 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptation and Attention for Neural Video Coding
Dec 16, 2021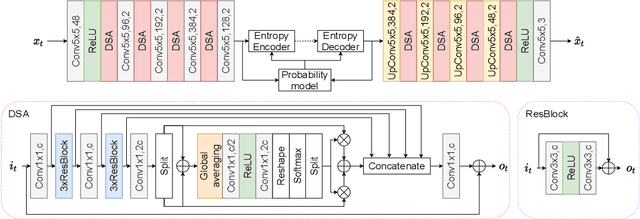
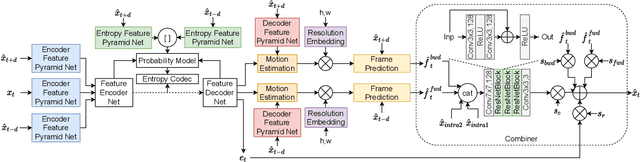
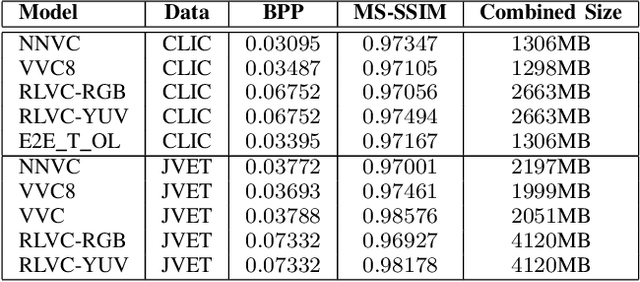
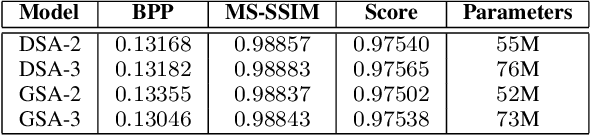
Neural image coding represents now the state-of-the-art image compression approach. However, a lot of work is still to be done in the video domain. In this work, we propose an end-to-end learned video codec that introduces several architectural novelties as well as training novelties, revolving around the concepts of adaptation and attention. Our codec is organized as an intra-frame codec paired with an inter-frame codec. As one architectural novelty, we propose to train the inter-frame codec model to adapt the motion estimation process based on the resolution of the input video. A second architectural novelty is a new neural block that combines concepts from split-attention based neural networks and from DenseNets. Finally, we propose to overfit a set of decoder-side multiplicative parameters at inference time. Through ablation studies and comparisons to prior art, we show the benefits of our proposed techniques in terms of coding gains. We compare our codec to VVC/H.266 and RLVC, which represent the state-of-the-art traditional and end-to-end learned codecs, respectively, and to the top performing end-to-end learned approach in 2021 CLIC competition, E2E_T_OL. Our codec clearly outperforms E2E_T_OL, and compare favorably to VVC and RLVC in some settings.
Lossless Image Compression Using a Multi-Scale Progressive Statistical Model
Aug 24, 2021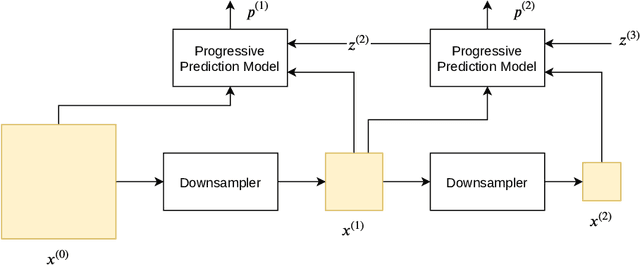

