 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTED++: Submanifold-Aware Backdoor Detection via Layerwise Tubular-Neighbourhood Screening
Oct 16, 2025As deep neural networks power increasingly critical applications, stealthy backdoor attacks, where poisoned training inputs trigger malicious model behaviour while appearing benign, pose a severe security risk. Many existing defences are vulnerable when attackers exploit subtle distance-based anomalies or when clean examples are scarce. To meet this challenge, we introduce TED++, a submanifold-aware framework that effectively detects subtle backdoors that evade existing defences. TED++ begins by constructing a tubular neighbourhood around each class's hidden-feature manifold, estimating its local ``thickness'' from a handful of clean activations. It then applies Locally Adaptive Ranking (LAR) to detect any activation that drifts outside the admissible tube. By aggregating these LAR-adjusted ranks across all layers, TED++ captures how faithfully an input remains on the evolving class submanifolds. Based on such characteristic ``tube-constrained'' behaviour, TED++ flags inputs whose LAR-based ranking sequences deviate significantly. Extensive experiments are conducted on benchmark datasets and tasks, demonstrating that TED++ achieves state-of-the-art detection performance under both adaptive-attack and limited-data scenarios. Remarkably, even with only five held-out examples per class, TED++ still delivers near-perfect detection, achieving gains of up to 14\% in AUROC over the next-best method. The code is publicly available at https://github.com/namle-w/TEDpp.
Towards Rehearsal-Free Continual Relation Extraction: Capturing Within-Task Variance with Adaptive Prompting
May 20, 2025Memory-based approaches have shown strong performance in Continual Relation Extraction (CRE). However, storing examples from previous tasks increases memory usage and raises privacy concerns. Recently, prompt-based methods have emerged as a promising alternative, as they do not rely on storing past samples. Despite this progress, current prompt-based techniques face several core challenges in CRE, particularly in accurately identifying task identities and mitigating catastrophic forgetting. Existing prompt selection strategies often suffer from inaccuracies, lack robust mechanisms to prevent forgetting in shared parameters, and struggle to handle both cross-task and within-task variations. In this paper, we propose WAVE++, a novel approach inspired by the connection between prefix-tuning and mixture of experts. Specifically, we introduce task-specific prompt pools that enhance flexibility and adaptability across diverse tasks while avoiding boundary-spanning risks; this design more effectively captures variations within each task and across tasks. To further refine relation classification, we incorporate label descriptions that provide richer, more global context, enabling the model to better distinguish among different relations. We also propose a training-free mechanism to improve task prediction during inference. Moreover, we integrate a generative model to consolidate prior knowledge within the shared parameters, thereby removing the need for explicit data storage. Extensive experiments demonstrate that WAVE++ outperforms state-of-the-art prompt-based and rehearsal-based methods, offering a more robust solution for continual relation extraction. Our code is publicly available at https://github.com/PiDinosauR2804/WAVE-CRE-PLUS-PLUS.
From Visual Explanations to Counterfactual Explanations with Latent Diffusion
Apr 12, 2025Visual counterfactual explanations are ideal hypothetical images that change the decision-making of the classifier with high confidence toward the desired class while remaining visually plausible and close to the initial image. In this paper, we propose a new approach to tackle two key challenges in recent prominent works: i) determining which specific counterfactual features are crucial for distinguishing the "concept" of the target class from the original class, and ii) supplying valuable explanations for the non-robust classifier without relying on the support of an adversarially robust model. Our method identifies the essential region for modification through algorithms that provide visual explanations, and then our framework generates realistic counterfactual explanations by combining adversarial attacks based on pruning the adversarial gradient of the target classifier and the latent diffusion model. The proposed method outperforms previous state-of-the-art results on various evaluation criteria on ImageNet and CelebA-HQ datasets. In general, our method can be applied to arbitrary classifiers, highlight the strong association between visual and counterfactual explanations, make semantically meaningful changes from the target classifier, and provide observers with subtle counterfactual images.
* 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Competitive Learning for Achieving Content-specific Filters in Video Coding for Machines
Jun 18, 2024This paper investigates the efficacy of jointly optimizing content-specific post-processing filters to adapt a human oriented video/image codec into a codec suitable for machine vision tasks. By observing that artifacts produced by video/image codecs are content-dependent, we propose a novel training strategy based on competitive learning principles. This strategy assigns training samples to filters dynamically, in a fuzzy manner, which further optimizes the winning filter on the given sample. Inspired by simulated annealing optimization techniques, we employ a softmax function with a temperature variable as the weight allocation function to mitigate the effects of random initialization. Our evaluation, conducted on a system utilizing multiple post-processing filters within a Versatile Video Coding (VVC) codec framework, demonstrates the superiority of content-specific filters trained with our proposed strategies, specifically, when images are processed in blocks. Using VVC reference software VTM 12.0 as the anchor, experiments on the OpenImages dataset show an improvement in the BD-rate reduction from -41.3% and -44.6% to -42.3% and -44.7% for object detection and instance segmentation tasks, respectively, compared to independently trained filters. The statistics of the filter usage align with our hypothesis and underscore the importance of jointly optimizing filters for both content and reconstruction quality. Our findings pave the way for further improving the performance of video/image codecs.
