component graphs through one-hot encoding, face a limitation: their inability to evaluate architecture performance across varying search spaces. In contrast, handcrafted performance indicators (zero-shot NAS), which use the same architecture with random initialization, can generalize across multiple search spaces. Addressing this limitation, we propose a novel approach for zero-shot NAS using deep learning. Our method employs Fourier sum of sines encoding for convolutional kernels, enabling the construction of a computational feed-forward graph with a structure similar to the architecture under evaluation. These encodings are learnable and offer a comprehensive view of the architecture's topological information. An accompanying multi-layer perceptron (MLP) then ranks these architectures based on their encodings. Experimental results show that our approach surpasses previous methods using graph convolutional networks in terms of correlation on the NAS-Bench-201 dataset and exhibits a higher convergence rate. Moreover, our extracted feature representation trained on each NAS benchmark is transferable to other NAS benchmarks, showing promising generalizability across multiple search spaces. The code is available at: https://github.com/minh1409/DFT-NPZS-NAS