 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Real-Time Facial Analysis System
Sep 21, 2021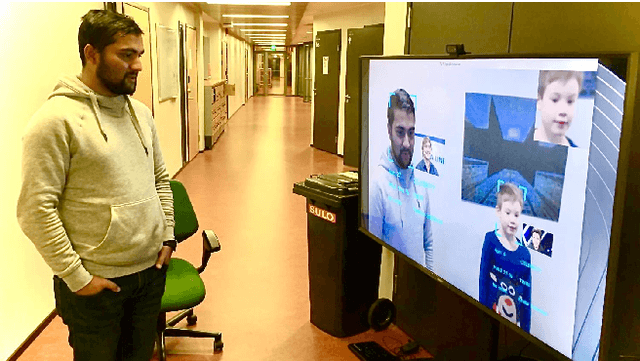
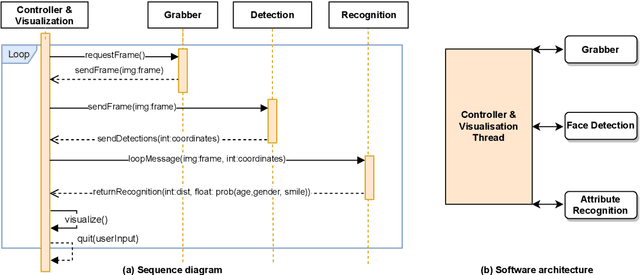
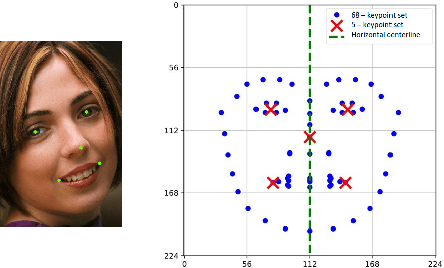
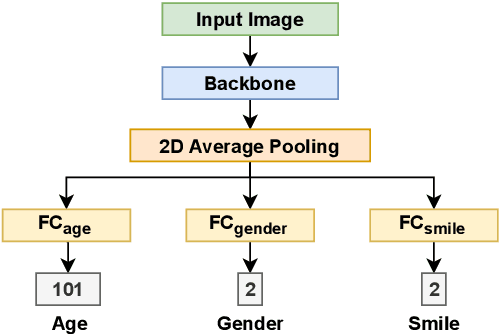
Facial analysis is an active research area in computer vision, with many practical applications. Most of the existing studies focus on addressing one specific task and maximizing its performance. For a complete facial analysis system, one needs to solve these tasks efficiently to ensure a smooth experience. In this work, we present a system-level design of a real-time facial analysis system. With a collection of deep neural networks for object detection, classification, and regression, the system recognizes age, gender, facial expression, and facial similarity for each person that appears in the camera view. We investigate the parallelization and interplay of individual tasks. Results on common off-the-shelf architecture show that the system's accuracy is comparable to the state-of-the-art methods, and the recognition speed satisfies real-time requirements. Moreover, we propose a multitask network for jointly predicting the first three attributes, i.e., age, gender, and facial expression. Source code and trained models are available at https://github.com/mahehu/TUT-live-age-estimator.
