 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-AP Cooperative Beamforming for Cell-Free ISAC Networks: Balancing Communication SINR and Sensing SCNR
May 06, 2026Cell-free integrated sensing and communication (ISAC) systems are facing the resource allocation challenges due to the deployment of access points (APs) and conflicting beamforming requirements between the communication and sensing functions. Unlike traditional ISAC architectures, the geographic distribution of APs introduces coordination complexity and resource-sharing conflicts that existing single-objective methods cannot adequately address. To address this challenge, we formulate an optimization problem for multi-AP cooperative beamforming that maximizes the sensing signal-to-clutter-plus-noise ratio (SCNR) under the communication rate constraints. The non-convex quadratically constrained quadratic program is transformed into a tractable convex semidefinite program via semidefinite relaxation, enabling efficient polynomial-time solutions and overcoming the local convergence limitations of traditional alternating optimization approaches. Simulation results demonstrate that the proposed approach achieves superior performance in both communication signal-to-interference-plus-noise ratio (SINR) and SCNR compared to existing schemes, confirming its effectiveness for balancing dual-functional objectives.
LOLA: LLM-Assisted Online Learning Algorithm for Content Experiments
Jun 03, 2024



In the rapidly evolving digital content landscape, media firms and news publishers require automated and efficient methods to enhance user engagement. This paper introduces the LLM-Assisted Online Learning Algorithm (LOLA), a novel framework that integrates Large Language Models (LLMs) with adaptive experimentation to optimize content delivery. Leveraging a large-scale dataset from Upworthy, which includes 17,681 headline A/B tests aimed at evaluating the performance of various headlines associated with the same article content, we first investigate three broad pure-LLM approaches: prompt-based methods, embedding-based classification models, and fine-tuned open-source LLMs. Our findings indicate that prompt-based approaches perform poorly, achieving no more than 65% accuracy in identifying the catchier headline among two options. In contrast, OpenAI-embedding-based classification models and fine-tuned Llama-3-8b models achieve comparable accuracy, around 82-84%, though still falling short of the performance of experimentation with sufficient traffic. We then introduce LOLA, which combines the best pure-LLM approach with the Upper Confidence Bound algorithm to adaptively allocate traffic and maximize clicks. Our numerical experiments on Upworthy data show that LOLA outperforms the standard A/B testing method (the current status quo at Upworthy), pure bandit algorithms, and pure-LLM approaches, particularly in scenarios with limited experimental traffic or numerous arms. Our approach is both scalable and broadly applicable to content experiments across a variety of digital settings where firms seek to optimize user engagement, including digital advertising and social media recommendations.
A Unified Approach for Text- and Image-guided 4D Scene Generation
Nov 29, 2023Large-scale diffusion generative models are greatly simplifying image, video and 3D asset creation from user-provided text prompts and images. However, the challenging problem of text-to-4D dynamic 3D scene generation with diffusion guidance remains largely unexplored. We propose Dream-in-4D, which features a novel two-stage approach for text-to-4D synthesis, leveraging (1) 3D and 2D diffusion guidance to effectively learn a high-quality static 3D asset in the first stage; (2) a deformable neural radiance field that explicitly disentangles the learned static asset from its deformation, preserving quality during motion learning; and (3) a multi-resolution feature grid for the deformation field with a displacement total variation loss to effectively learn motion with video diffusion guidance in the second stage. Through a user preference study, we demonstrate that our approach significantly advances image and motion quality, 3D consistency and text fidelity for text-to-4D generation compared to baseline approaches. Thanks to its motion-disentangled representation, Dream-in-4D can also be easily adapted for controllable generation where appearance is defined by one or multiple images, without the need to modify the motion learning stage. Thus, our method offers, for the first time, a unified approach for text-to-4D, image-to-4D and personalized 4D generation tasks.