NN-VVC: Versatile Video Coding boosted by self-supervisedly learned image coding for machines
Jan 19, 2024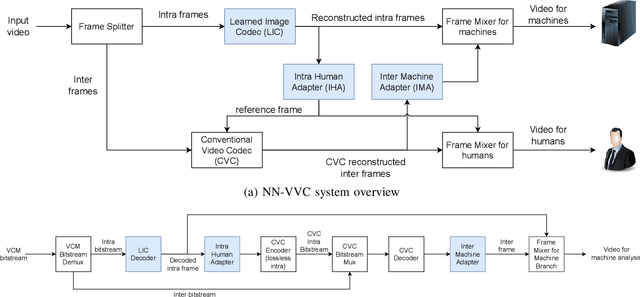

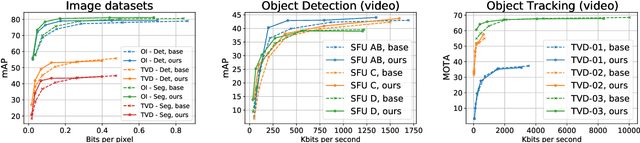
The recent progress in artificial intelligence has led to an ever-increasing usage of images and videos by machine analysis algorithms, mainly neural networks. Nonetheless, compression, storage and transmission of media have traditionally been designed considering human beings as the viewers of the content. Recent research on image and video coding for machine analysis has progressed mainly in two almost orthogonal directions. The first is represented by end-to-end (E2E) learned codecs which, while offering high performance on image coding, are not yet on par with state-of-the-art conventional video codecs and lack interoperability. The second direction considers using the Versatile Video Coding (VVC) standard or any other conventional video codec (CVC) together with pre- and post-processing operations targeting machine analysis. While the CVC-based methods benefit from interoperability and broad hardware and software support, the machine task performance is often lower than the desired level, particularly in low bitrates. This paper proposes a hybrid codec for machines called NN-VVC, which combines the advantages of an E2E-learned image codec and a CVC to achieve high performance in both image and video coding for machines. Our experiments show that the proposed system achieved up to -43.20% and -26.8% Bj{\o}ntegaard Delta rate reduction over VVC for image and video data, respectively, when evaluated on multiple different datasets and machine vision tasks. To the best of our knowledge, this is the first research paper showing a hybrid video codec that outperforms VVC on multiple datasets and multiple machine vision tasks.
Bridging the gap between image coding for machines and humans
Jan 19, 2024Image coding for machines (ICM) aims at reducing the bitrate required to represent an image while minimizing the drop in machine vision analysis accuracy. In many use cases, such as surveillance, it is also important that the visual quality is not drastically deteriorated by the compression process. Recent works on using neural network (NN) based ICM codecs have shown significant coding gains against traditional methods; however, the decompressed images, especially at low bitrates, often contain checkerboard artifacts. We propose an effective decoder finetuning scheme based on adversarial training to significantly enhance the visual quality of ICM codecs, while preserving the machine analysis accuracy, without adding extra bitcost or parameters at the inference phase. The results show complete removal of the checkerboard artifacts at the negligible cost of -1.6% relative change in task performance score. In the cases where some amount of artifacts is tolerable, such as when machine consumption is the primary target, this technique can enhance both pixel-fidelity and feature-fidelity scores without losing task performance.
