 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient NeRF Optimization -- Not All Samples Remain Equally Hard
Aug 06, 2024We propose an application of online hard sample mining for efficient training of Neural Radiance Fields (NeRF). NeRF models produce state-of-the-art quality for many 3D reconstruction and rendering tasks but require substantial computational resources. The encoding of the scene information within the NeRF network parameters necessitates stochastic sampling. We observe that during the training, a major part of the compute time and memory usage is spent on processing already learnt samples, which no longer affect the model update significantly. We identify the backward pass on the stochastic samples as the computational bottleneck during the optimization. We thus perform the first forward pass in inference mode as a relatively low-cost search for hard samples. This is followed by building the computational graph and updating the NeRF network parameters using only the hard samples. To demonstrate the effectiveness of the proposed approach, we apply our method to Instant-NGP, resulting in significant improvements of the view-synthesis quality over the baseline (1 dB improvement on average per training time, or 2x speedup to reach the same PSNR level) along with approx. 40% memory savings coming from using only the hard samples to build the computational graph. As our method only interfaces with the network module, we expect it to be widely applicable.
Adaptation and Attention for Neural Video Coding
Dec 16, 2021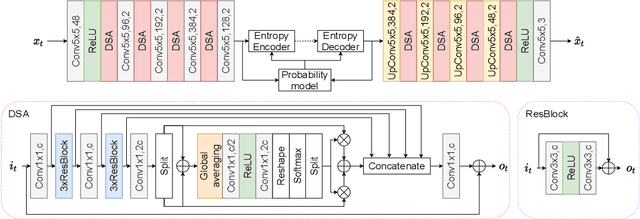
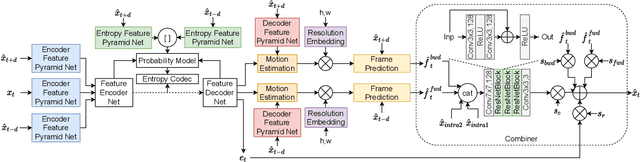
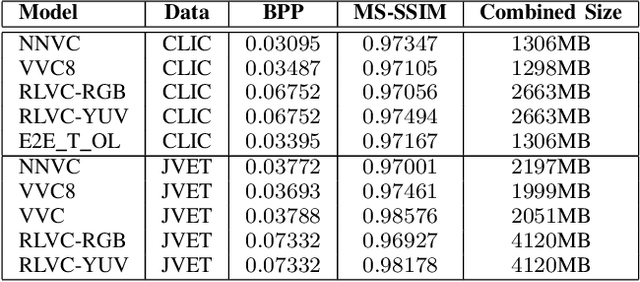
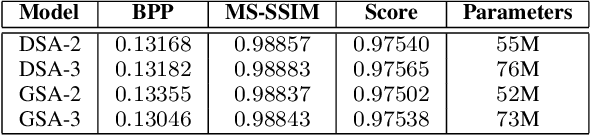
Neural image coding represents now the state-of-the-art image compression approach. However, a lot of work is still to be done in the video domain. In this work, we propose an end-to-end learned video codec that introduces several architectural novelties as well as training novelties, revolving around the concepts of adaptation and attention. Our codec is organized as an intra-frame codec paired with an inter-frame codec. As one architectural novelty, we propose to train the inter-frame codec model to adapt the motion estimation process based on the resolution of the input video. A second architectural novelty is a new neural block that combines concepts from split-attention based neural networks and from DenseNets. Finally, we propose to overfit a set of decoder-side multiplicative parameters at inference time. Through ablation studies and comparisons to prior art, we show the benefits of our proposed techniques in terms of coding gains. We compare our codec to VVC/H.266 and RLVC, which represent the state-of-the-art traditional and end-to-end learned codecs, respectively, and to the top performing end-to-end learned approach in 2021 CLIC competition, E2E_T_OL. Our codec clearly outperforms E2E_T_OL, and compare favorably to VVC and RLVC in some settings.
