 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEURN: Learning Explainable Univariate Rules with Neural Networks
Mar 27, 2023In this paper, we propose LEURN: a neural network architecture that learns univariate decision rules. LEURN is a white-box algorithm that results into univariate trees and makes explainable decisions in every stage. In each layer, LEURN finds a set of univariate rules based on an embedding of the previously checked rules and their corresponding responses. Both rule finding and final decision mechanisms are weighted linear combinations of these embeddings, hence contribution of all rules are clearly formulated and explainable. LEURN can select features, extract feature importance, provide semantic similarity between a pair of samples, be used in a generative manner and can give a confidence score. Thanks to a smoothness parameter, LEURN can also controllably behave like decision trees or vanilla neural networks. Besides these advantages, LEURN achieves comparable performance to state-of-the-art methods across 30 tabular datasets for classification and regression problems.
Neural Networks are Decision Trees
Oct 11, 2022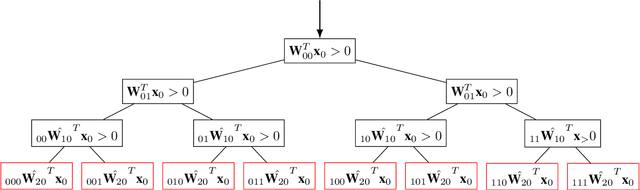


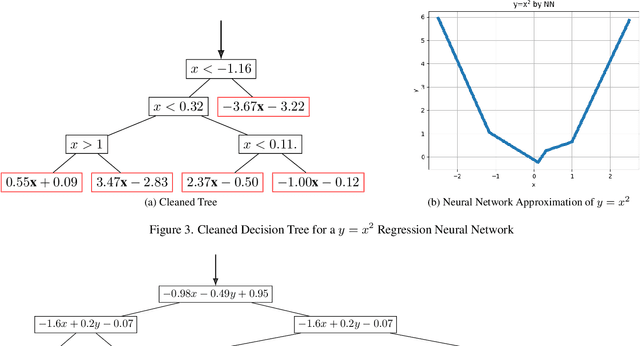
In this manuscript, we show that any neural network having piece-wise linear activation functions can be represented as a decision tree. The representation is equivalence and not an approximation, thus keeping the accuracy of the neural network exactly as is. This equivalence shows that neural networks are indeed interpretable by design and makes the \textit{black-box} understanding obsolete. We share equivalent trees of some neural networks and show that besides providing interpretability, tree representation can also achieve some computational advantages. The analysis holds both for fully connected and convolutional networks, which may or may not also include skip connections and/or normalizations.
A Sub-band Approach to Deep Denoising Wavelet Networks and a Frequency-adaptive Loss for Perceptual Quality
Feb 16, 2021

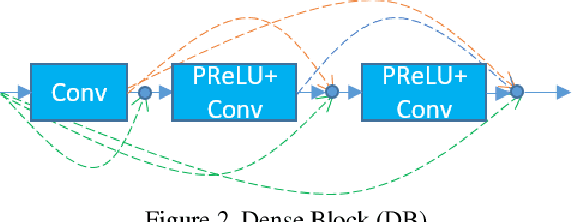

In this paper, we propose two contributions to neural network based denoising. First, we propose applying separate convolutional layers to each sub-band of discrete wavelet transform (DWT) as opposed to the common usage of DWT which concatenates all sub-bands and applies a single convolution layer. We show that our approach to using DWT in neural networks improves the accuracy notably, due to keeping the sub-band order uncorrupted prior to inverse DWT. Our second contribution is a denoising loss based on top k-percent of errors in frequency domain. A neural network trained with this loss, adaptively focuses on frequencies that it fails to recover the most in each iteration. We show that this loss results into better perceptual quality by providing an image that is more balanced in terms of the errors in frequency components.
A Compression Objective and a Cycle Loss for Neural Image Compression
May 24, 2019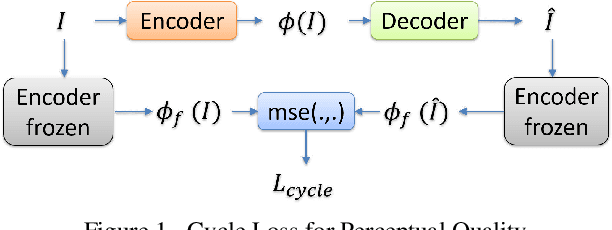
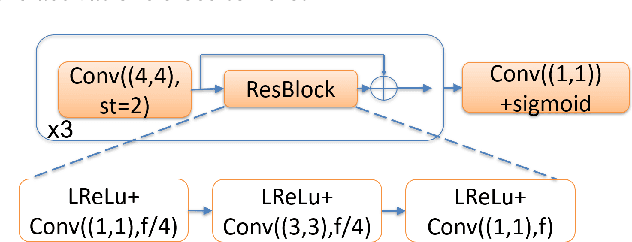
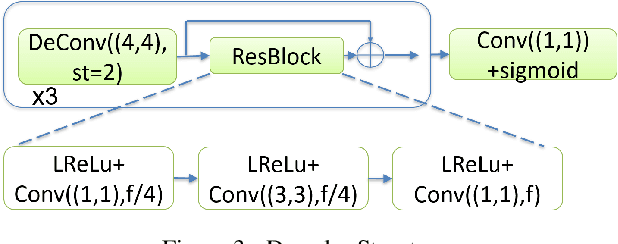