On the Importance of Encrypting Deep Features
Aug 16, 2021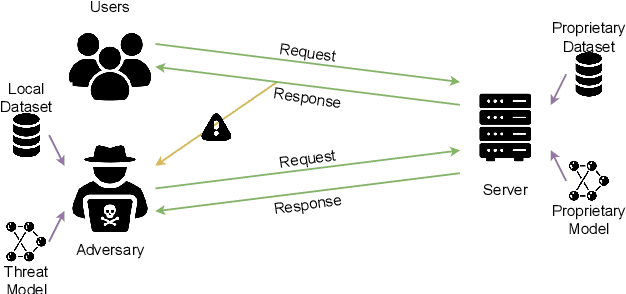

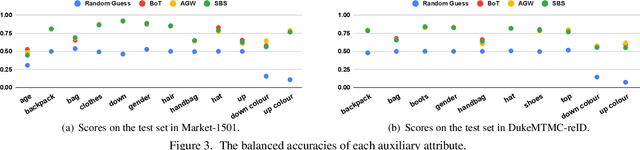
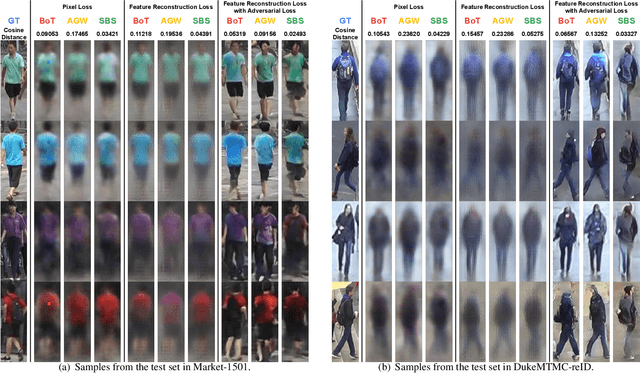
In this study, we analyze model inversion attacks with only two assumptions: feature vectors of user data are known, and a black-box API for inference is provided. On the one hand, limitations of existing studies are addressed by opting for a more practical setting. Experiments have been conducted on state-of-the-art models in person re-identification, and two attack scenarios (i.e., recognizing auxiliary attributes and reconstructing user data) are investigated. Results show that an adversary could successfully infer sensitive information even under severe constraints. On the other hand, it is advisable to encrypt feature vectors, especially for a machine learning model in production. As an alternative to traditional encryption methods such as AES, a simple yet effective method termed ShuffleBits is presented. More specifically, the binary sequence of each floating-point number gets shuffled. Deployed using the one-time pad scheme, it serves as a plug-and-play module that is applicable to any neural network, and the resulting model directly outputs deep features in encrypted form. Source code is publicly available at https://github.com/nixingyang/ShuffleBits.
FlipReID: Closing the Gap between Training and Inference in Person Re-Identification
May 12, 2021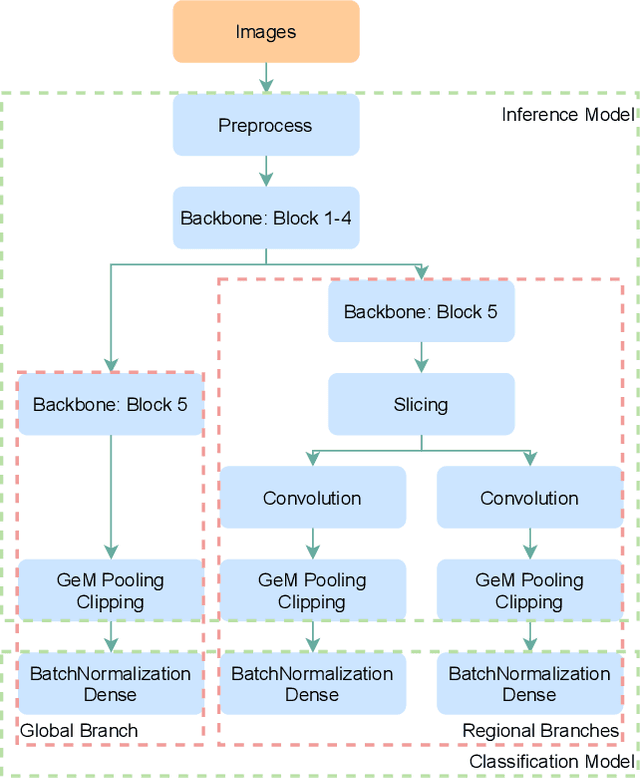
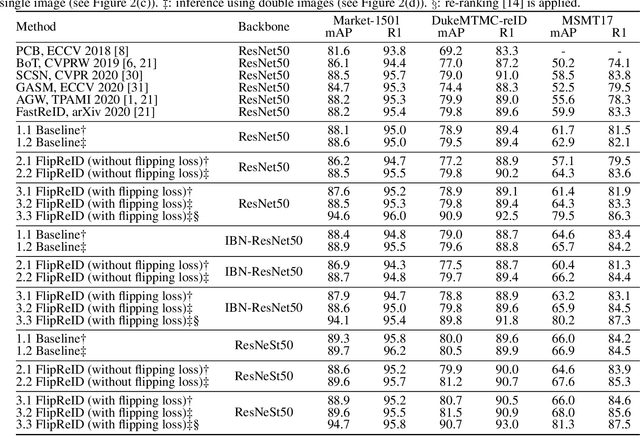
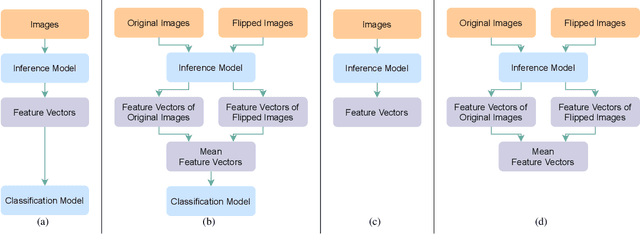
Since neural networks are data-hungry, incorporating data augmentation in training is a widely adopted technique that enlarges datasets and improves generalization. On the other hand, aggregating predictions of multiple augmented samples (i.e., test-time augmentation) could boost performance even further. In the context of person re-identification models, it is common practice to extract embeddings for both the original images and their horizontally flipped variants. The final representation is the mean of the aforementioned feature vectors. However, such scheme results in a gap between training and inference, i.e., the mean feature vectors calculated in inference are not part of the training pipeline. In this study, we devise the FlipReID structure with the flipping loss to address this issue. More specifically, models using the FlipReID structure are trained on the original images and the flipped images simultaneously, and incorporating the flipping loss minimizes the mean squared error between feature vectors of corresponding image pairs. Extensive experiments show that our method brings consistent improvements. In particular, we set a new record for MSMT17 which is the largest person re-identification dataset. The source code is available at https://github.com/nixingyang/FlipReID.