FLARE: Fast Learning of Animatable and Relightable Mesh Avatars
Oct 27, 2023Our goal is to efficiently learn personalized animatable 3D head avatars from videos that are geometrically accurate, realistic, relightable, and compatible with current rendering systems. While 3D meshes enable efficient processing and are highly portable, they lack realism in terms of shape and appearance. Neural representations, on the other hand, are realistic but lack compatibility and are slow to train and render. Our key insight is that it is possible to efficiently learn high-fidelity 3D mesh representations via differentiable rendering by exploiting highly-optimized methods from traditional computer graphics and approximating some of the components with neural networks. To that end, we introduce FLARE, a technique that enables the creation of animatable and relightable mesh avatars from a single monocular video. First, we learn a canonical geometry using a mesh representation, enabling efficient differentiable rasterization and straightforward animation via learned blendshapes and linear blend skinning weights. Second, we follow physically-based rendering and factor observed colors into intrinsic albedo, roughness, and a neural representation of the illumination, allowing the learned avatars to be relit in novel scenes. Since our input videos are captured on a single device with a narrow field of view, modeling the surrounding environment light is non-trivial. Based on the split-sum approximation for modeling specular reflections, we address this by approximating the pre-filtered environment map with a multi-layer perceptron (MLP) modulated by the surface roughness, eliminating the need to explicitly model the light. We demonstrate that our mesh-based avatar formulation, combined with learned deformation, material, and lighting MLPs, produces avatars with high-quality geometry and appearance, while also being efficient to train and render compared to existing approaches.
* 15 pages, Accepted: ACM Transactions on Graphics (Proceedings of SIGGRAPH Asia), 2023
An Adaptive Deep RL Method for Non-Stationary Environments with Piecewise Stable Context
Dec 24, 2022One of the key challenges in deploying RL to real-world applications is to adapt to variations of unknown environment contexts, such as changing terrains in robotic tasks and fluctuated bandwidth in congestion control. Existing works on adaptation to unknown environment contexts either assume the contexts are the same for the whole episode or assume the context variables are Markovian. However, in many real-world applications, the environment context usually stays stable for a stochastic period and then changes in an abrupt and unpredictable manner within an episode, resulting in a segment structure, which existing works fail to address. To leverage the segment structure of piecewise stable context in real-world applications, in this paper, we propose a \textit{\textbf{Se}gmented \textbf{C}ontext \textbf{B}elief \textbf{A}ugmented \textbf{D}eep~(SeCBAD)} RL method. Our method can jointly infer the belief distribution over latent context with the posterior over segment length and perform more accurate belief context inference with observed data within the current context segment. The inferred belief context can be leveraged to augment the state, leading to a policy that can adapt to abrupt variations in context. We demonstrate empirically that SeCBAD can infer context segment length accurately and outperform existing methods on a toy grid world environment and Mujuco tasks with piecewise-stable context.
PointAvatar: Deformable Point-based Head Avatars from Videos
Dec 16, 2022The ability to create realistic, animatable and relightable head avatars from casual video sequences would open up wide ranging applications in communication and entertainment. Current methods either build on explicit 3D morphable meshes (3DMM) or exploit neural implicit representations. The former are limited by fixed topology, while the latter are non-trivial to deform and inefficient to render. Furthermore, existing approaches entangle lighting in the color estimation, thus they are limited in re-rendering the avatar in new environments. In contrast, we propose PointAvatar, a deformable point-based representation that disentangles the source color into intrinsic albedo and normal-dependent shading. We demonstrate that PointAvatar bridges the gap between existing mesh- and implicit representations, combining high-quality geometry and appearance with topological flexibility, ease of deformation and rendering efficiency. We show that our method is able to generate animatable 3D avatars using monocular videos from multiple sources including hand-held smartphones, laptop webcams and internet videos, achieving state-of-the-art quality in challenging cases where previous methods fail, e.g., thin hair strands, while being significantly more efficient in training than competing methods.
