 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenLit: Reformulating Single-Image Relighting as Video Generation
Dec 15, 2024
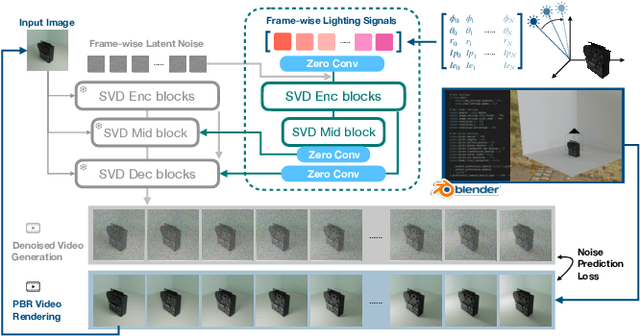

Manipulating the illumination within a single image represents a fundamental challenge in computer vision and graphics. This problem has been traditionally addressed using inverse rendering techniques, which require explicit 3D asset reconstruction and costly ray tracing simulations. Meanwhile, recent advancements in visual foundation models suggest that a new paradigm could soon be practical and possible -- one that replaces explicit physical models with networks that are trained on massive amounts of image and video data. In this paper, we explore the potential of exploiting video diffusion models, and in particular Stable Video Diffusion (SVD), in understanding the physical world to perform relighting tasks given a single image. Specifically, we introduce GenLit, a framework that distills the ability of a graphics engine to perform light manipulation into a video generation model, enabling users to directly insert and manipulate a point light in the 3D world within a given image and generate the results directly as a video sequence. We find that a model fine-tuned on only a small synthetic dataset (270 objects) is able to generalize to real images, enabling single-image relighting with realistic ray tracing effects and cast shadows. These results reveal the ability of video foundation models to capture rich information about lighting, material, and shape. Our findings suggest that such models, with minimal training, can be used for physically-based rendering without explicit physically asset reconstruction and complex ray tracing. This further suggests the potential of such models for controllable and physically accurate image synthesis tasks.
SPARK: Self-supervised Personalized Real-time Monocular Face Capture
Sep 12, 2024