AdaptiveReID: Adaptive L2 Regularization in Person Re-Identification
Jul 15, 2020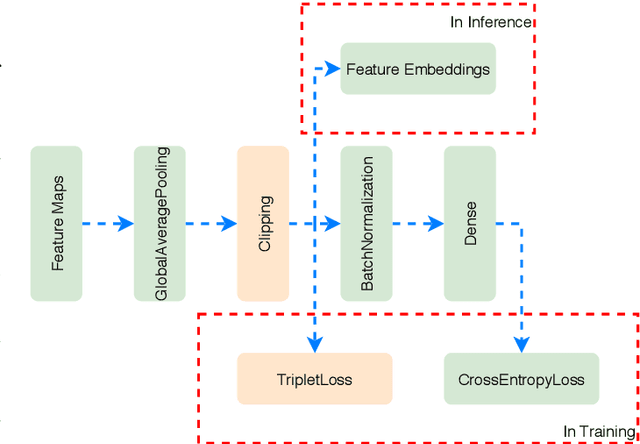
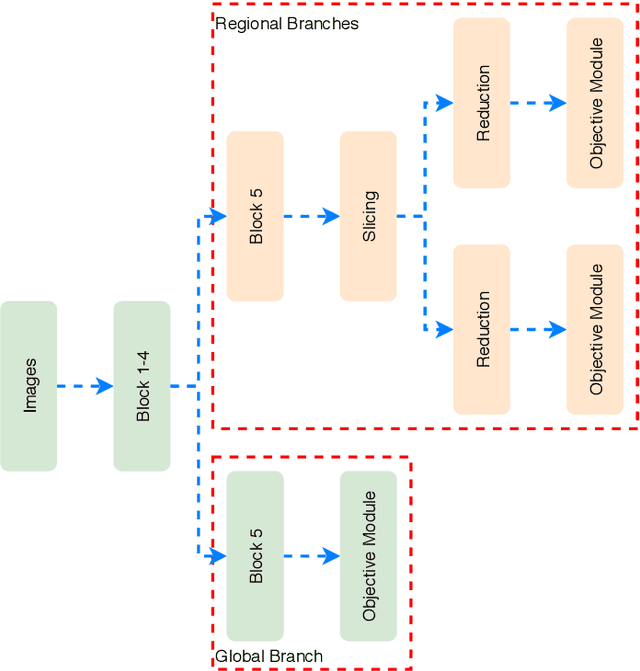
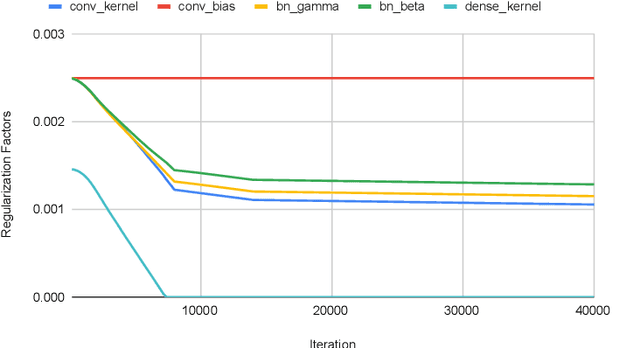
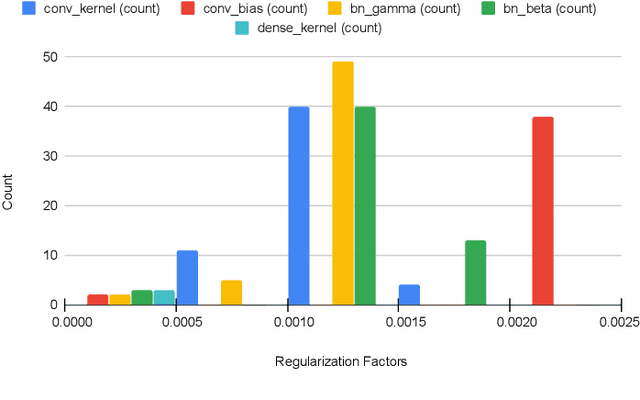
We introduce an adaptive L2 regularization mechanism termed AdaptiveReID, in the setting of person re-identification. In the literature, it is common practice to utilize hand-picked regularization factors which remain constant throughout the training procedure. Unlike existing approaches, the regularization factors in our proposed method are updated adaptively through backpropagation. This is achieved by incorporating trainable scalar variables as the regularization factors, which are further fed into a scaled hard sigmoid function. Extensive experiments on the Market-1501, DukeMTMC-reID and MSMT17 datasets validate the effectiveness of our framework. Most notably, we obtain state-of-the-art performance on MSMT17, which is the largest dataset for person re-identification. Source code will be published at https://github.com/nixingyang/AdaptiveReID.
Vehicle Attribute Recognition by Appearance: Computer Vision Methods for Vehicle Type, Make and Model Classification
Jun 29, 2020
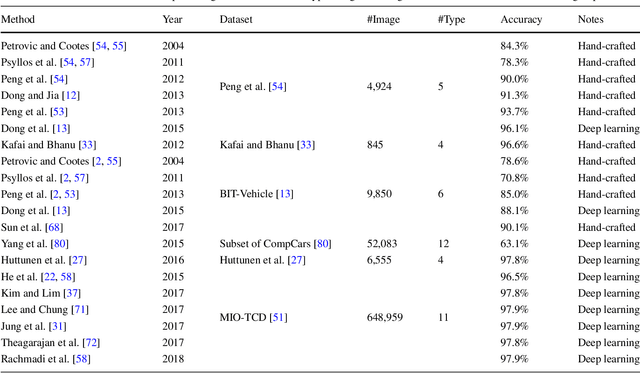

