 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Conflict-Aware ACL Configurations with Natural Language Intents
Aug 25, 2025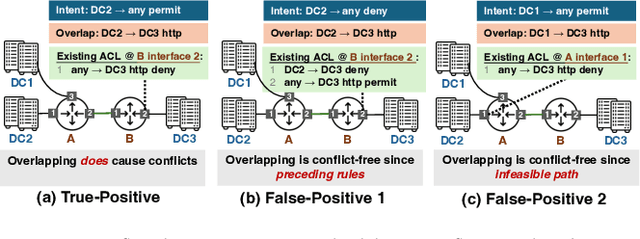

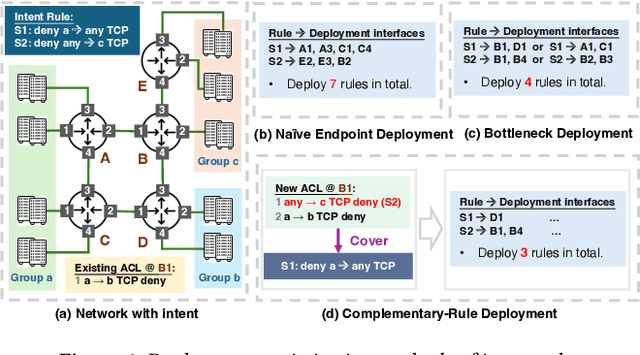
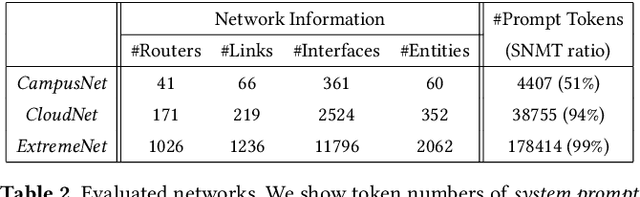
ACL configuration is essential for managing network flow reachability, yet its complexity grows significantly with topologies and pre-existing rules. To carry out ACL configuration, the operator needs to (1) understand the new configuration policies or intents and translate them into concrete ACL rules, (2) check and resolve any conflicts between the new and existing rules, and (3) deploy them across the network. Existing systems rely heavily on manual efforts for these tasks, especially for the first two, which are tedious, error-prone, and impractical to scale. We propose Xumi to tackle this problem. Leveraging LLMs with domain knowledge of the target network, Xumi automatically and accurately translates the natural language intents into complete ACL rules to reduce operators' manual efforts. Xumi then detects all potential conflicts between new and existing rules and generates resolved intents for deployment with operators' guidance, and finally identifies the best deployment plan that minimizes the rule additions while satisfying all intents. Evaluation shows that Xumi accelerates the entire configuration pipeline by over 10x compared to current practices, addresses O(100) conflicting ACLs and reduces rule additions by ~40% in modern cloud network.
An Adaptive Deep RL Method for Non-Stationary Environments with Piecewise Stable Context
Dec 24, 2022One of the key challenges in deploying RL to real-world applications is to adapt to variations of unknown environment contexts, such as changing terrains in robotic tasks and fluctuated bandwidth in congestion control. Existing works on adaptation to unknown environment contexts either assume the contexts are the same for the whole episode or assume the context variables are Markovian. However, in many real-world applications, the environment context usually stays stable for a stochastic period and then changes in an abrupt and unpredictable manner within an episode, resulting in a segment structure, which existing works fail to address. To leverage the segment structure of piecewise stable context in real-world applications, in this paper, we propose a \textit{\textbf{Se}gmented \textbf{C}ontext \textbf{B}elief \textbf{A}ugmented \textbf{D}eep~(SeCBAD)} RL method. Our method can jointly infer the belief distribution over latent context with the posterior over segment length and perform more accurate belief context inference with observed data within the current context segment. The inferred belief context can be leveraged to augment the state, leading to a policy that can adapt to abrupt variations in context. We demonstrate empirically that SeCBAD can infer context segment length accurately and outperform existing methods on a toy grid world environment and Mujuco tasks with piecewise-stable context.