In this manuscript we propose two objective terms for neural image compression: a compression objective and a cycle loss. These terms are applied on the encoder output of an autoencoder and are used in combination with reconstruction losses. The compression objective encourages sparsity and low entropy in the activations. The cycle loss term represents the distortion between encoder outputs computed from the original image and from the reconstructed image (code-domain distortion). We train different autoencoders by using the compression objective in combination with different losses: a) MSE, b) MSE and MSSSIM, c) MSE, MS-SSIM and cycle loss. We observe that images encoded by these differently-trained autoencoders fall into different points of the perception-distortion curve (while having similar bit-rates). In particular, MSE-only training favors low image-domain distortion, whereas cycle loss training favors high perceptual quality.
Compressing Weight-updates for Image Artifacts Removal Neural Networks
May 10, 2019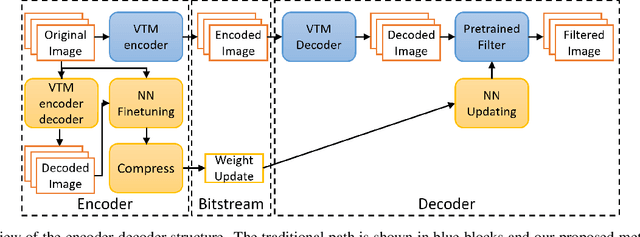
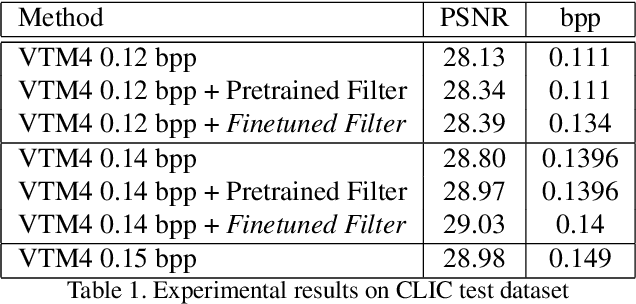

In this paper, we present a novel approach for fine-tuning a decoder-side neural network in the context of image compression, such that the weight-updates are better compressible. At encoder side, we fine-tune a pre-trained artifact removal network on target data by using a compression objective applied on the weight-update. In particular, the compression objective encourages weight-updates which are sparse and closer to quantized values. This way, the final weight-update can be compressed more efficiently by pruning and quantization, and can be included into the encoded bitstream together with the image bitstream of a traditional codec. We show that this approach achieves reconstruction quality which is on-par or slightly superior to a traditional codec, at comparable bitrates. To our knowledge, this is the first attempt to combine image compression and neural network's weight update compression.
Compressibility Loss for Neural Network Weights
May 03, 2019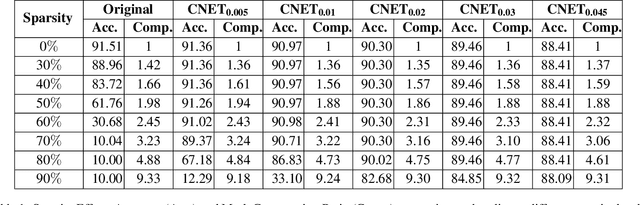

