 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGTAvatar: Bridging Gaussian Splatting and Texture Mapping for Relightable and Editable Gaussian Avatars
Dec 09, 2025



Recent advancements in Gaussian Splatting have enabled increasingly accurate reconstruction of photorealistic head avatars, opening the door to numerous applications in visual effects, videoconferencing, and virtual reality. This, however, comes with the lack of intuitive editability offered by traditional triangle mesh-based methods. In contrast, we propose a method that combines the accuracy and fidelity of 2D Gaussian Splatting with the intuitiveness of UV texture mapping. By embedding each canonical Gaussian primitive's local frame into a patch in the UV space of a template mesh in a computationally efficient manner, we reconstruct continuous editable material head textures from a single monocular video on a conventional UV domain. Furthermore, we leverage an efficient physically based reflectance model to enable relighting and editing of these intrinsic material maps. Through extensive comparisons with state-of-the-art methods, we demonstrate the accuracy of our reconstructions, the quality of our relighting results, and the ability to provide intuitive controls for modifying an avatar's appearance and geometry via texture mapping without additional optimization.
Pulp Motion: Framing-aware multimodal camera and human motion generation
Oct 06, 2025Treating human motion and camera trajectory generation separately overlooks a core principle of cinematography: the tight interplay between actor performance and camera work in the screen space. In this paper, we are the first to cast this task as a text-conditioned joint generation, aiming to maintain consistent on-screen framing while producing two heterogeneous, yet intrinsically linked, modalities: human motion and camera trajectories. We propose a simple, model-agnostic framework that enforces multimodal coherence via an auxiliary modality: the on-screen framing induced by projecting human joints onto the camera. This on-screen framing provides a natural and effective bridge between modalities, promoting consistency and leading to more precise joint distribution. We first design a joint autoencoder that learns a shared latent space, together with a lightweight linear transform from the human and camera latents to a framing latent. We then introduce auxiliary sampling, which exploits this linear transform to steer generation toward a coherent framing modality. To support this task, we also introduce the PulpMotion dataset, a human-motion and camera-trajectory dataset with rich captions, and high-quality human motions. Extensive experiments across DiT- and MAR-based architectures show the generality and effectiveness of our method in generating on-frame coherent human-camera motions, while also achieving gains on textual alignment for both modalities. Our qualitative results yield more cinematographically meaningful framings setting the new state of the art for this task. Code, models and data are available in our \href{https://www.lix.polytechnique.fr/vista/projects/2025_pulpmotion_courant/}{project page}.
AKiRa: Augmentation Kit on Rays for optical video generation
Dec 18, 2024Recent advances in text-conditioned video diffusion have greatly improved video quality. However, these methods offer limited or sometimes no control to users on camera aspects, including dynamic camera motion, zoom, distorted lens and focus shifts. These motion and optical aspects are crucial for adding controllability and cinematic elements to generation frameworks, ultimately resulting in visual content that draws focus, enhances mood, and guides emotions according to filmmakers' controls. In this paper, we aim to close the gap between controllable video generation and camera optics. To achieve this, we propose AKiRa (Augmentation Kit on Rays), a novel augmentation framework that builds and trains a camera adapter with a complex camera model over an existing video generation backbone. It enables fine-tuned control over camera motion as well as complex optical parameters (focal length, distortion, aperture) to achieve cinematic effects such as zoom, fisheye effect, and bokeh. Extensive experiments demonstrate AKiRa's effectiveness in combining and composing camera optics while outperforming all state-of-the-art methods. This work sets a new landmark in controlled and optically enhanced video generation, paving the way for future optical video generation methods.
