 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Real-Time Facial Analysis System
Sep 21, 2021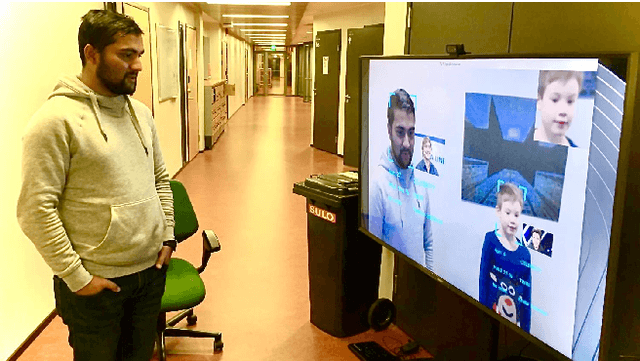
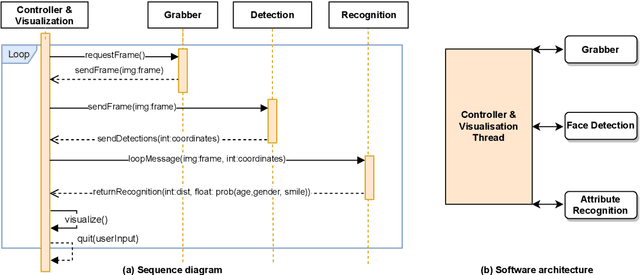
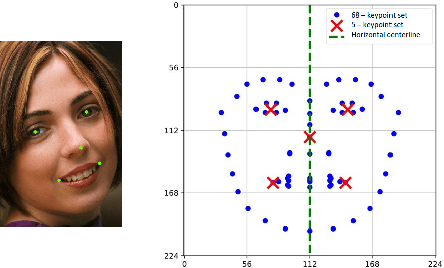
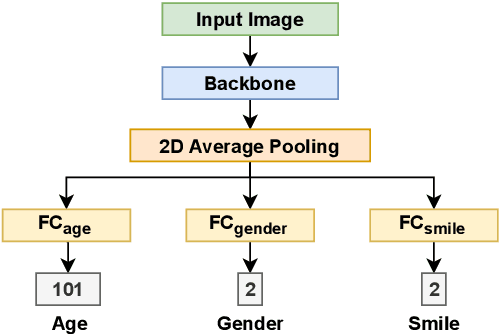
Facial analysis is an active research area in computer vision, with many practical applications. Most of the existing studies focus on addressing one specific task and maximizing its performance. For a complete facial analysis system, one needs to solve these tasks efficiently to ensure a smooth experience. In this work, we present a system-level design of a real-time facial analysis system. With a collection of deep neural networks for object detection, classification, and regression, the system recognizes age, gender, facial expression, and facial similarity for each person that appears in the camera view. We investigate the parallelization and interplay of individual tasks. Results on common off-the-shelf architecture show that the system's accuracy is comparable to the state-of-the-art methods, and the recognition speed satisfies real-time requirements. Moreover, we propose a multitask network for jointly predicting the first three attributes, i.e., age, gender, and facial expression. Source code and trained models are available at https://github.com/mahehu/TUT-live-age-estimator.
Sample selection for efficient image annotation
May 10, 2021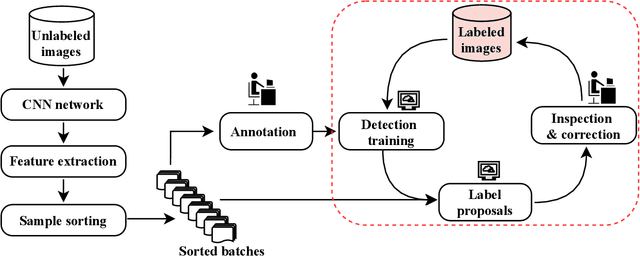

Supervised object detection has been proven to be successful in many benchmark datasets achieving human-level performances. However, acquiring a large amount of labeled image samples for supervised detection training is tedious, time-consuming, and costly. In this paper, we propose an efficient image selection approach that samples the most informative images from the unlabeled dataset and utilizes human-machine collaboration in an iterative train-annotate loop. Image features are extracted by the CNN network followed by the similarity score calculation, Euclidean distance. Unlabeled images are then sampled into different approaches based on the similarity score. The proposed approach is straightforward, simple and sampling takes place prior to the network training. Experiments on datasets show that our method can reduce up to 80% of manual annotation workload, compared to full manual labeling setting, and performs better than random sampling.
