 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossoverScheduler: Overlapping Multiple Distributed Training Applications in a Crossover Manner
Paper and Code
Mar 14, 2021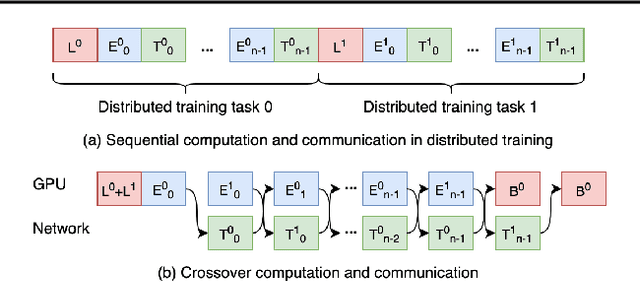
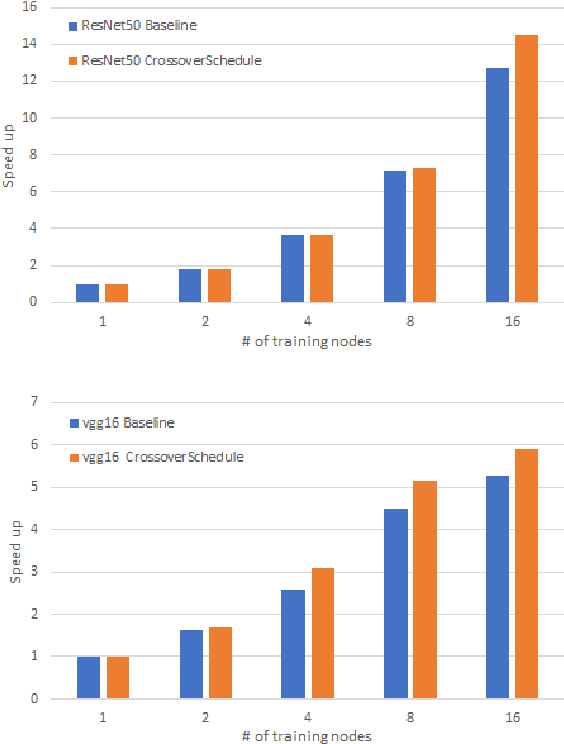
Distributed deep learning workloads include throughput-intensive training tasks on the GPU clusters, where the Distributed Stochastic Gradient Descent (SGD) incurs significant communication delays after backward propagation, forces workers to wait for the gradient synchronization via a centralized parameter server or directly in decentralized workers. We present CrossoverScheduler, an algorithm that enables communication cycles of a distributed training application to be filled by other applications through pipelining communication and computation. With CrossoverScheduler, the running performance of distributed training can be significantly improved without sacrificing convergence rate and network accuracy. We achieve so by introducing Crossover Synchronization which allows multiple distributed deep learning applications to time-share the same GPU alternately. The prototype of CrossoverScheduler is built and integrated with Horovod. Experiments on a variety of distributed tasks show that CrossoverScheduler achieves 20% \times speedup for image classification tasks on ImageNet dataset.