SPARK: Self-supervised Personalized Real-time Monocular Face Capture
Sep 12, 2024
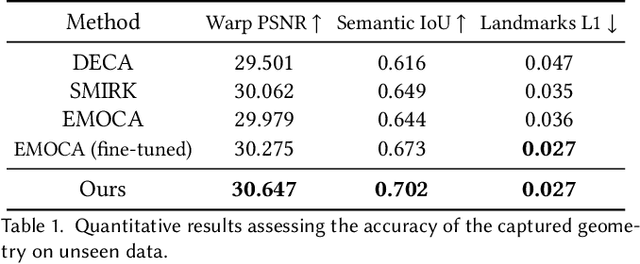
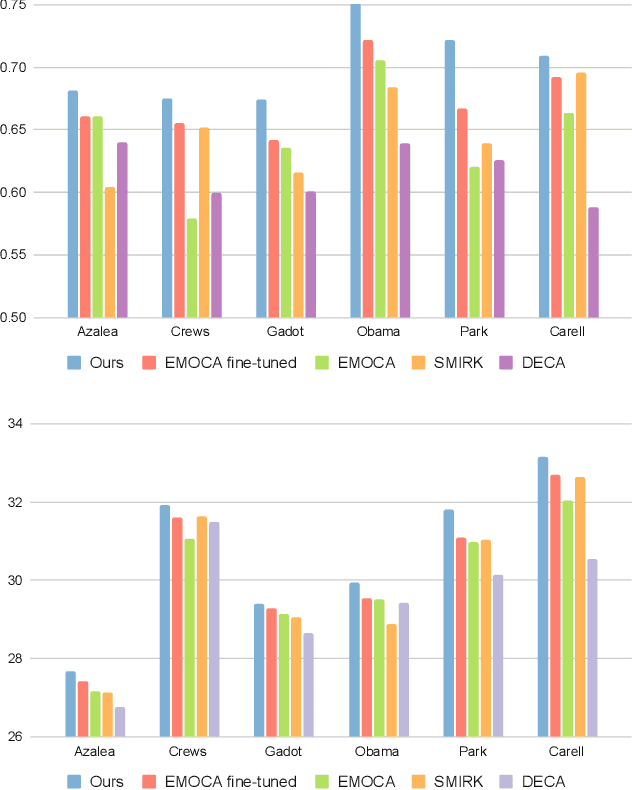
Feedforward monocular face capture methods seek to reconstruct posed faces from a single image of a person. Current state of the art approaches have the ability to regress parametric 3D face models in real-time across a wide range of identities, lighting conditions and poses by leveraging large image datasets of human faces. These methods however suffer from clear limitations in that the underlying parametric face model only provides a coarse estimation of the face shape, thereby limiting their practical applicability in tasks that require precise 3D reconstruction (aging, face swapping, digital make-up, ...). In this paper, we propose a method for high-precision 3D face capture taking advantage of a collection of unconstrained videos of a subject as prior information. Our proposal builds on a two stage approach. We start with the reconstruction of a detailed 3D face avatar of the person, capturing both precise geometry and appearance from a collection of videos. We then use the encoder from a pre-trained monocular face reconstruction method, substituting its decoder with our personalized model, and proceed with transfer learning on the video collection. Using our pre-estimated image formation model, we obtain a more precise self-supervision objective, enabling improved expression and pose alignment. This results in a trained encoder capable of efficiently regressing pose and expression parameters in real-time from previously unseen images, which combined with our personalized geometry model yields more accurate and high fidelity mesh inference. Through extensive qualitative and quantitative evaluation, we showcase the superiority of our final model as compared to state-of-the-art baselines, and demonstrate its generalization ability to unseen pose, expression and lighting.
* SIGGRAPH Asia 2024 Conference Paper. Project page: https://kelianb.github.io/SPARK/
E.T. the Exceptional Trajectories: Text-to-camera-trajectory generation with character awareness
Jul 01, 2024



Stories and emotions in movies emerge through the effect of well-thought-out directing decisions, in particular camera placement and movement over time. Crafting compelling camera trajectories remains a complex iterative process, even for skilful artists. To tackle this, in this paper, we propose a dataset called the Exceptional Trajectories (E.T.) with camera trajectories along with character information and textual captions encompassing descriptions of both camera and character. To our knowledge, this is the first dataset of its kind. To show the potential applications of the E.T. dataset, we propose a diffusion-based approach, named DIRECTOR, which generates complex camera trajectories from textual captions that describe the relation and synchronisation between the camera and characters. To ensure robust and accurate evaluations, we train on the E.T. dataset CLaTr, a Contrastive Language-Trajectory embedding for evaluation metrics. We posit that our proposed dataset and method significantly advance the democratization of cinematography, making it more accessible to common users.