Iterative Bounding Box Annotation for Object Detection
Jul 02, 2020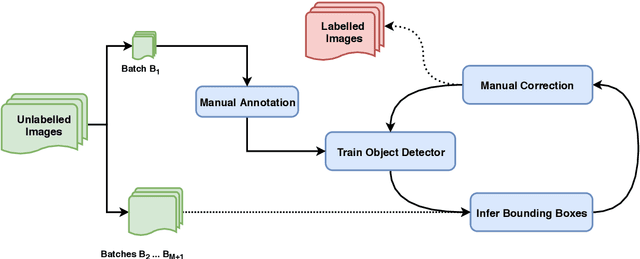
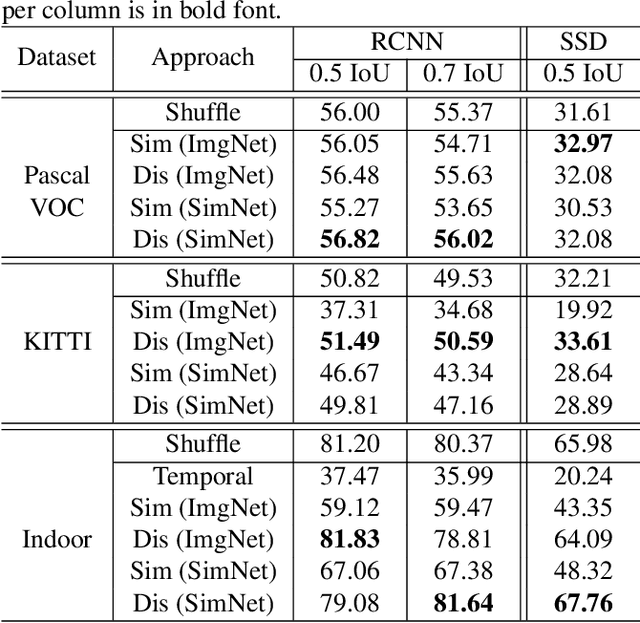
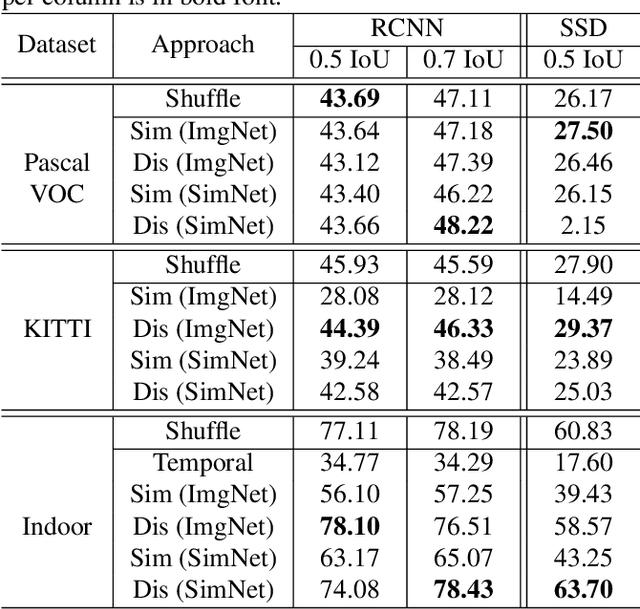
Manual annotation of bounding boxes for object detection in digital images is tedious, and time and resource consuming. In this paper, we propose a semi-automatic method for efficient bounding box annotation. The method trains the object detector iteratively on small batches of labeled images and learns to propose bounding boxes for the next batch, after which the human annotator only needs to correct possible errors. We propose an experimental setup for simulating the human actions and use it for comparing different iteration strategies, such as the order in which the data is presented to the annotator. We experiment on our method with three datasets and show that it can reduce the human annotation effort significantly, saving up to 75% of total manual annotation work.
Real Time System for Facial Analysis
Sep 14, 2018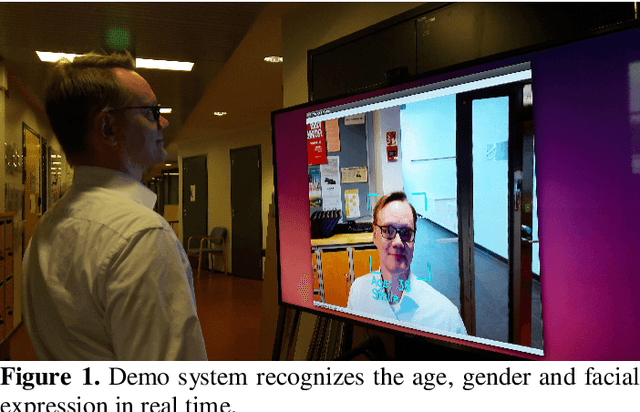
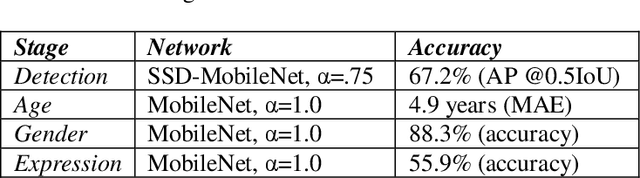
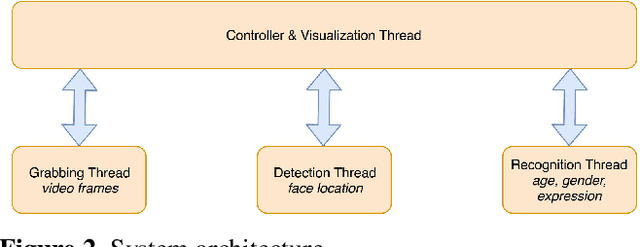
In this paper we describe the anatomy of a real-time facial analysis system. The system recognizes the age, gender and facial expression from users in appearing in front of the camera. All components are based on convolutional neural networks, whose accuracy we study on commonly used training and evaluation sets. A key contribution of the work is the description of the interplay between processing threads for frame grabbing, face detection and the three types of recognition. The python code for executing the system uses common libraries--keras/tensorflow, opencv and dlib--and is available for download.