Lossless Image Compression Using a Multi-Scale Progressive Statistical Model
Aug 24, 2021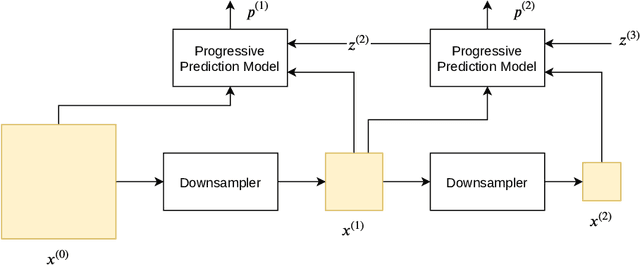

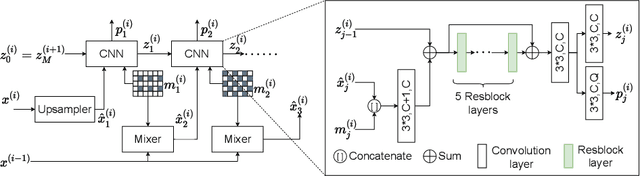

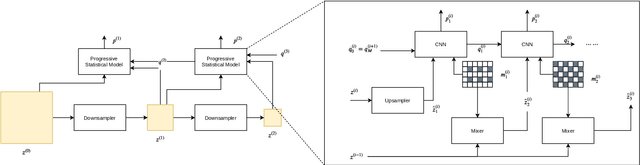
Lossless image compression is an important technique for image storage and transmission when information loss is not allowed. With the fast development of deep learning techniques, deep neural networks have been used in this field to achieve a higher compression rate. Methods based on pixel-wise autoregressive statistical models have shown good performance. However, the sequential processing way prevents these methods to be used in practice. Recently, multi-scale autoregressive models have been proposed to address this limitation. Multi-scale approaches can use parallel computing systems efficiently and build practical systems. Nevertheless, these approaches sacrifice compression performance in exchange for speed. In this paper, we propose a multi-scale progressive statistical model that takes advantage of the pixel-wise approach and the multi-scale approach. We developed a flexible mechanism where the processing order of the pixels can be adjusted easily. Our proposed method outperforms the state-of-the-art lossless image compression methods on two large benchmark datasets by a significant margin without degrading the inference speed dramatically.
Understanding Visual Saliency in Mobile User Interfaces
Jan 22, 2021
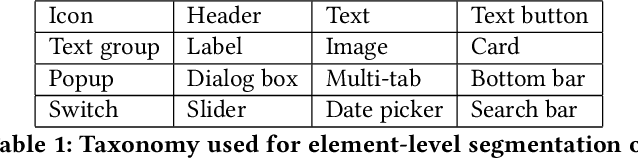
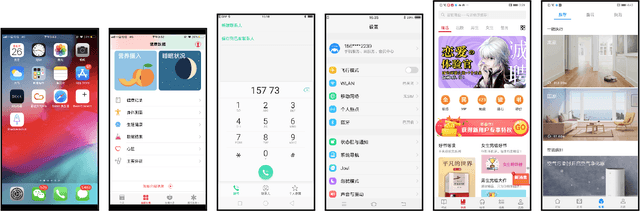

For graphical user interface (UI) design, it is important to understand what attracts visual attention. While previous work on saliency has focused on desktop and web-based UIs, mobile app UIs differ from these in several respects. We present findings from a controlled study with 30 participants and 193 mobile UIs. The results speak to a role of expectations in guiding where users look at. Strong bias toward the top-left corner of the display, text, and images was evident, while bottom-up features such as color or size affected saliency less. Classic, parameter-free saliency models showed a weak fit with the data, and data-driven models improved significantly when trained specifically on this dataset (e.g., NSS rose from 0.66 to 0.84). We also release the first annotated dataset for investigating visual saliency in mobile UIs.