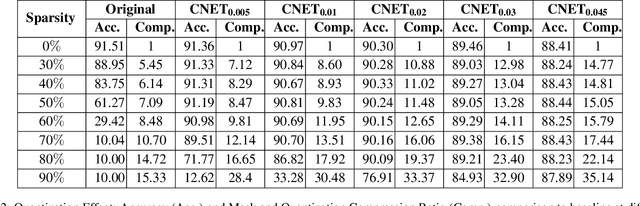

In this paper we apply a compressibility loss that enables learning highly compressible neural network weights. The loss was previously proposed as a measure of negated sparsity of a signal, yet in this paper we show that minimizing this loss also enforces the non-zero parts of the signal to have very low entropy, thus making the entire signal more compressible. For an optimization problem where the goal is to minimize the compressibility loss (the objective), we prove that at any critical point of the objective, the weight vector is a ternary signal and the corresponding value of the objective is the squared root of the number of non-zero elements in the signal, thus directly related to sparsity. In the experiments, we train neural networks with the compressibility loss and we show that the proposed method achieves weight sparsity and compression ratios comparable with the state-of-the-art.
Block-optimized Variable Bit Rate Neural Image Compression
May 28, 2018
In this work, we propose an end-to-end block-based auto-encoder system for image compression. We introduce novel contributions to neural-network based image compression, mainly in achieving binarization simulation, variable bit rates with multiple networks, entropy-friendly representations, inference-stage code optimization and performance-improving normalization layers in the auto-encoder. We evaluate and show the incremental performance increase of each of our contributions.
Memory-Efficient Deep Salient Object Segmentation Networks on Gridized Superpixels
May 22, 2018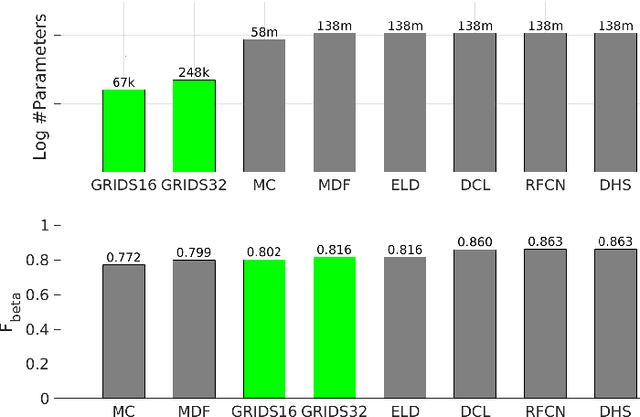
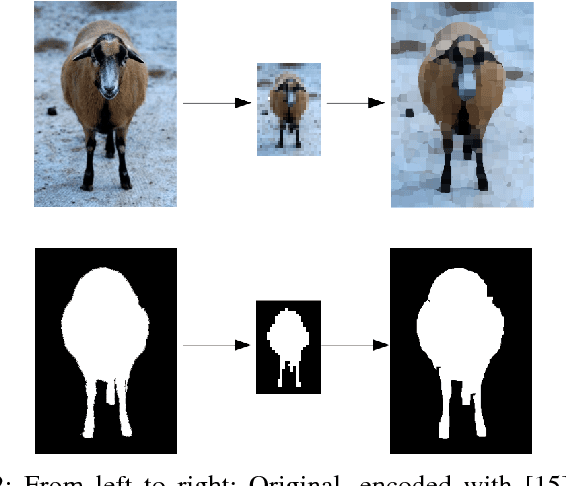
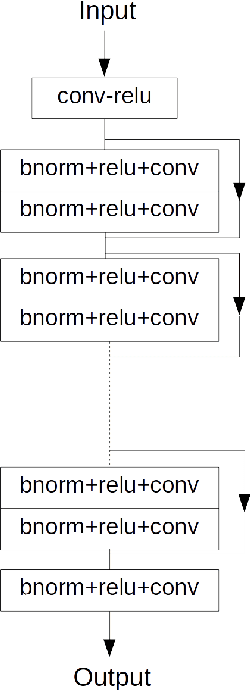
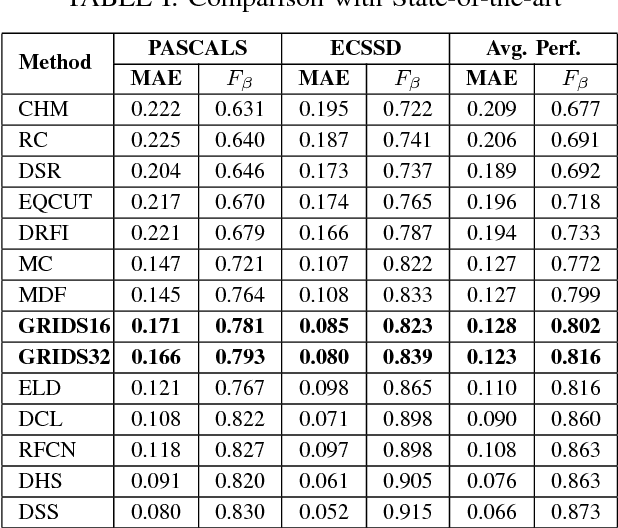
Computer vision algorithms with pixel-wise labeling tasks, such as semantic segmentation and salient object detection, have gone through a significant accuracy increase with the incorporation of deep learning. Deep segmentation methods slightly modify and fine-tune pre-trained networks that have hundreds of millions of parameters. In this work, we question the need to have such memory demanding networks for the specific task of salient object segmentation. To this end, we propose a way to learn a memory-efficient network from scratch by training it only on salient object detection datasets. Our method encodes images to gridized superpixels that preserve both the object boundaries and the connectivity rules of regular pixels. This representation allows us to use convolutional neural networks that operate on regular grids. By using these encoded images, we train a memory-efficient network using only 0.048\% of the number of parameters that other deep salient object detection networks have. Our method shows comparable accuracy with the state-of-the-art deep salient object detection methods and provides a faster and a much more memory-efficient alternative to them. Due to its easy deployment, such a network is preferable for applications in memory limited devices such as mobile phones and IoT devices.
Saliency-Enhanced Robust Visual Tracking
Feb 08, 2018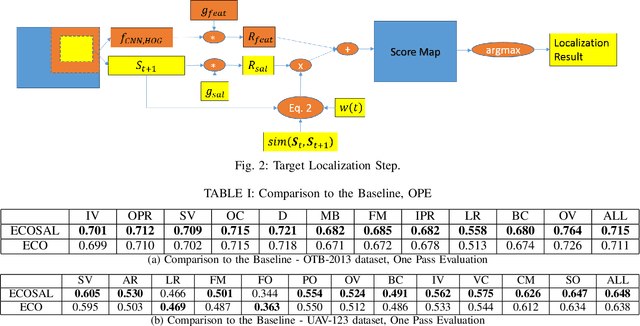