I M Avatar: Implicit Morphable Head Avatars from Videos
Dec 15, 2021
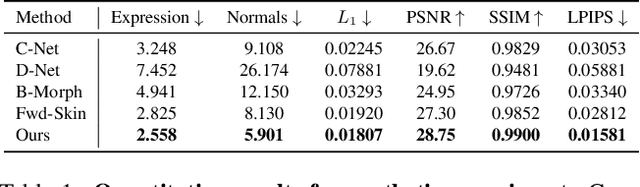
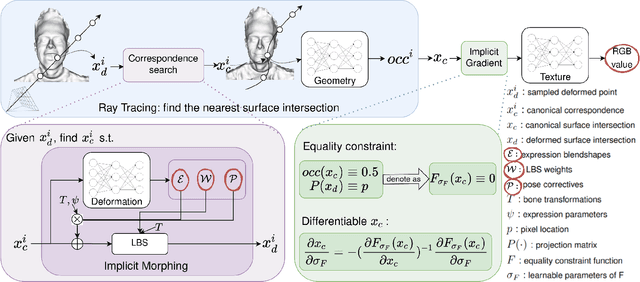
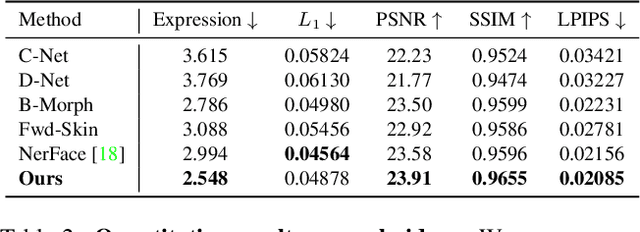
Traditional morphable face models provide fine-grained control over expression but cannot easily capture geometric and appearance details. Neural volumetric representations approach photo-realism but are hard to animate and do not generalize well to unseen expressions. To tackle this problem, we propose IMavatar (Implicit Morphable avatar), a novel method for learning implicit head avatars from monocular videos. Inspired by the fine-grained control mechanisms afforded by conventional 3DMMs, we represent the expression- and pose-related deformations via learned blendshapes and skinning fields. These attributes are pose-independent and can be used to morph the canonical geometry and texture fields given novel expression and pose parameters. We employ ray tracing and iterative root-finding to locate the canonical surface intersection for each pixel. A key contribution is our novel analytical gradient formulation that enables end-to-end training of IMavatars from videos. We show quantitatively and qualitatively that our method improves geometry and covers a more complete expression space compared to state-of-the-art methods.
SNARF: Differentiable Forward Skinning for Animating Non-Rigid Neural Implicit Shapes
Apr 08, 2021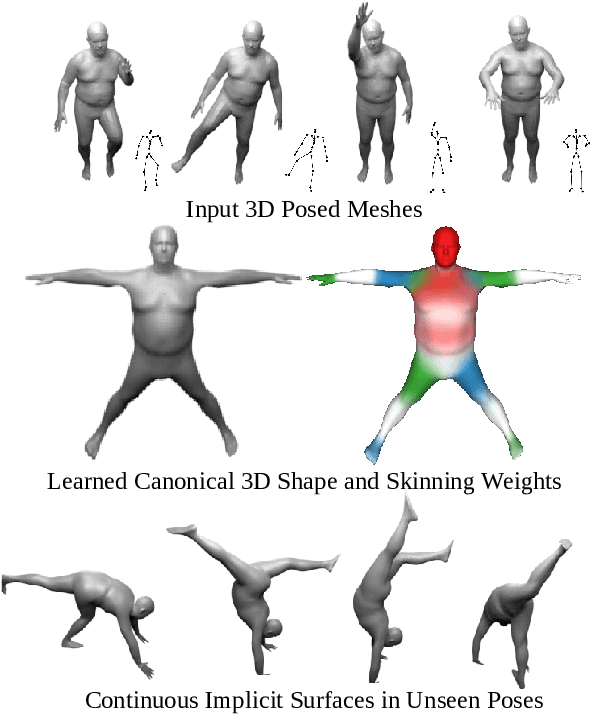


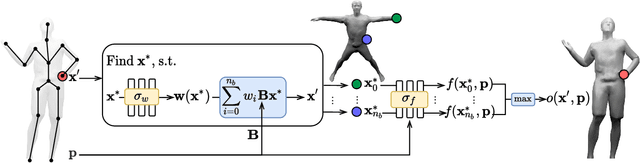
Neural implicit surface representations have emerged as a promising paradigm to capture 3D shapes in a continuous and resolution-independent manner. However, adapting them to articulated shapes is non-trivial. Existing approaches learn a backward warp field that maps deformed to canonical points. However, this is problematic since the backward warp field is pose dependent and thus requires large amounts of data to learn. To address