Image coding for machines: an end-to-end learned approach
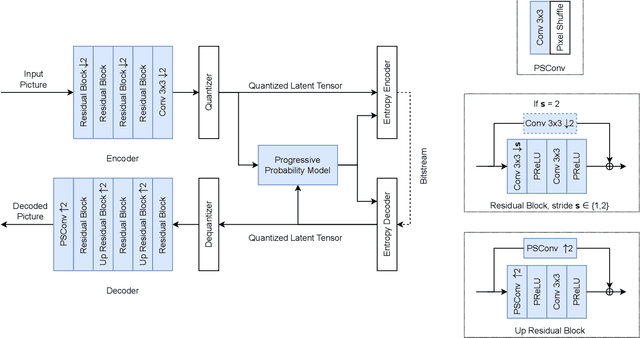
Aug 30, 2021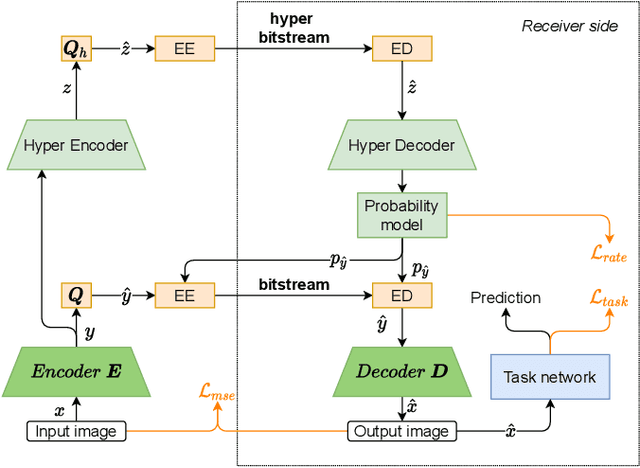

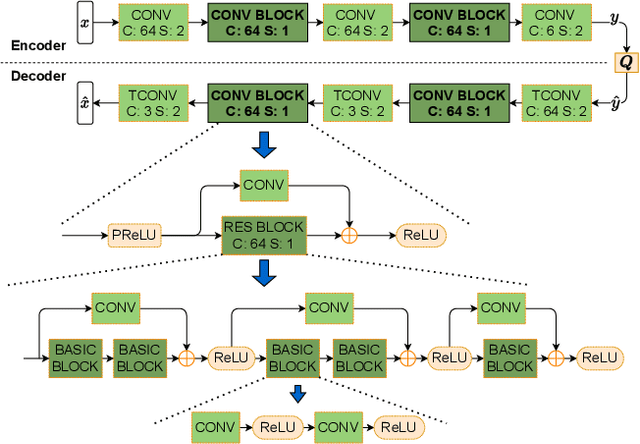
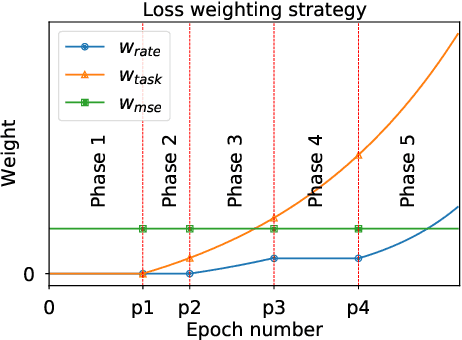
Over recent years, deep learning-based computer vision systems have been applied to images at an ever-increasing pace, oftentimes representing the only type of consumption for those images. Given the dramatic explosion in the number of images generated per day, a question arises: how much better would an image codec targeting machine-consumption perform against state-of-the-art codecs targeting human-consumption? In this paper, we propose an image codec for machines which is neural network (NN) based and end-to-end learned. In particular, we propose a set of training strategies that address the delicate problem of balancing competing loss functions, such as computer vision task losses, image distortion losses, and rate loss. Our experimental results show that our NN-based codec outperforms the state-of-the-art Versa-tile Video Coding (VVC) standard on the object detection and instance segmentation tasks, achieving -37.87% and -32.90% of BD-rate gain, respectively, while being fast thanks to its compact size. To the best of our knowledge, this is the first end-to-end learned machine-targeted image codec.