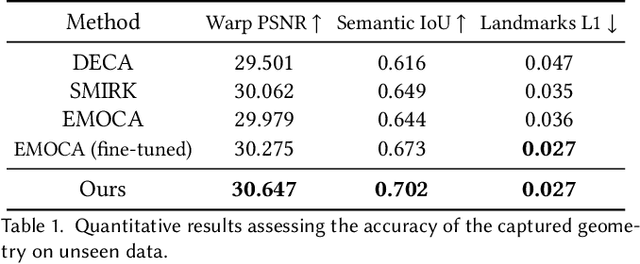
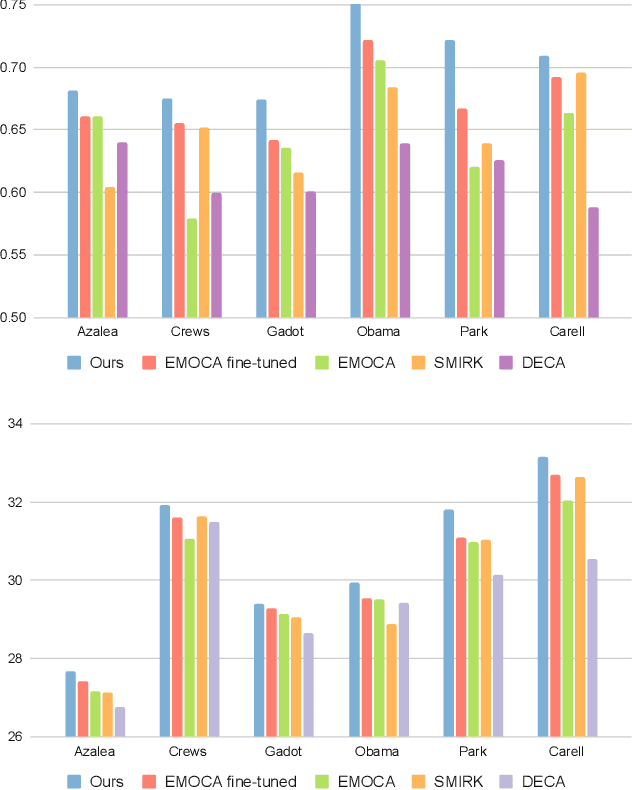
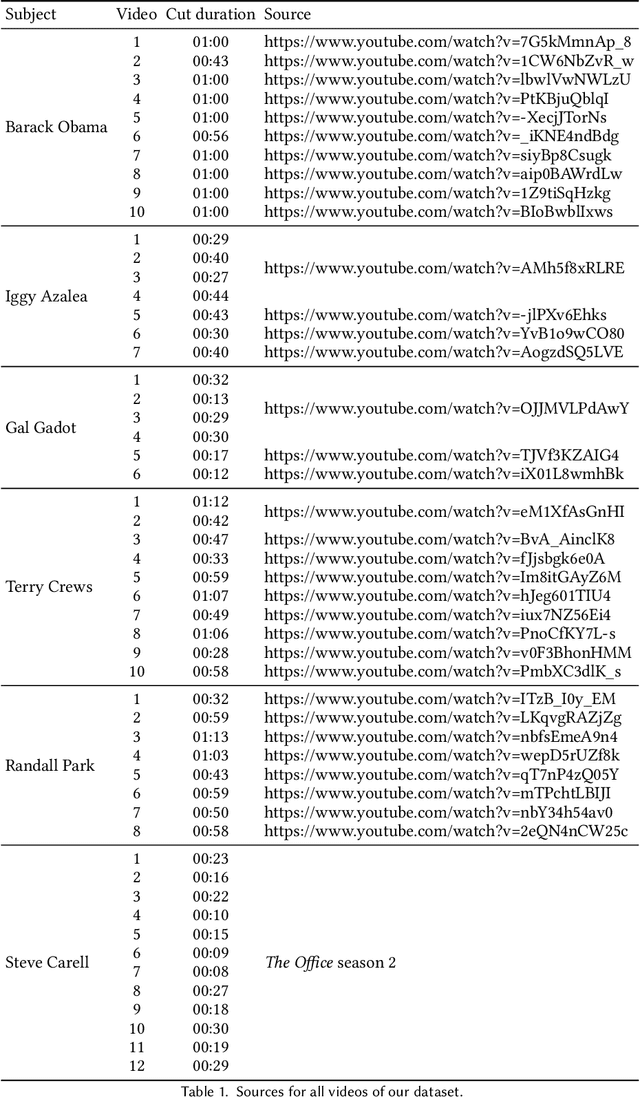
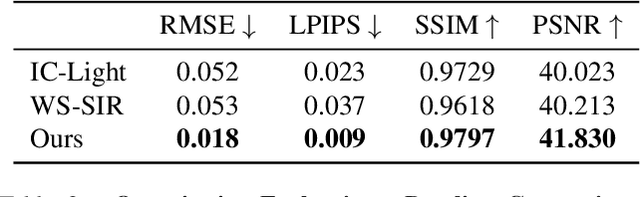
Feedforward monocular face capture methods seek to reconstruct posed faces from a single image of a person. Current state of the art approaches have the ability to regress parametric 3D face models in real-time across a wide range of identities, lighting conditions and poses by leveraging large image datasets of human faces. These methods however suffer from clear limitations in that the underlying parametric face model only provides a coarse estimation of the face shape, thereby limiting their practical applicability in tasks that require precise 3D reconstruction (aging, face swapping, digital make-up, ...). In this paper, we propose a method for high-precision 3D face capture taking advantage of a collection of unconstrained videos of a subject as prior information. Our proposal builds on a two stage approach. We start with the reconstruction of a detailed 3D face avatar of the person, capturing both precise geometry and appearance from a collection of videos. We then use the encoder from a pre-trained monocular face reconstruction method, substituting its decoder with our personalized model, and proceed with transfer learning on the video collection. Using our pre-estimated image formation model, we obtain a more precise self-supervision objective, enabling improved expression and pose alignment. This results in a trained encoder capable of efficiently regressing pose and expression parameters in real-time from previously unseen images, which combined with our personalized geometry model yields more accurate and high fidelity mesh inference. Through extensive qualitative and quantitative evaluation, we showcase the superiority of our final model as compared to state-of-the-art baselines, and demonstrate its generalization ability to unseen pose, expression and lighting.
