 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptation and Attention for Neural Video Coding
Dec 16, 2021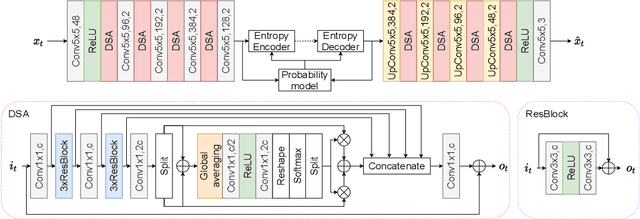
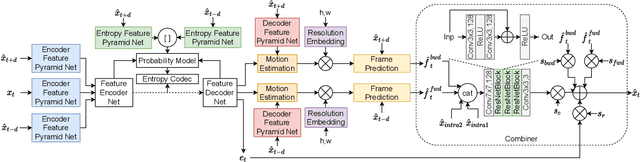
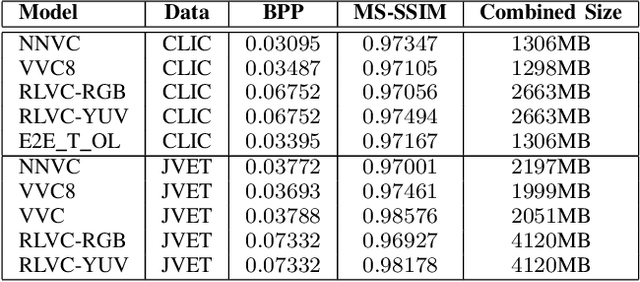
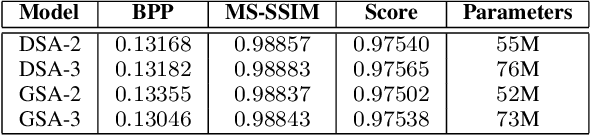
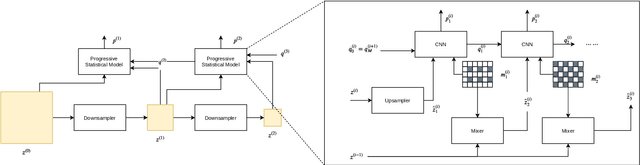
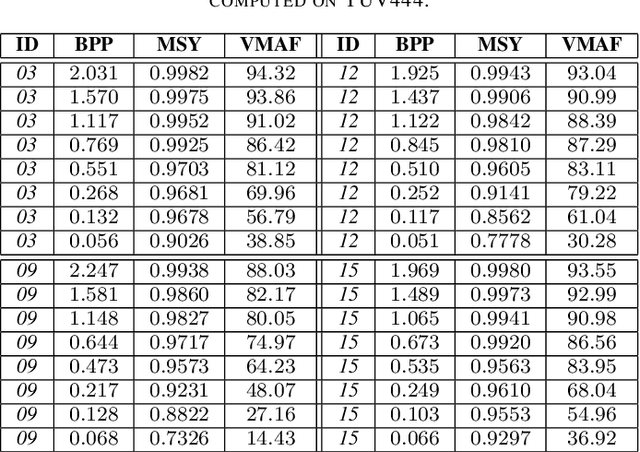
Neural image coding represents now the state-of-the-art image compression approach. However, a lot of work is still to be done in the video domain. In this work, we propose an end-to-end learned video codec that introduces several architectural novelties as well as training novelties, revolving around the concepts of adaptation and attention. Our codec is organized as an intra-frame codec paired with an inter-frame codec. As one architectural novelty, we propose to train the inter-frame codec model to adapt the motion estimation process based on the resolution of the input video. A second architectural novelty is a new neural block that combines concepts from split-attention based neural networks and from DenseNets. Finally, we propose to overfit a set of decoder-side multiplicative parameters at inference time. Through ablation studies and comparisons to prior art, we show the benefits of our proposed techniques in terms of coding gains. We compare our codec to VVC/H.266 and RLVC, which represent the state-of-the-art traditional and end-to-end learned codecs, respectively, and to the top performing end-to-end learned approach in 2021 CLIC competition, E2E_T_OL. Our codec clearly outperforms E2E_T_OL, and compare favorably to VVC and RLVC in some settings.