this, we introduce SNARF, which combines the advantages of linear blend skinning (LBS) for polygonal meshes with those of neural implicit surfaces by learning a forward deformation field without direct supervision. This deformation field is defined in canonical, pose-independent space, allowing for generalization to unseen poses. Learning the deformation field from posed meshes alone is challenging since the correspondences of deformed points are defined implicitly and may not be unique under changes of topology. We propose a forward skinning model that finds all canonical correspondences of any deformed point using iterative root finding. We derive analytical gradients via implicit differentiation, enabling end-to-end training from 3D meshes with bone transformations. Compared to state-of-the-art neural implicit representations, our approach generalizes better to unseen poses while preserving accuracy. We demonstrate our method in challenging scenarios on (clothed) 3D humans in diverse and unseen poses.
Continuous Conditional Generative Adversarial Networks (cGAN) with Generator Regularization
Mar 27, 2021
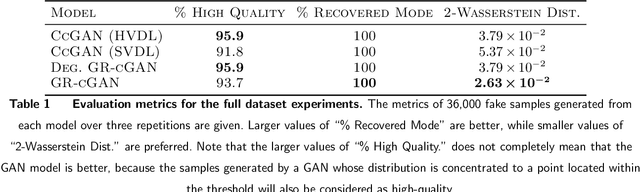
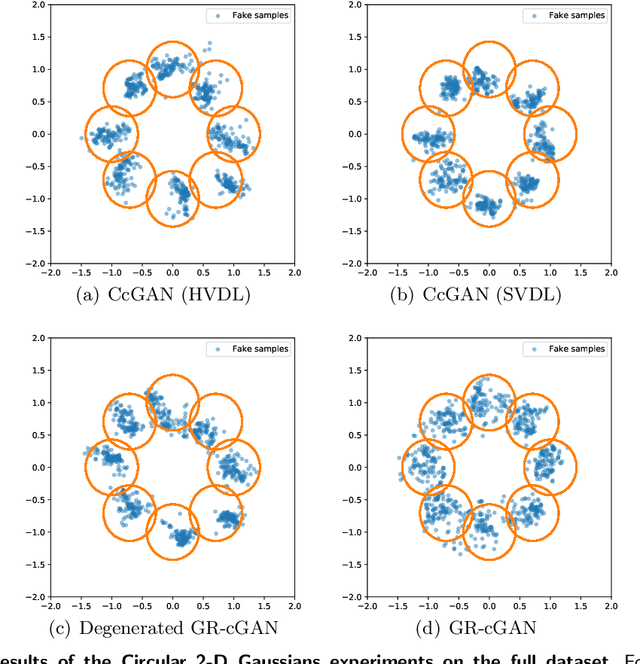
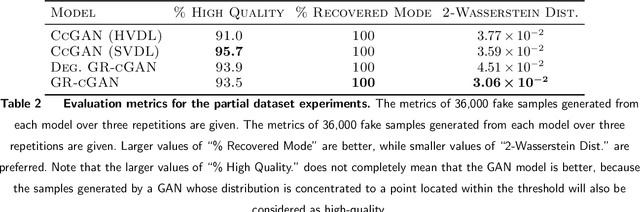
Conditional Generative Adversarial Networks are known to be difficult to train, especially when the conditions are continuous and high-dimensional. To partially alleviate this difficulty, we propose a simple generator regularization term on the GAN generator loss in the form of Lipschitz penalty. Thus, when the generator is fed with neighboring conditions in the continuous space, the regularization term will leverage the neighbor information and push the generator to generate samples that have similar conditional distributions for each neighboring condition. We analyze the effect of the proposed regularization term and demonstrate its robust performance on a range of synthetic and real-world tasks.