* SIGGRAPH Asia 2024 Conference Paper. Project page: https://kelianb.github.io/SPARK/
FLARE: Fast Learning of Animatable and Relightable Mesh Avatars
Oct 27, 2023Our goal is to efficiently learn personalized animatable 3D head avatars from videos that are geometrically accurate, realistic, relightable, and compatible with current rendering systems. While 3D meshes enable efficient processing and are highly portable, they lack realism in terms of shape and appearance. Neural representations, on the other hand, are realistic but lack compatibility and are slow to train and render. Our key insight is that it is possible to efficiently learn high-fidelity 3D mesh representations via differentiable rendering by exploiting highly-optimized methods from traditional computer graphics and approximating some of the components with neural networks. To that end, we introduce FLARE, a technique that enables the creation of animatable and relightable mesh avatars from a single monocular video. First, we learn a canonical geometry using a mesh representation, enabling efficient differentiable rasterization and straightforward animation via learned blendshapes and linear blend skinning weights. Second, we follow physically-based rendering and factor observed colors into intrinsic albedo, roughness, and a neural representation of the illumination, allowing the learned avatars to be relit in novel scenes. Since our input videos are captured on a single device with a narrow field of view, modeling the surrounding environment light is non-trivial. Based on the split-sum approximation for modeling specular reflections, we address this by approximating the pre-filtered environment map with a multi-layer perceptron (MLP) modulated by the surface roughness, eliminating the need to explicitly model the light. We demonstrate that our mesh-based avatar formulation, combined with learned deformation, material, and lighting MLPs, produces avatars with high-quality geometry and appearance, while also being efficient to train and render compared to existing approaches.
* 15 pages, Accepted: ACM Transactions on Graphics (Proceedings of SIGGRAPH Asia), 2023
What happens when self-supervision meets Noisy Labels?
Oct 26, 2019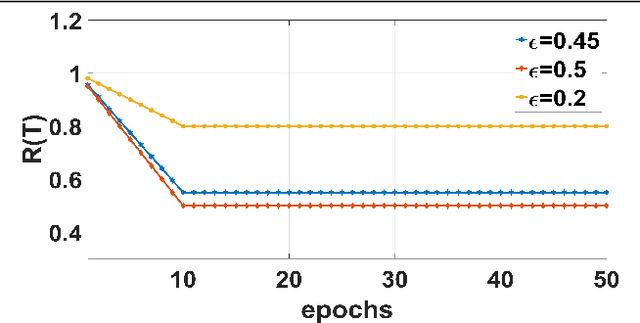
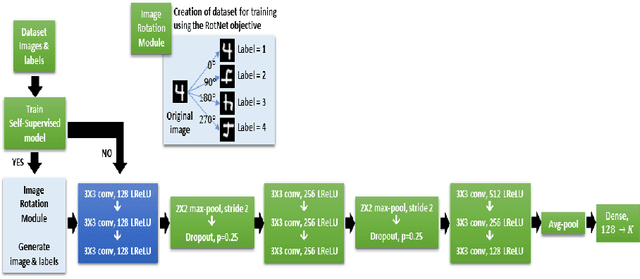
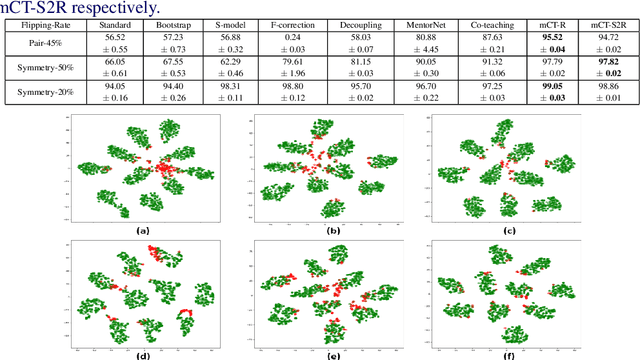

The major driving force behind the immense success of deep learning models is the availability of large datasets along with their clean labels. Unfortunately, this is very difficult to obtain, which has motivated research on the training of deep models in the presence of label noise and ways to avoid over-fitting on the noisy labels. In this work, we build upon the seminal work in this area, Co-teaching and propose a simple, yet efficient approach termed mCT-S2R (modified co-teaching with self-supervision and re-labeling) for this task. First, to deal with significant amount of noise in the labels, we propose to use self-supervision to generate robust features without using any labels. Next, using a parallel network architecture, an estimate of the clean labeled portion of the data is obtained. Finally, using this data, a portion of the estimated noisy labeled portion is re-labeled, before resuming the network training with the augmented data. Extensive experiments on three standard datasets show the effectiveness of the proposed framework.