Tutel: Adaptive Mixture-of-Experts at Scale
Jun 07, 2022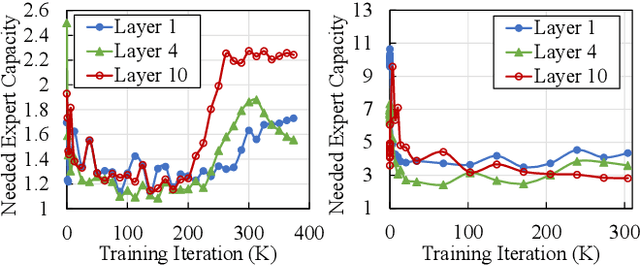
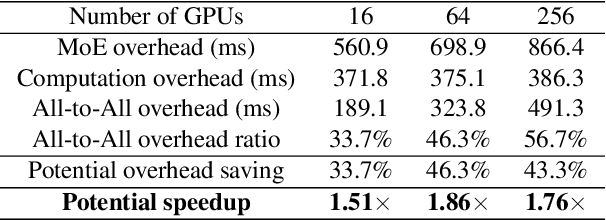
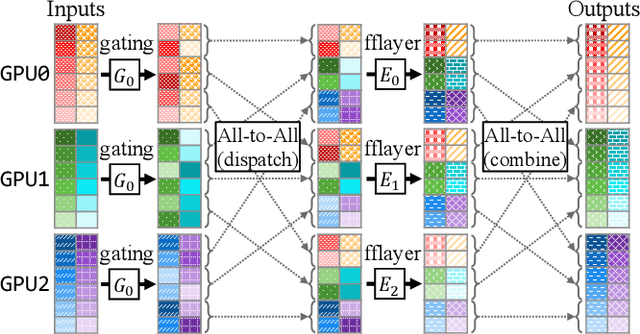

In recent years, Mixture-of-Experts (MoE) has emerged as a promising technique for deep learning that can scale the model capacity to trillion-plus parameters while reducing the computing cost via sparse computation. While MoE opens a new frontier of exceedingly large models, its implementation over thousands of GPUs has been limited due to mismatch between the dynamic nature of MoE and static parallelism/pipelining of the system. We present Tutel, a highly scalable stack design and implementation for MoE with dynamically adaptive parallelism and pipelining. Tutel delivers adaptive parallelism switching and adaptive pipelining at runtime, which achieves up to 1.74x and 2.00x single MoE layer speedup, respectively. We also propose a novel two-dimensional hierarchical algorithm for MoE communication speedup that outperforms the previous state-of-the-art up to 20.7x over 2,048 GPUs. Aggregating all techniques, Tutel finally delivers 4.96x and 5.75x speedup of a single MoE layer on 16 GPUs and 2,048 GPUs, respectively, over Fairseq: Meta's Facebook AI Research Sequence-to-Sequence Toolkit (Tutel is now partially adopted by Fairseq). Tutel source code is available in public: https://github.com/microsoft/tutel . Our evaluation shows that Tutel efficiently and effectively runs a real-world MoE-based model named SwinV2-MoE, built upon Swin Transformer V2, a state-of-the-art computer vision architecture. On efficiency, Tutel accelerates SwinV2-MoE, achieving up to 1.55x and 2.11x speedup in training and inference over Fairseq, respectively. On effectiveness, the SwinV2-MoE model achieves superior accuracy in both pre-training and down-stream computer vision tasks such as COCO object detection than the counterpart dense model, indicating the readiness of Tutel for end-to-end real-world model training and inference. SwinV2-MoE is open sourced in https://github.com/microsoft/Swin-Transformer .