L$^2$C -- Learning to Learn to Compress
Jul 31, 2020
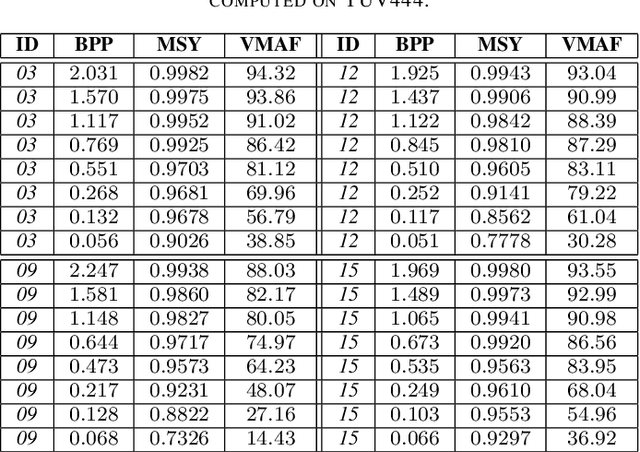

In this paper we present an end-to-end meta-learned system for image compression. Traditional machine learning based approaches to image compression train one or more neural network for generalization performance. However, at inference time, the encoder or the latent tensor output by the encoder can be optimized for each test image. This optimization can be regarded as a form of adaptation or benevolent overfitting to the input content. In order to reduce the gap between training and inference conditions, we propose a new training paradigm for learned image compression, which is based on meta-learning. In a first phase, the neural networks are trained normally. In a second phase, the Model-Agnostic Meta-learning approach is adapted to the specific case of image compression, where the inner-loop performs latent tensor overfitting, and the outer loop updates both encoder and decoder neural networks based on the overfitting performance. Furthermore, after meta-learning, we propose to overfit and cluster the bias terms of the decoder on training image patches, so that at inference time the optimal content-specific bias terms can be selected at encoder-side. Finally, we propose a new probability model for lossless compression, which combines concepts from both multi-scale and super-resolution probability model approaches. We show the benefits of all our proposed ideas via carefully designed experiments.
Image Captioning through Image Transformer
Apr 29, 2020
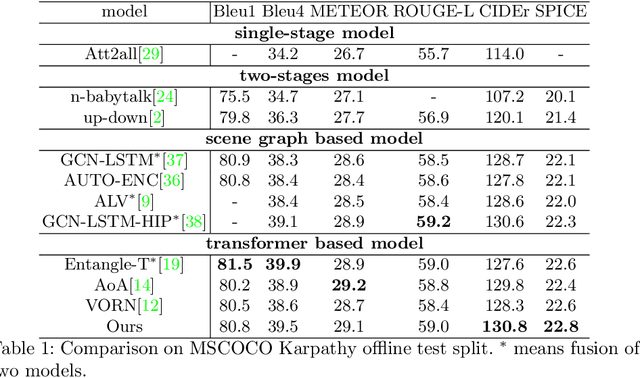
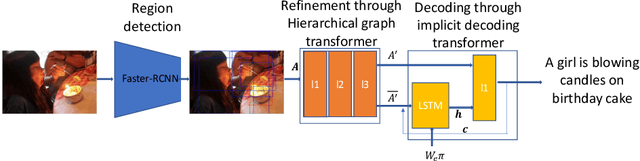
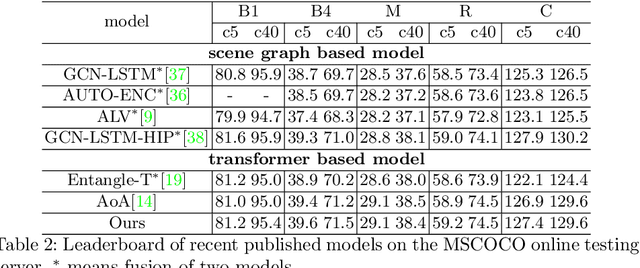
Automatic captioning of images is a task that combines the challenges of image analysis and text generation. One important aspect in captioning is the notion of attention: How to decide what to describe and in which order. Inspired by the successes in text analysis and translation, previous work have proposed the \textit{transformer} architecture for image captioning. However, the structure between the \textit{semantic units} in images (usually the detected regions from object detection model) and sentences (each single word) is different. Limited work has been done to adapt the transformer's internal architecture to images. In this work, we introduce the \textbf{\textit{image transformer}}, which consists of a modified encoding transformer and an implicit decoding transformer, motivated by the relative spatial relationship between image regions. Our design widen the original transformer layer's inner architecture to adapt to the structure of images. With only regions feature as inputs, our model achieves new state-of-the-art performance on both MSCOCO offline and online testing benchmarks.