BluNF: Blueprint Neural Field
Sep 07, 2023Neural Radiance Fields (NeRFs) have revolutionized scene novel view synthesis, offering visually realistic, precise, and robust implicit reconstructions. While recent approaches enable NeRF editing, such as object removal, 3D shape modification, or material property manipulation, the manual annotation prior to such edits makes the process tedious. Additionally, traditional 2D interaction tools lack an accurate sense of 3D space, preventing precise manipulation and editing of scenes. In this paper, we introduce a novel approach, called Blueprint Neural Field (BluNF), to address these editing issues. BluNF provides a robust and user-friendly 2D blueprint, enabling intuitive scene editing. By leveraging implicit neural representation, BluNF constructs a blueprint of a scene using prior semantic and depth information. The generated blueprint allows effortless editing and manipulation of NeRF representations. We demonstrate BluNF's editability through an intuitive click-and-change mechanism, enabling 3D manipulations, such as masking, appearance modification, and object removal. Our approach significantly contributes to visual content creation, paving the way for further research in this area.
JAWS: Just A Wild Shot for Cinematic Transfer in Neural Radiance Fields
Mar 27, 2023



This paper presents JAWS, an optimization-driven approach that achieves the robust transfer of visual cinematic features from a reference in-the-wild video clip to a newly generated clip. To this end, we rely on an implicit-neural-representation (INR) in a way to compute a clip that shares the same cinematic features as the reference clip. We propose a general formulation of a camera optimization problem in an INR that computes extrinsic and intrinsic camera parameters as well as timing. By leveraging the differentiability of neural representations, we can back-propagate our designed cinematic losses measured on proxy estimators through a NeRF network to the proposed cinematic parameters directly. We also introduce specific enhancements such as guidance maps to improve the overall quality and efficiency. Results display the capacity of our system to replicate well known camera sequences from movies, adapting the framing, camera parameters and timing of the generated video clip to maximize the similarity with the reference clip.
Where to look at the movies : Analyzing visual attention to understand movie editing
Feb 26, 2021
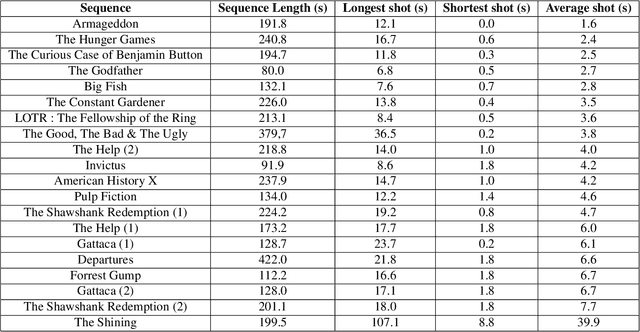


In the process of making a movie, directors constantly care about where the spectator will look on the screen. Shot composition, framing, camera movements or editing are tools commonly used to direct attention. In order to provide a quantitative analysis of the relationship between those tools and gaze patterns, we propose a new eye-tracking database, containing gaze pattern information on movie sequences, as well as editing annotations, and we show how state-of-the-art computational saliency techniques behave on this dataset. In this work, we expose strong links between movie editing and spectators scanpaths, and open several leads on how the knowledge of editing information could improve human visual attention modeling for cinematic content. The dataset generated and analysed during the current study is available at https://github.com/abruckert/eye_tracking_filmmaking