* Fixed a couple of mistakes since the version accepted in IEEE ICASSP2021
Learned Image Coding for Machines: A Content-Adaptive Approach
Aug 23, 2021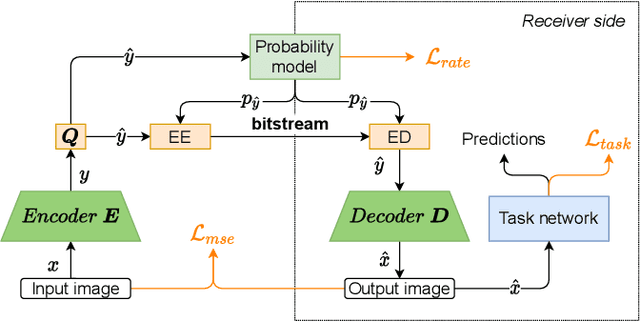
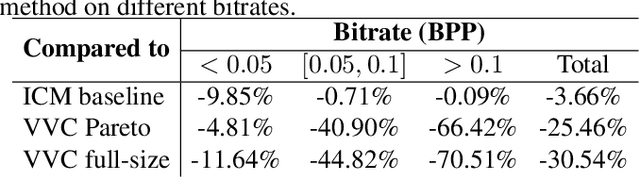
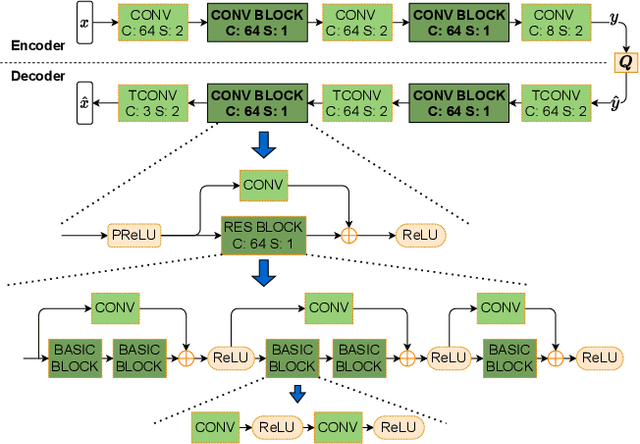
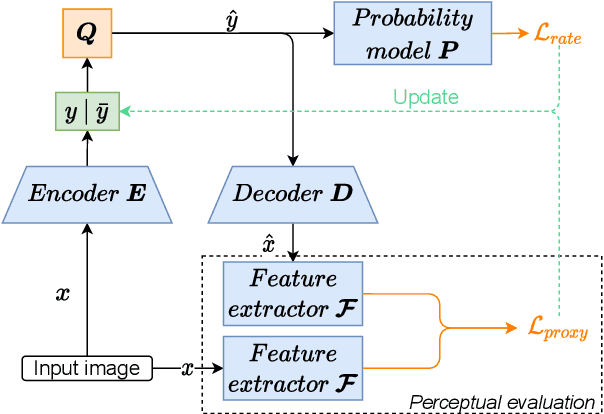
Today, according to the Cisco Annual Internet Report (2018-2023), the fastest-growing category of Internet traffic is machine-to-machine communication. In particular, machine-to-machine communication of images and videos represents a new challenge and opens up new perspectives in the context of data compression. One possible solution approach consists of adapting current human-targeted image and video coding standards to the use case of machine consumption. Another approach consists of developing completely new compression paradigms and architectures for machine-to-machine communications. In this paper, we focus on image compression and present an inference-time content-adaptive finetuning scheme that optimizes the latent representation of an end-to-end learned image codec, aimed at improving the compression efficiency for machine-consumption. The conducted experiments show that our online finetuning brings an average bitrate saving (BD-rate) of -3.66% with respect to our pretrained image codec. In particular, at low bitrate points, our proposed method results in a significant bitrate saving of -9.85%. Overall, our pretrained-and-then-finetuned system achieves -30.54% BD-rate over the state-of-the-art image/video codec Versatile Video Coding (VVC).
* Added some typo fixes since the accepted version in ICME2021
Theoretical Guarantees of Deep Embedding Losses Under Label Noise
Jan 02, 2019



Collecting labeled data to train deep neural networks is costly and even impractical for many tasks. Thus, research effort has been focused in automatically curated datasets or unsupervised and weakly supervised learning. The common problem in these directions is learning with unreliable label information. In this paper, we address the tolerance of deep embedding learning losses against label noise, i.e. when the observed labels are different from the true labels. Specifically, we provide the sufficient conditions to achieve theoretical guarantees for the 2 common loss functions: marginal loss and triplet loss. From these theoretical results, we can estimate how sampling strategies and initialization can affect the level of resistance against label noise. The analysis also helps providing more effective guidelines in unsupervised and weakly supervised deep embedding learning.
Improving speaker turn embedding by crossmodal transfer learning from face embedding
Jul 10, 2017



Learning speaker turn embeddings has shown considerable improvement in situations where conventional speaker modeling approaches fail. However, this improvement is relatively limited when compared to the gain observed in face embedding learning, which has been proven very successful for face verification and clustering tasks. Assuming that face and voices from the same identities share some latent properties (like age, gender, ethnicity), we propose three transfer learning approaches to leverage the knowledge from the face domain (learned from thousands of images and identities) for tasks in the speaker domain. These approaches, namely target embedding transfer, relative distance transfer, and clustering structure transfer, utilize the structure of the source face embedding space at different granularities to regularize the target speaker turn embedding space as optimizing terms. Our methods are evaluated on two public broadcast corpora and yield promising advances over competitive baselines in verification and audio clustering tasks, especially when dealing with short speaker utterances. The analysis of the results also gives insight into characteristics of the embedding spaces and shows their potential applications.