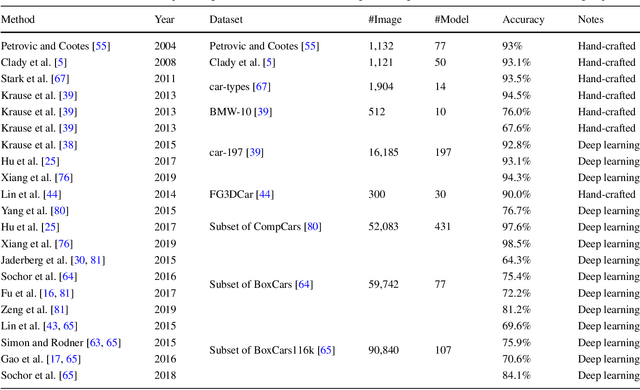
This paper studies vehicle attribute recognition by appearance. In the literature, image-based target recognition has been extensively investigated in many use cases, such as facial recognition, but less so in the field of vehicle attribute recognition. We survey a number of algorithms that identify vehicle properties ranging from coarse-grained level (vehicle type) to fine-grained level (vehicle make and model). Moreover, we discuss two alternative approaches for these tasks, including straightforward classification and a more flexible metric learning method. Furthermore, we design a simulated real-world scenario for vehicle attribute recognition and present an experimental comparison of the two approaches.
Block-optimized Variable Bit Rate Neural Image Compression
May 28, 2018
In this work, we propose an end-to-end block-based auto-encoder system for image compression. We introduce novel contributions to neural-network based image compression, mainly in achieving binarization simulation, variable bit rates with multiple networks, entropy-friendly representations, inference-stage code optimization and performance-improving normalization layers in the auto-encoder. We evaluate and show the incremental performance increase of each of our contributions.