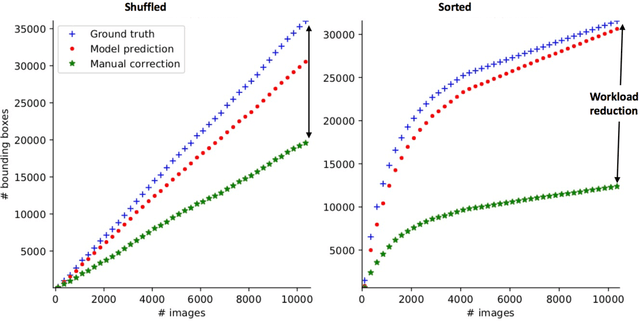
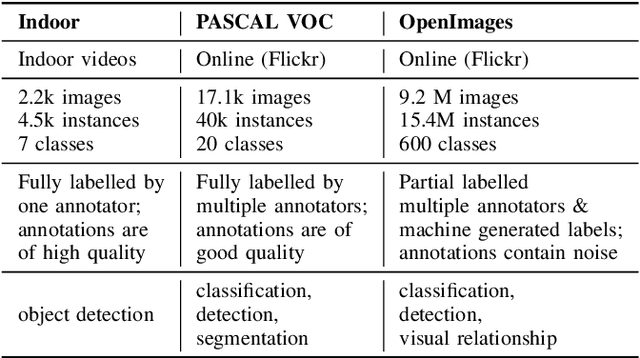
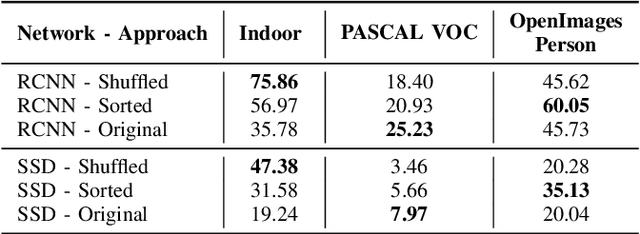
Faster Bounding Box Annotation for Object Detection in Indoor Scenes
Jul 03, 2018

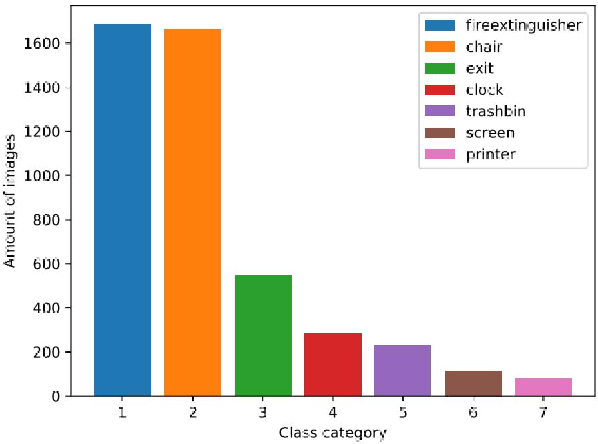
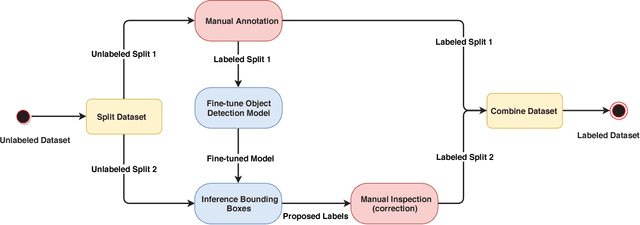
This paper proposes an approach for rapid bounding box annotation for object detection datasets. The procedure consists of two stages: The first step is to annotate a part of the dataset manually, and the second step proposes annotations for the remaining samples using a model trained with the first stage annotations. We experimentally study which first/second stage split minimizes to total workload. In addition, we introduce a new fully labeled object detection dataset collected from indoor scenes. Compared to other indoor datasets, our collection has more class categories, different backgrounds, lighting conditions, occlusion and high intra-class differences. We train deep learning based object detectors with a number of state-of-the-art models and compare them in terms of speed and accuracy. The fully annotated dataset is released freely available for the research community.