End-to-End Learning for Video Frame Compression with Self-Attention
Apr 20, 2020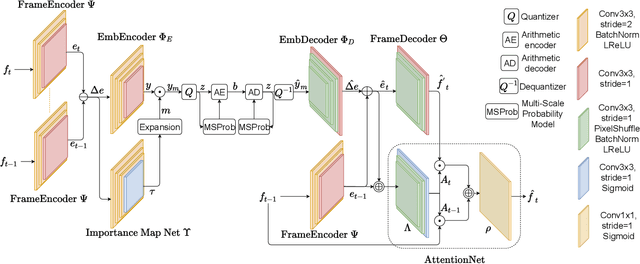
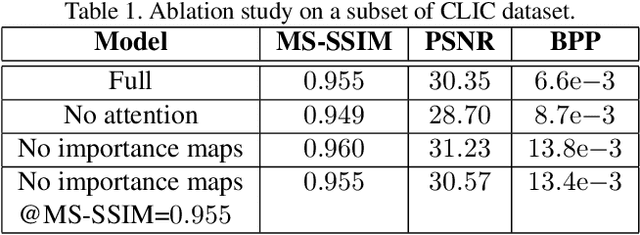

One of the core components of conventional (i.e., non-learned) video codecs consists of predicting a frame from a previously-decoded frame, by leveraging temporal correlations. In this paper, we propose an end-to-end learned system for compressing video frames. Instead of relying on pixel-space motion (as with optical flow), our system learns deep embeddings of frames and encodes their difference in latent space. At decoder-side, an attention mechanism is designed to attend to the latent space of frames to decide how different parts of the previous and current frame are combined to form the final predicted current frame. Spatially-varying channel allocation is achieved by using importance masks acting on the feature-channels. The model is trained to reduce the bitrate by minimizing a loss on importance maps and a loss on the probability output by a context model for arithmetic coding. In our experiments, we show that the proposed system achieves high compression rates and high objective visual quality as measured by MS-SSIM and PSNR. Furthermore, we provide ablation studies where we highlight the contribution of different components.
Deep Saliency Models : The Quest For The Loss Function
Jul 04, 2019

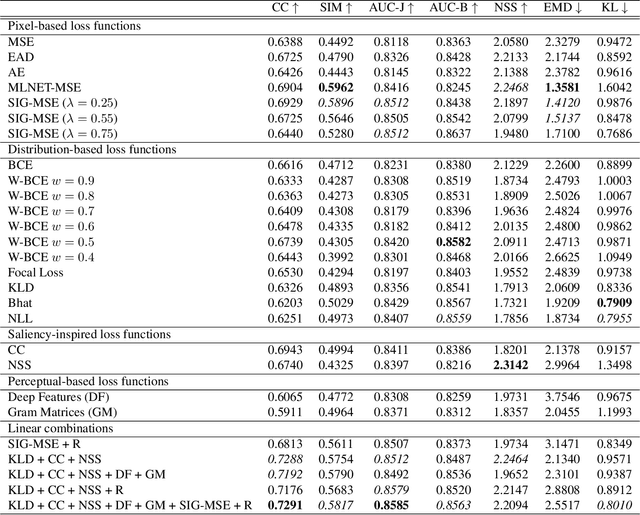
Recent advances in deep learning have pushed the performances of visual saliency models way further than it has ever been. Numerous models in the literature present new ways to design neural networks, to arrange gaze pattern data, or to extract as much high and low-level image features as possible in order to create the best saliency representation. However, one key part of a typical deep learning model is often neglected: the choice of the loss function. In this work, we explore some of the most popular loss functions that are used in deep saliency models. We demonstrate that on a fixed network architecture, modifying the loss function can significantly improve (or depreciate) the results, hence emphasizing the importance of the choice of the loss function when designing a model. We also introduce new loss functions that have never been used for saliency prediction to our knowledge. And finally, we show that a linear combination of several well-chosen loss functions leads to significant improvements in performances on different datasets as well as on a different network architecture, hence demonstrating the robustness of a combined metric.