Deep Saliency Models : The Quest For The Loss Function
Jul 04, 2019

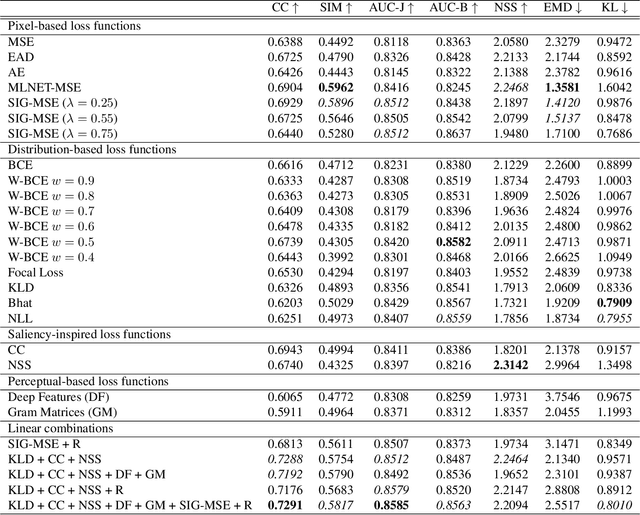
Recent advances in deep learning have pushed the performances of visual saliency models way further than it has ever been. Numerous models in the literature present new ways to design neural networks, to arrange gaze pattern data, or to extract as much high and low-level image features as possible in order to create the best saliency representation. However, one key part of a typical deep learning model is often neglected: the choice of the loss function. In this work, we explore some of the most popular loss functions that are used in deep saliency models. We demonstrate that on a fixed network architecture, modifying the loss function can significantly improve (or depreciate) the results, hence emphasizing the importance of the choice of the loss function when designing a model. We also introduce new loss functions that have never been used for saliency prediction to our knowledge. And finally, we show that a linear combination of several well-chosen loss functions leads to significant improvements in performances on different datasets as well as on a different network architecture, hence demonstrating the robustness of a combined metric.
Directing Cinematographic Drones
Dec 14, 2017
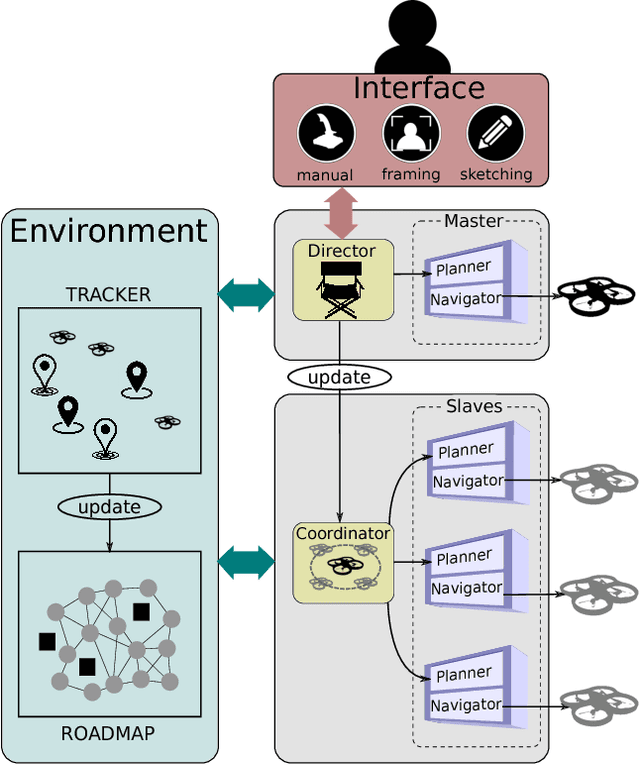

Quadrotor drones equipped with high quality cameras have rapidely raised as novel, cheap and stable devices for filmmakers. While professional drone pilots can create aesthetically pleasing videos in short time, the smooth -- and cinematographic -- control of a camera drone remains challenging for most users, despite recent tools that either automate part of the process or enable the manual design of waypoints to create drone trajectories. This paper proposes to move a step further towards more accessible cinematographic drones by designing techniques to automatically or interactively plan quadrotor drone motions in 3D dynamic environments that satisfy both cinematographic and physical quadrotor constraints. We first propose the design of a Drone Toric Space as a dedicated camera parameter space with embedded constraints and derive some intuitive on-screen viewpoint manipulators. Second, we propose a specific path planning technique which ensures both that cinematographic properties can be enforced along the path, and that the path is physically feasible by a quadrotor drone. At last, we build on the Drone Toric Space and the specific path planning technique to coordinate the motion of multiple drones around dynamic targets. A number of results then demonstrate the interactive and automated capacities of our approaches on a number of use-cases.