Memory-Efficient Deep Salient Object Segmentation Networks on Gridized Superpixels
May 22, 2018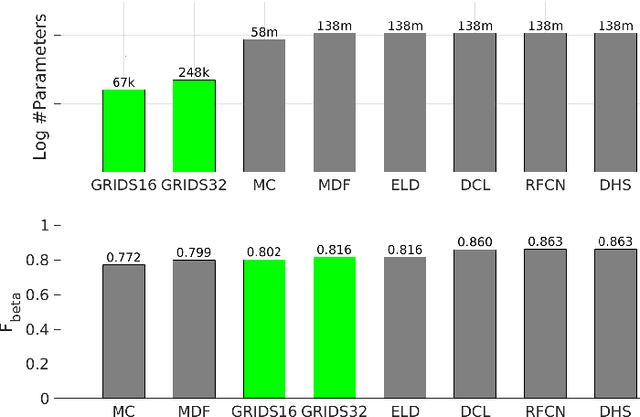
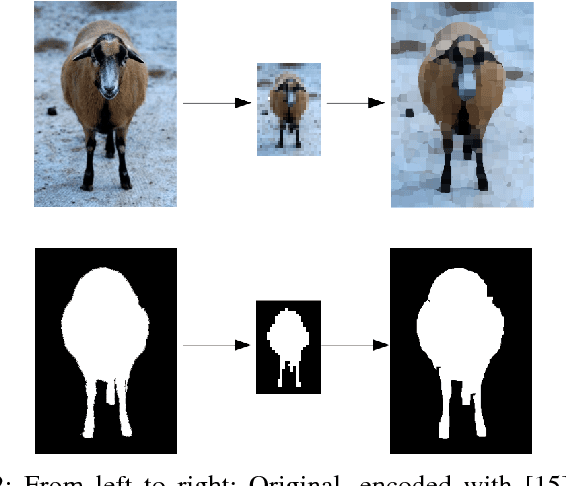
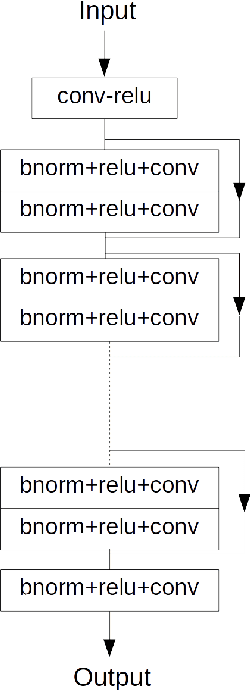
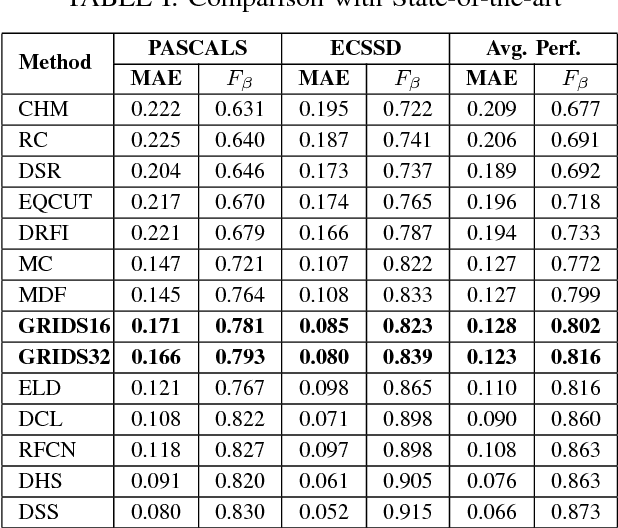
Computer vision algorithms with pixel-wise labeling tasks, such as semantic segmentation and salient object detection, have gone through a significant accuracy increase with the incorporation of deep learning. Deep segmentation methods slightly modify and fine-tune pre-trained networks that have hundreds of millions of parameters. In this work, we question the need to have such memory demanding networks for the specific task of salient object segmentation. To this end, we propose a way to learn a memory-efficient network from scratch by training it only on salient object detection datasets. Our method encodes images to gridized superpixels that preserve both the object boundaries and the connectivity rules of regular pixels. This representation allows us to use convolutional neural networks that operate on regular grids. By using these encoded images, we train a memory-efficient network using only 0.048\% of the number of parameters that other deep salient object detection networks have. Our method shows comparable accuracy with the state-of-the-art deep salient object detection methods and provides a faster and a much more memory-efficient alternative to them. Due to its easy deployment, such a network is preferable for applications in memory limited devices such as mobile phones and IoT devices.