DAVE: A Deep Audio-Visual Embedding for Dynamic Saliency Prediction
May 25, 2019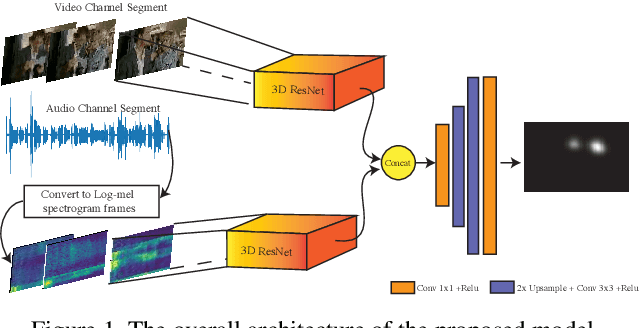
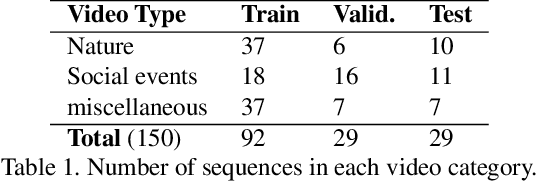
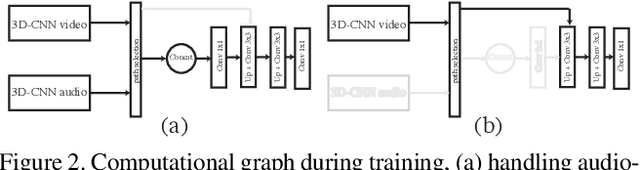
This paper presents a conceptually simple and effective Deep Audio-Visual Eembedding for dynamic saliency prediction dubbed ``DAVE". Several behavioral studies have shown a strong relation between auditory and visual cues for guiding gaze during scene free viewing. The existing video saliency models, however, only consider visual cues for predicting saliency over videos and neglect the auditory information that is ubiquitous in dynamic scenes. We propose a multimodal saliency model that utilizes audio and visual information for predicting saliency in videos. Our model consists of a two-stream encoder and a decoder. First, auditory and visual information are mapped into a feature space using 3D Convolutional Neural Networks (3D CNNs). Then, a decoder combines the features and maps them to a final saliency map. To train such model, data from various eye tracking datasets containing video and audio are pulled together. We further categorised videos into `social', `nature', and `miscellaneous' classes to analyze the models over different content types. Several analyses show that our audio-visual model outperforms video-based models significantly over all scores; overall and over individual categories. Contextual analysis of the model performance over the location of sound source reveals that the audio-visual model behaves similar to humans in attending to the location of sound source. Our endeavour demonstrates that audio is an important signal that can boost video saliency prediction and help getting closer to human performance.
Geometric Image Correspondence Verification by Dense Pixel Matching
Apr 15, 2019

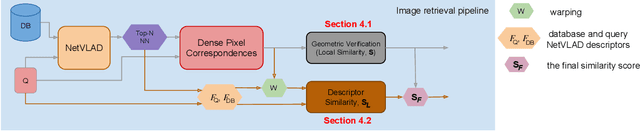
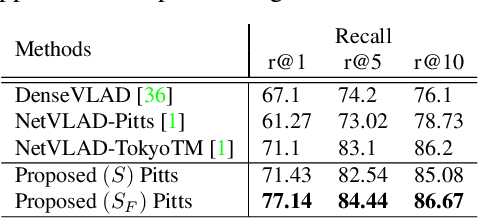
This paper addresses the problem of determining dense pixel correspondences between two images and its application to geometric correspondence verification in image retrieval. The main contribution is a geometric correspondence verification approach for re-ranking a shortlist of retrieved database images based on their dense pair-wise matching with the query image at a pixel level. We determine a set of cyclically consistent dense pixel matches between the pair of images and evaluate local similarity of matched pixels using neural network based image descriptors. Final re-ranking is based on a novel similarity function, which fuses the local similarity metric with a global similarity metric and a geometric consistency measure computed for the matched pixels. For dense matching our approach utilizes a modified version of a recently proposed dense geometric correspondence network (DGC-Net), which we also improve by optimizing the architecture. The proposed model and similarity metric compare favourably to the state-of-the-art image retrieval methods. In addition, we apply our method to the problem of long-term visual localization demonstrating promising results and generalization across datasets.