Doubly Stochastic Generative Arrivals Modeling
Jan 26, 2021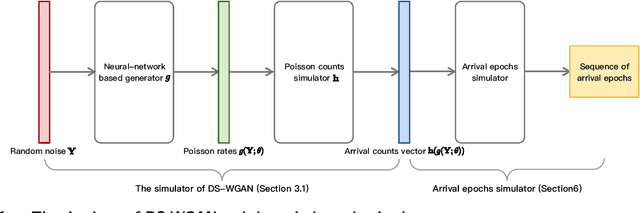
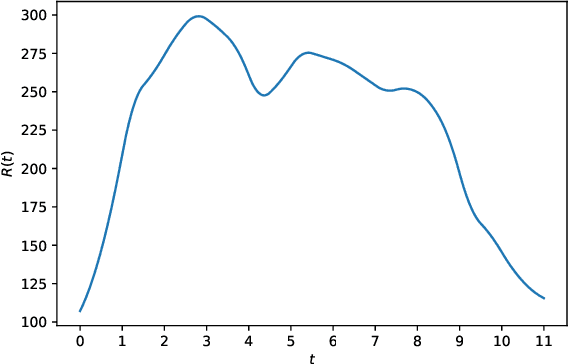
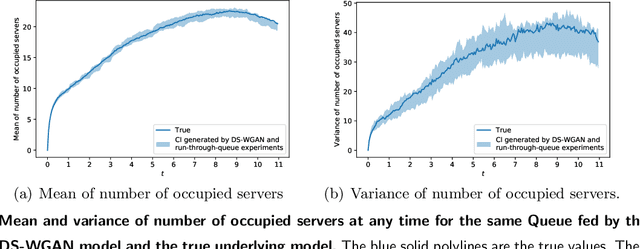
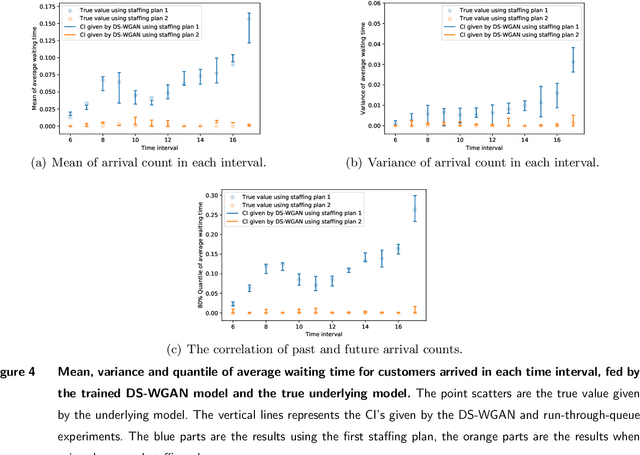
We propose a new framework named DS-WGAN that integrates the doubly stochastic (DS) structure and the Wasserstein generative adversarial networks (WGAN) to model, estimate, and simulate a wide class of arrival processes with general non-stationary and random arrival rates. Regarding statistical properties, we prove consistency and convergence rate for the estimator solved by the DS-WGAN framework under a non-parametric smoothness condition. Regarding computational efficiency and tractability, we address a challenge in gradient evaluation and model estimation, arised from the discontinuity in the simulator. We then show that the DS-WGAN framework can conveniently facilitate what-if simulation and predictive simulation for future scenarios that are different from the history. Numerical experiments with synthetic and real data sets are implemented to demonstrate the performance of DS-WGAN. The performance is measured from both a statistical perspective and an operational performance evaluation perspective. Numerical experiments suggest that, in terms of performance, the successful model estimation for DS-WGAN only requires a moderate size of representative data, which can be appealing in many contexts of operational management.