 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Bounding Box Annotation for Object Detection
Paper and Code
Jul 02, 2020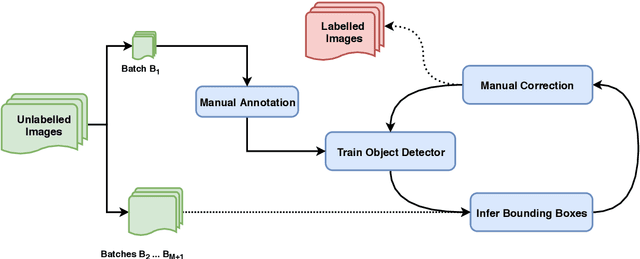
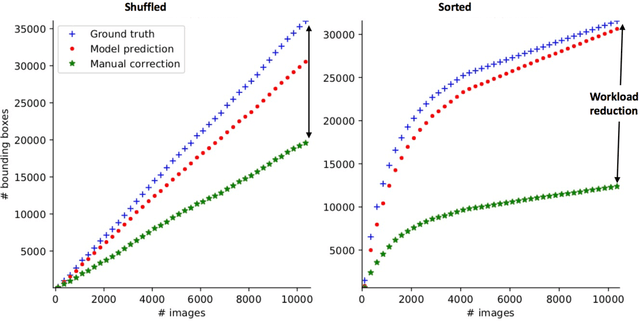
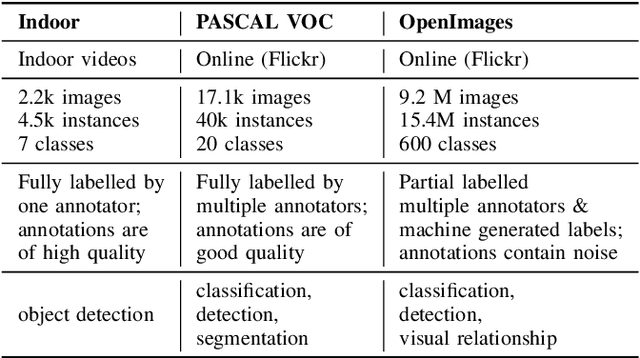
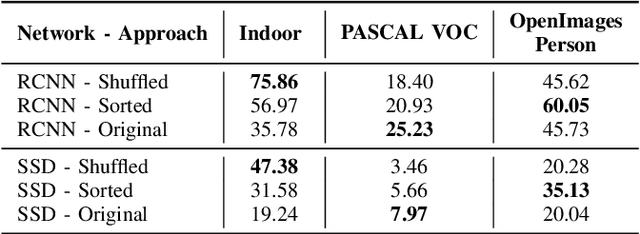
Manual annotation of bounding boxes for object detection in digital images is tedious, and time and resource consuming. In this paper, we propose a semi-automatic method for efficient bounding box annotation. The method trains the object detector iteratively on small batches of labeled images and learns to propose bounding boxes for the next batch, after which the human annotator only needs to correct possible errors. We propose an experimental setup for simulating the human actions and use it for comparing different iteration strategies, such as the order in which the data is presented to the annotator. We experiment on our method with three datasets and show that it can reduce the human annotation effort significantly, saving up to 75% of total manual annotation work.