CrossoverScheduler: Overlapping Multiple Distributed Training Applications in a Crossover Manner
Mar 14, 2021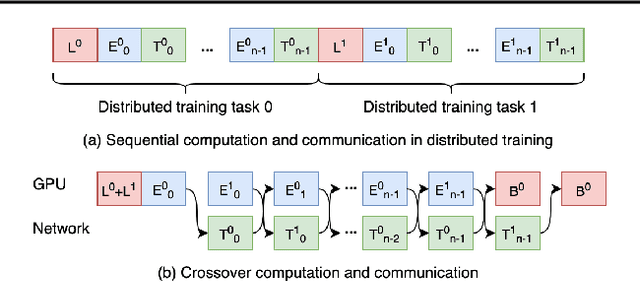
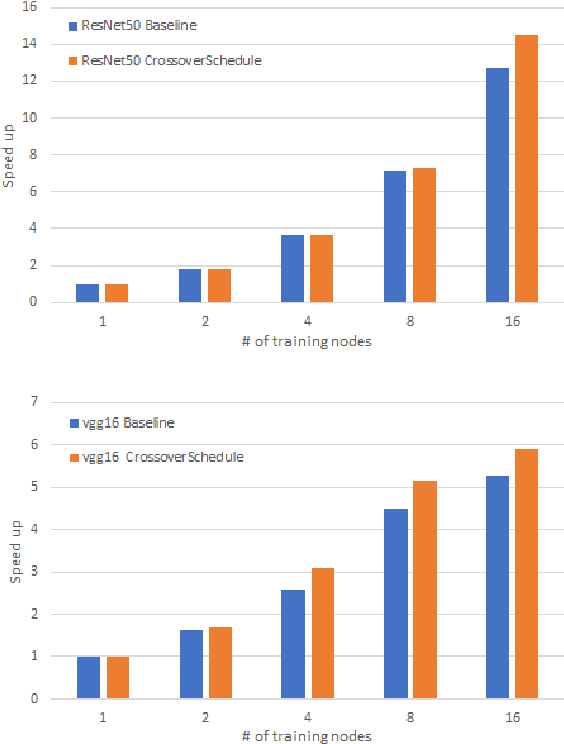
Distributed deep learning workloads include throughput-intensive training tasks on the GPU clusters, where the Distributed Stochastic Gradient Descent (SGD) incurs significant communication delays after backward propagation, forces workers to wait for the gradient synchronization via a centralized parameter server or directly in decentralized workers. We present CrossoverScheduler, an algorithm that enables communication cycles of a distributed training application to be filled by other applications through pipelining communication and computation. With CrossoverScheduler, the running performance of distributed training can be significantly improved without sacrificing convergence rate and network accuracy. We achieve so by introducing Crossover Synchronization which allows multiple distributed deep learning applications to time-share the same GPU alternately. The prototype of CrossoverScheduler is built and integrated with Horovod. Experiments on a variety of distributed tasks show that CrossoverScheduler achieves 20% \times speedup for image classification tasks on ImageNet dataset.
Simulating Performance of ML Systems with Offline Profiling
Feb 17, 2020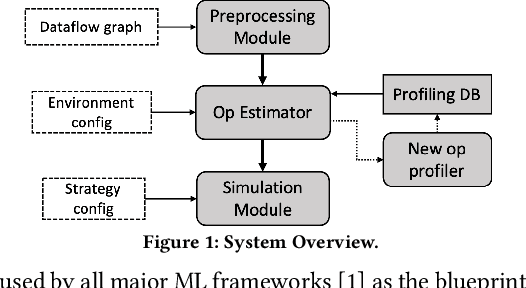
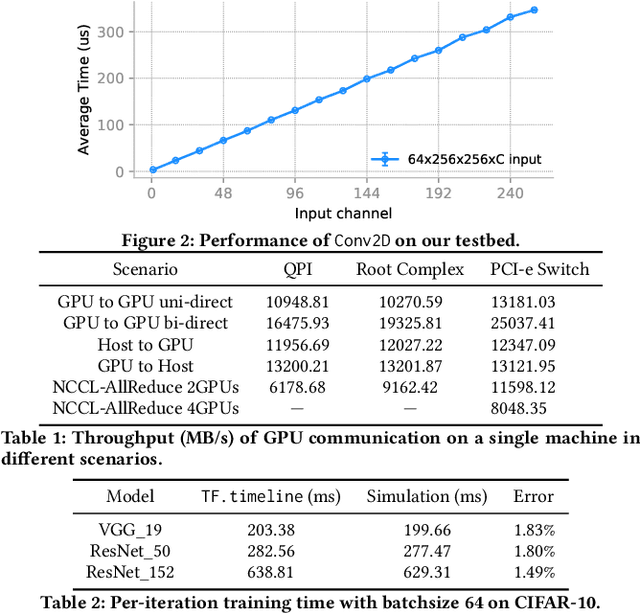
We advocate that simulation based on offline profiling is a promising approach to better understand and improve the complex ML systems. Our approach uses operation-level profiling and dataflow based simulation to ensure it offers a unified and automated solution for all frameworks and ML models, and is also accurate by considering the various parallelization strategies in a real system.