Efficient Adaptation of Neural Network Filter for Video Compression
Aug 13, 2020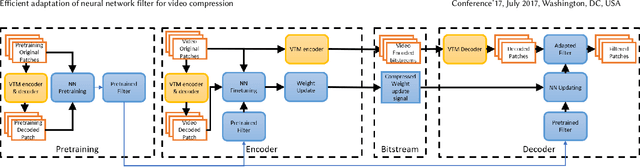
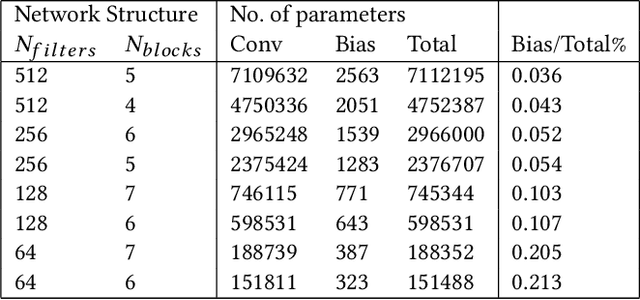
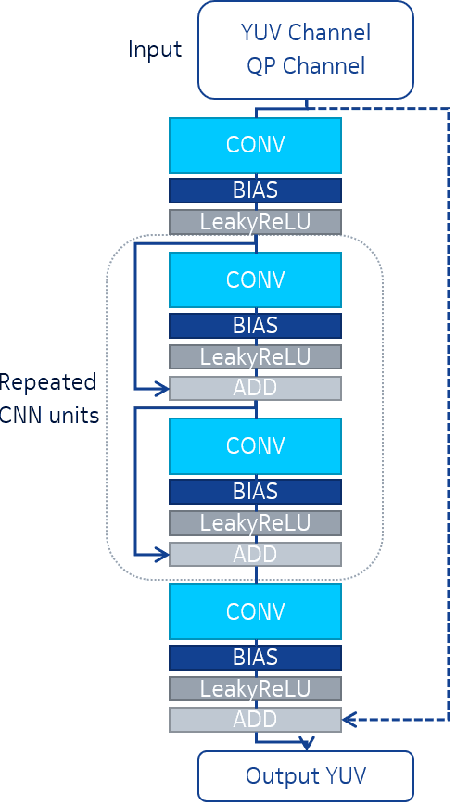
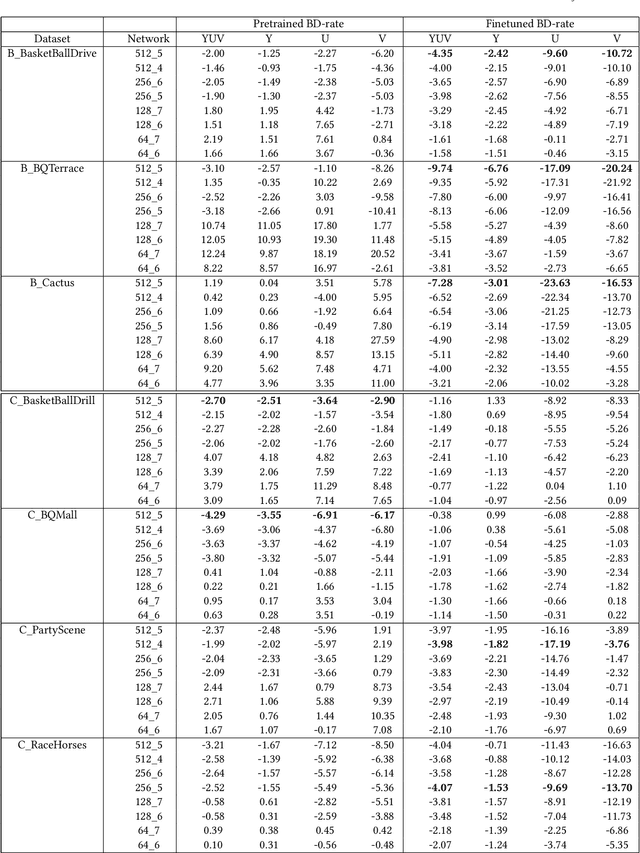
We present an efficient finetuning methodology for neural-network filters which are applied as a postprocessing artifact-removal step in video coding pipelines. The fine-tuning is performed at encoder side to adapt the neural network to the specific content that is being encoded. In order to maximize the PSNR gain and minimize the bitrate overhead, we propose to finetune only the convolutional layers' biases. The proposed method achieves convergence much faster than conventional finetuning approaches, making it suitable for practical applications. The weight-update can be included into the video bitstream generated by the existing video codecs. We show that our method achieves up to 9.7% average BD-rate gain when compared to the state-of-art Versatile Video Coding (VVC) standard codec on 7 test sequences.