Clustering and Unsupervised Anomaly Detection with L2 Normalized Deep Auto-Encoder Representations
Feb 01, 2018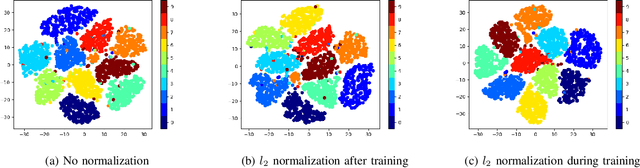


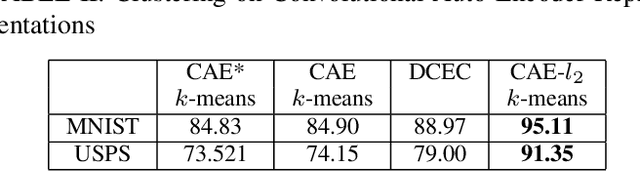
Clustering is essential to many tasks in pattern recognition and computer vision. With the advent of deep learning, there is an increasing interest in learning deep unsupervised representations for clustering analysis. Many works on this domain rely on variants of auto-encoders and use the encoder outputs as representations/features for clustering. In this paper, we show that an l2 normalization constraint on these representations during auto-encoder training, makes the representations more separable and compact in the Euclidean space after training. This greatly improves the clustering accuracy when k-means clustering is employed on the representations. We also propose a clustering based unsupervised anomaly detection method using l2 normalized deep auto-encoder representations. We show the effect of l2 normalization on anomaly detection accuracy. We further show that the proposed anomaly detection method greatly improves accuracy compared to previously proposed deep methods such as reconstruction error based anomaly detection.
Video Ladder Networks
Dec 30, 2016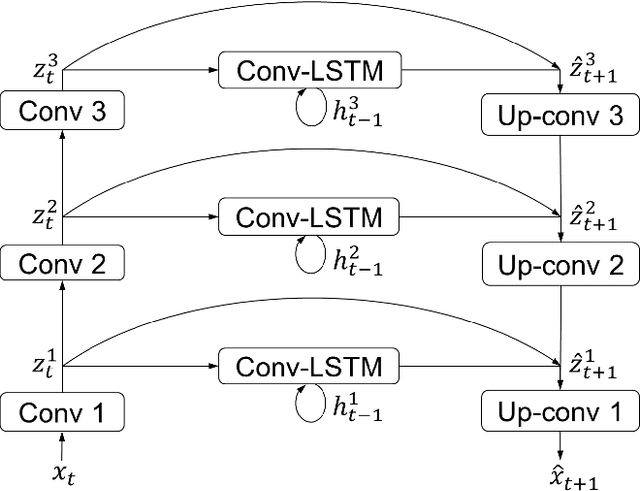
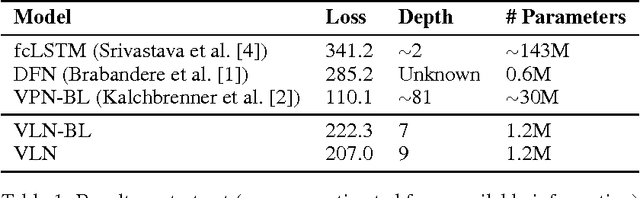
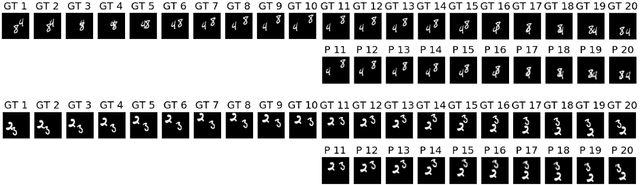
We present the Video Ladder Network (VLN) for efficiently generating future video frames. VLN is a neural encoder-decoder model augmented at all layers by both recurrent and feedforward lateral connections. At each layer, these connections form a lateral recurrent residual block, where the feedforward connection represents a skip connection and the recurrent connection represents the residual. Thanks to the recurrent connections, the decoder can exploit temporal summaries generated from all layers of the encoder. This way, the top layer is relieved from the pressure of modeling lower-level spatial and temporal details. Furthermore, we extend the basic version of VLN to incorporate ResNet-style residual blocks in the encoder and decoder, which help improving the prediction results. VLN is trained in self-supervised regime on the Moving MNIST dataset, achieving competitive results while having very simple structure and providing fast inference.