Stanza: Layer Separation for Distributed Training in Deep Learning
Jan 10, 2019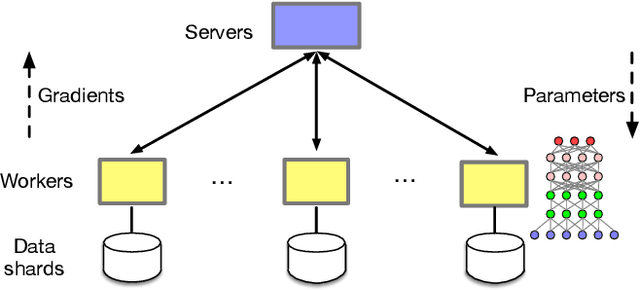
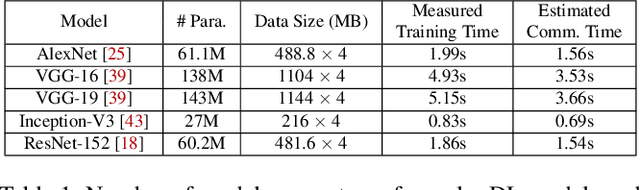
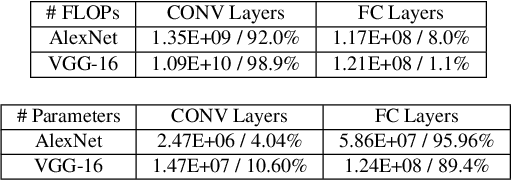
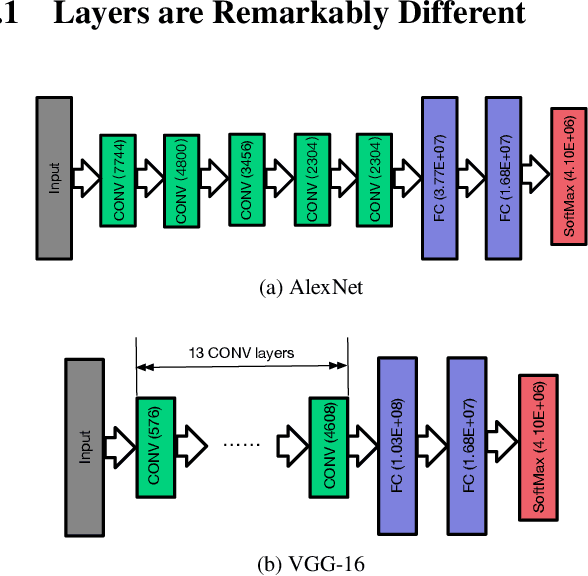
The parameter server architecture is prevalently used for distributed deep learning. Each worker machine in a parameter server system trains the complete model, which leads to a hefty amount of network data transfer between workers and servers. We empirically observe that the data transfer has a non-negligible impact on training time. To tackle the problem, we design a new distributed training system called Stanza. Stanza exploits the fact that in many models such as convolution neural networks, most data exchange is attributed to the fully connected layers, while most computation is carried out in convolutional layers. Thus, we propose layer separation in distributed training: the majority of the nodes just train the convolutional layers, and the rest train the fully connected layers only. Gradients and parameters of the fully connected layers no longer need to be exchanged across the cluster, thereby substantially reducing the data transfer volume. We implement Stanza on PyTorch and evaluate its performance on Azure and EC2. Results show that Stanza accelerates training significantly over current parameter server systems: on EC2 instances with Tesla V100 GPU and 10Gb bandwidth for example, Stanza is 1.34x--13.9x faster for common deep learning models.