L$^2$C -- Learning to Learn to Compress
Jul 31, 2020

In this paper we present an end-to-end meta-learned system for image compression. Traditional machine learning based approaches to image compression train one or more neural network for generalization performance. However, at inference time, the encoder or the latent tensor output by the encoder can be optimized for each test image. This optimization can be regarded as a form of adaptation or benevolent overfitting to the input content. In order to reduce the gap between training and inference conditions, we propose a new training paradigm for learned image compression, which is based on meta-learning. In a first phase, the neural networks are trained normally. In a second phase, the Model-Agnostic Meta-learning approach is adapted to the specific case of image compression, where the inner-loop performs latent tensor overfitting, and the outer loop updates both encoder and decoder neural networks based on the overfitting performance. Furthermore, after meta-learning, we propose to overfit and cluster the bias terms of the decoder on training image patches, so that at inference time the optimal content-specific bias terms can be selected at encoder-side. Finally, we propose a new probability model for lossless compression, which combines concepts from both multi-scale and super-resolution probability model approaches. We show the benefits of all our proposed ideas via carefully designed experiments.
End-to-End Learning for Video Frame Compression with Self-Attention
Apr 20, 2020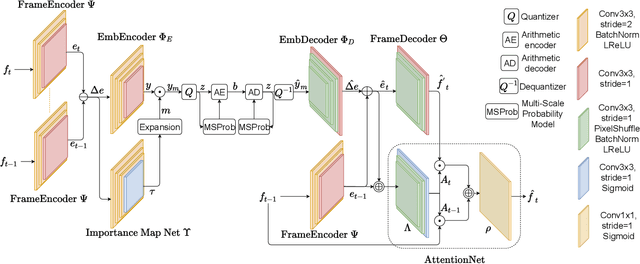
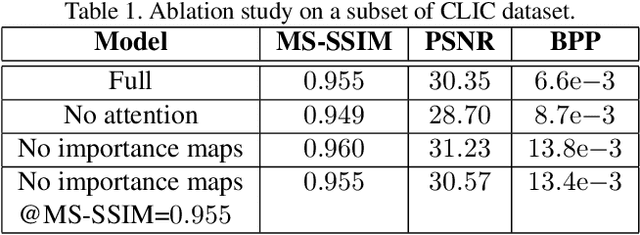

One of the core components of conventional (i.e., non-learned) video codecs consists of predicting a frame from a previously-decoded frame, by leveraging temporal correlations. In this paper, we propose an end-to-end learned system for compressing video frames. Instead of relying on pixel-space motion (as with optical flow), our system learns deep embeddings of frames and encodes their difference in latent space. At decoder-side, an attention mechanism is designed to attend to the latent space of frames to decide how different parts of the previous and current frame are combined to form the final predicted current frame. Spatially-varying channel allocation is achieved by using importance masks acting on the feature-channels. The model is trained to reduce the bitrate by minimizing a loss on importance maps and a loss on the probability output by a context model for arithmetic coding. In our experiments, we show that the proposed system achieves high compression rates and high objective visual quality as measured by MS-SSIM and PSNR. Furthermore, we provide ablation studies where we highlight the contribution of different components.