Discrete correlation filter (DCF) based trackers have shown considerable success in visual object tracking. These trackers often make use of low to mid level features such as histogram of gradients (HoG) and mid-layer activations from convolution neural networks (CNNs). We argue that including semantically higher level information to the tracked features may provide further robustness to challenging cases such as viewpoint changes. Deep salient object detection is one example of such high level features, as it make use of semantic information to highlight the important regions in the given scene. In this work, we propose an improvement over DCF based trackers by combining saliency based and other features based filter responses. This combination is performed with an adaptive weight on the saliency based filter responses, which is automatically selected according to the temporal consistency of visual saliency. We show that our method consistently improves a baseline DCF based tracker especially in challenging cases and performs superior to the state-of-the-art. Our improved tracker operates at 9.3 fps, introducing a small computational burden over the baseline which operates at 11 fps.
A Theoretical Investigation of Graph Degree as an Unsupervised Normality Measure
Feb 05, 2018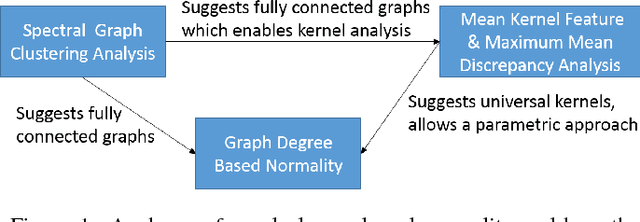
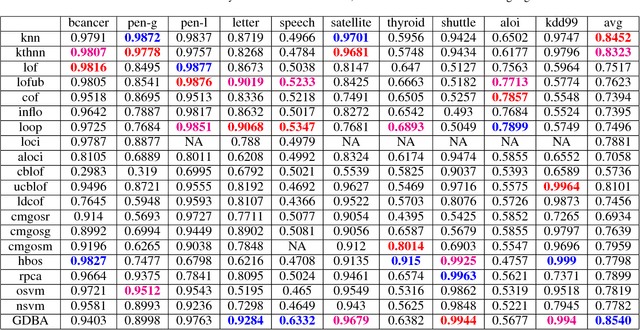


For a graph representation of a dataset, a straightforward normality measure for a sample can be its graph degree. Considering a weighted graph, degree of a sample is the sum of the corresponding row's values in a similarity matrix. The measure is intuitive given the abnormal samples are usually rare and they are dissimilar to the rest of the data. In order to have an in-depth theoretical understanding, in this manuscript, we investigate the graph degree in spectral graph clustering based and kernel based point of views and draw connections to a recent kernel method for the two sample problem. We show that our analyses guide us to choose fully-connected graphs whose edge weights are calculated via universal kernels. We show that a simple graph degree based unsupervised anomaly detection method with the above properties, achieves higher accuracy compared to other unsupervised anomaly detection methods on average over 10 widely used datasets. We also provide an extensive analysis on the effect of the kernel parameter on the method's accuracy.