 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNN-VVC: Versatile Video Coding boosted by self-supervisedly learned image coding for machines
Jan 19, 2024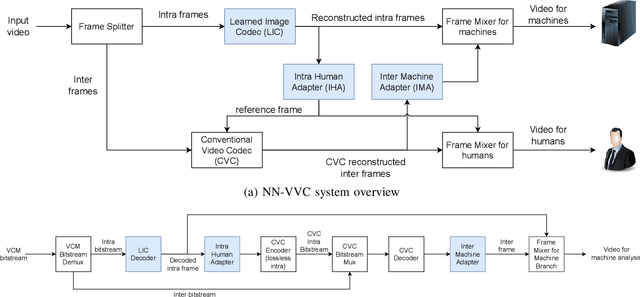
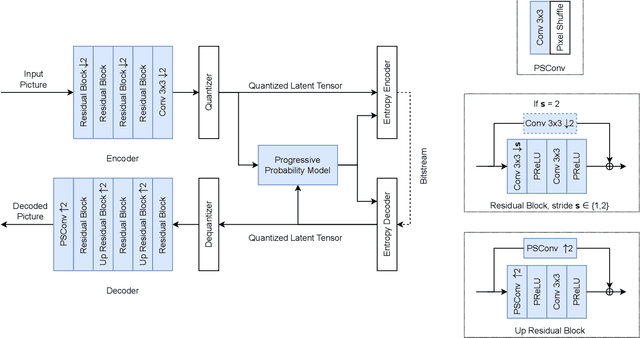

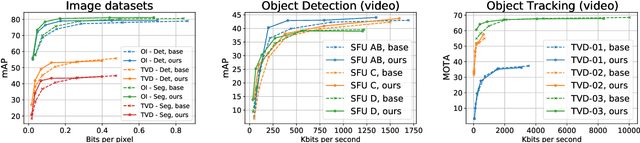
The recent progress in artificial intelligence has led to an ever-increasing usage of images and videos by machine analysis algorithms, mainly neural networks. Nonetheless, compression, storage and transmission of media have traditionally been designed considering human beings as the viewers of the content. Recent research on image and video coding for machine analysis has progressed mainly in two almost orthogonal directions. The first is represented by end-to-end (E2E) learned codecs which, while offering high performance on image coding, are not yet on par with state-of-the-art conventional video codecs and lack interoperability. The second direction considers using the Versatile Video Coding (VVC) standard or any other conventional video codec (CVC) together with pre- and post-processing operations targeting machine analysis. While the CVC-based methods benefit from interoperability and broad hardware and software support, the machine task performance is often lower than the desired level, particularly in low bitrates. This paper proposes a hybrid codec for machines called NN-VVC, which combines the advantages of an E2E-learned image codec and a CVC to achieve high performance in both image and video coding for machines. Our experiments show that the proposed system achieved up to -43.20% and -26.8% Bj{\o}ntegaard Delta rate reduction over VVC for image and video data, respectively, when evaluated on multiple different datasets and machine vision tasks. To the best of our knowledge, this is the first research paper showing a hybrid video codec that outperforms VVC on multiple datasets and multiple machine vision tasks.
Coding of volumetric content with MIV using VVC subpictures
Jun 06, 2022
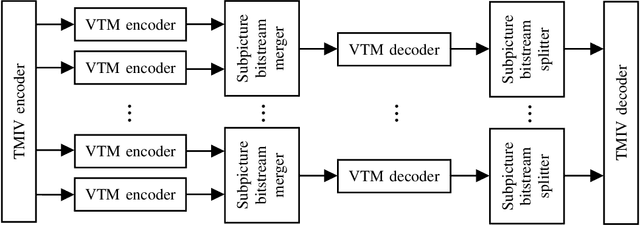


Storage and transport of six degrees of freedom (6DoF) dynamic volumetric visual content for immersive applications requires efficient compression. ISO/IEC MPEG has recently been working on a standard that aims to efficiently code and deliver 6DoF immersive visual experiences. This standard is called the MIV. MIV uses regular 2D video codecs to code the visual data. MPEG jointly with ITU-T VCEG, has also specified the VVC standard. VVC introduced recently the concept of subpicture. This tool was specifically designed to provide independent accessibility and decodability of sub-bitstreams for omnidirectional applications. This paper shows the benefit of using subpictures in the MIV use-case. While different ways in which subpictures could be used in MIV are discussed, a particular case study is selected. Namely, subpictures are used for parallel encoding and to reduce the number of decoder instances. Experimental results show that the cost of using subpictures in terms of bitrate overhead is negligible (0.1% to 0.4%), when compared to the overall bitrate. The number of decoder instances on the other hand decreases by a factor of two.
* 6 pages, 3 figures
A Compression Objective and a Cycle Loss for Neural Image Compression
May 24, 2019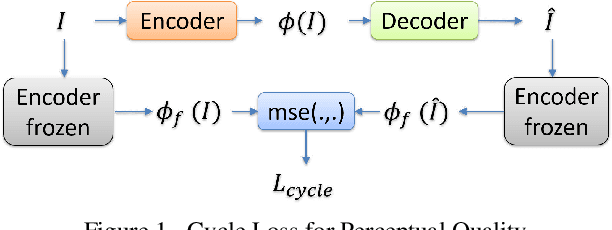
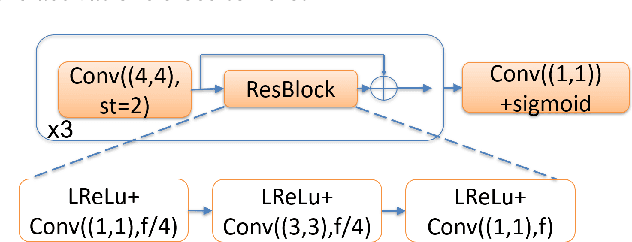
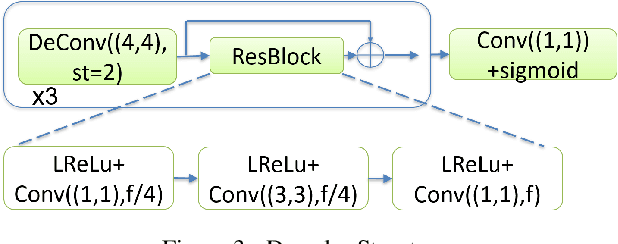

In this manuscript we propose two objective terms for neural image compression: a compression objective and a cycle loss. These terms are applied on the encoder output of an autoencoder and are used in combination with reconstruction losses. The compression objective encourages sparsity and low entropy in the activations. The cycle loss term represents the distortion between encoder outputs computed from the original image and from the reconstructed image (code-domain distortion). We train different autoencoders by using the compression objective in combination with different losses: a) MSE, b) MSE and MSSSIM, c) MSE, MS-SSIM and cycle loss. We observe that images encoded by these differently-trained autoencoders fall into different points of the perception-distortion curve (while having similar bit-rates). In particular, MSE-only training favors low image-domain distortion, whereas cycle loss training favors high perceptual quality.