A Compression Objective and a Cycle Loss for Neural Image Compression
May 24, 2019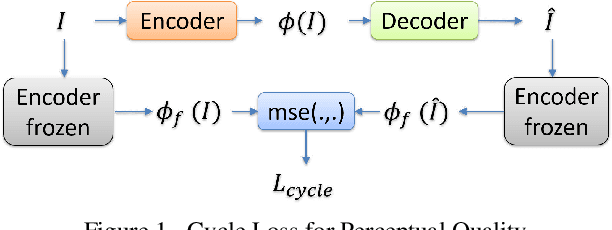
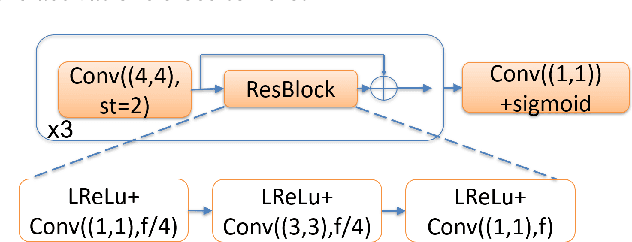
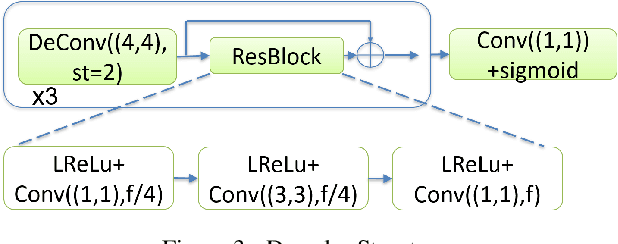

In this manuscript we propose two objective terms for neural image compression: a compression objective and a cycle loss. These terms are applied on the encoder output of an autoencoder and are used in combination with reconstruction losses. The compression objective encourages sparsity and low entropy in the activations. The cycle loss term represents the distortion between encoder outputs computed from the original image and from the reconstructed image (code-domain distortion). We train different autoencoders by using the compression objective in combination with different losses: a) MSE, b) MSE and MSSSIM, c) MSE, MS-SSIM and cycle loss. We observe that images encoded by these differently-trained autoencoders fall into different points of the perception-distortion curve (while having similar bit-rates). In particular, MSE-only training favors low image-domain distortion, whereas cycle loss training favors high perceptual quality.
Compressing Weight-updates for Image Artifacts Removal Neural Networks
May 10, 2019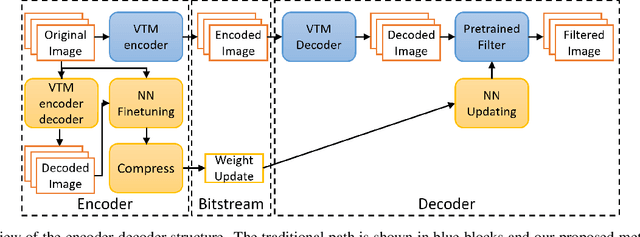
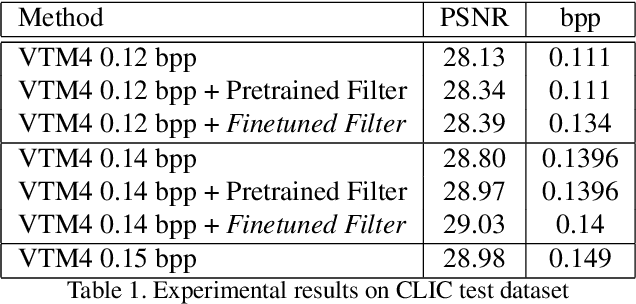

In this paper, we present a novel approach for fine-tuning a decoder-side neural network in the context of image compression, such that the weight-updates are better compressible. At encoder side, we fine-tune a pre-trained artifact removal network on target data by using a compression objective applied on the weight-update. In particular, the compression objective encourages weight-updates which are sparse and closer to quantized values. This way, the final weight-update can be compressed more efficiently by pruning and quantization, and can be included into the encoded bitstream together with the image bitstream of a traditional codec. We show that this approach achieves reconstruction quality which is on-par or slightly superior to a traditional codec, at comparable bitrates. To our knowledge, this is the first attempt to combine image compression and neural network's weight update compression.
Block-optimized Variable Bit Rate Neural Image Compression
May 28, 2018
In this work, we propose an end-to-end block-based auto-encoder system for image compression. We introduce novel contributions to neural-network based image compression, mainly in achieving binarization simulation, variable bit rates with multiple networks, entropy-friendly representations, inference-stage code optimization and performance-improving normalization layers in the auto-encoder. We evaluate and show the incremental performance increase of each of our contributions.