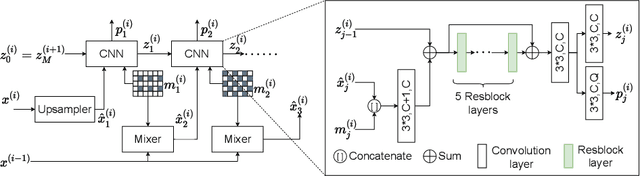

Lossless image compression is an important technique for image storage and transmission when information loss is not allowed. With the fast development of deep learning techniques, deep neural networks have been used in this field to achieve a higher compression rate. Methods based on pixel-wise autoregressive statistical models have shown good performance. However, the sequential processing way prevents these methods to be used in practice. Recently, multi-scale autoregressive models have been proposed to address this limitation. Multi-scale approaches can use parallel computing systems efficiently and build practical systems. Nevertheless, these approaches sacrifice compression performance in exchange for speed. In this paper, we propose a multi-scale progressive statistical model that takes advantage of the pixel-wise approach and the multi-scale approach. We developed a flexible mechanism where the processing order of the pixels can be adjusted easily. Our proposed method outperforms the state-of-the-art lossless image compression methods on two large benchmark datasets by a significant margin without degrading the inference speed dramatically.
L$^2$C -- Learning to Learn to Compress
Jul 31, 2020
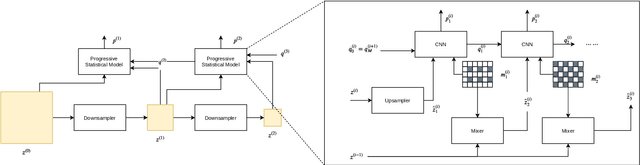

In this paper we present an end-to-end meta-learned system for image compression. Traditional machine learning based approaches to image compression train one or more neural network for generalization performance. However, at inference time, the encoder or the latent tensor output by the encoder can be optimized for each test image. This optimization can be regarded as a form of adaptation or benevolent overfitting to the input content. In order to reduce the gap between training and inference conditions, we propose a new training paradigm for learned image compression, which is based on meta-learning. In a first phase, the neural networks are trained normally. In a second phase, the Model-Agnostic Meta-learning approach is adapted to the specific case of image compression, where the inner-loop performs latent tensor overfitting, and the outer loop updates both encoder and decoder neural networks based on the overfitting performance. Furthermore, after meta-learning, we propose to overfit and cluster the bias terms of the decoder on training image patches, so that at inference time the optimal content-specific bias terms can be selected at encoder-side. Finally, we propose a new probability model for lossless compression, which combines concepts from both multi-scale and super-resolution probability model approaches. We show the benefits of all our proposed ideas via carefully designed experiments.
End-to-End Learning for Video Frame Compression with Self-Attention
Apr 20, 2020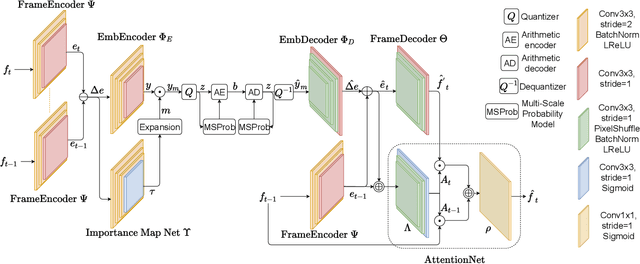
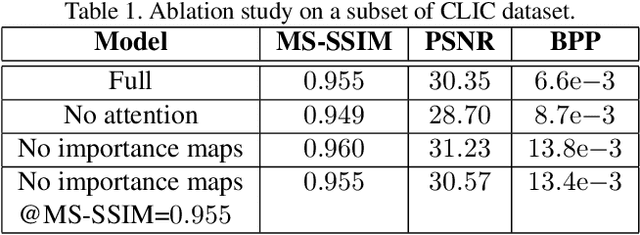

One of the core components of conventional (i.e., non-learned) video codecs consists of predicting a frame from a previously-decoded frame, by leveraging temporal correlations. In this paper, we propose an end-to-end learned system for compressing video frames. Instead of relying on pixel-space motion (as with optical flow), our system learns deep embeddings of frames and encodes their difference in latent space. At decoder-side, an attention mechanism is designed to attend to the latent space of frames to decide how different parts of the previous and current frame are combined to form the final predicted current frame. Spatially-varying channel allocation is achieved by using importance masks acting on the feature-channels. The model is trained to reduce the bitrate by minimizing a loss on importance maps and a loss on the probability output by a context model for arithmetic coding. In our experiments, we show that the proposed system achieves high compression rates and high objective visual quality as measured by MS-SSIM and PSNR. Furthermore, we provide ablation studies where we highlight the contribution of different components.