 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLASER: Learning Active Sensing for Continuum Field Reconstruction
Apr 21, 2026High-fidelity measurements of continuum physical fields are essential for scientific discovery and engineering design but remain challenging under sparse and constrained sensing. Conventional reconstruction methods typically rely on fixed sensor layouts, which cannot adapt to evolving physical states. We propose LASER, a unified, closed-loop framework that formulates active sensing as a Partially Observable Markov Decision Process (POMDP). At its core, LASER employs a continuum field latent world model that captures the underlying physical dynamics and provides intrinsic reward feedback. This enables a reinforcement learning policy to simulate ''what-if'' sensing scenarios within a latent imagination space. By conditioning sensor movements on predicted latent states, LASER navigates toward potentially high-information regions beyond current observations. Our experiments demonstrate that LASER consistently outperforms static and offline-optimized strategies, achieving high-fidelity reconstruction under sparsity across diverse continuum fields.
Discovering Message Passing Hierarchies for Mesh-Based Physics Simulation
Oct 03, 2024

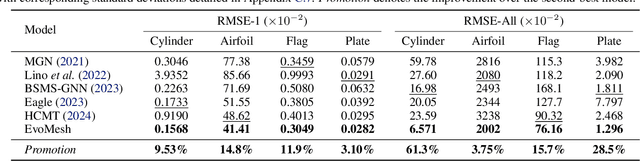

Graph neural networks have emerged as a powerful tool for large-scale mesh-based physics simulation. Existing approaches primarily employ hierarchical, multi-scale message passing to capture long-range dependencies within the graph. However, these graph hierarchies are typically fixed and manually designed, which do not adapt to the evolving dynamics present in complex physical systems. In this paper, we introduce a novel neural network named DHMP, which learns Dynamic Hierarchies for Message Passing networks through a differentiable node selection method. The key component is the anisotropic message passing mechanism, which operates at both intra-level and inter-level interactions. Unlike existing methods, it first supports directionally non-uniform aggregation of dynamic features between adjacent nodes within each graph hierarchy. Second, it determines node selection probabilities for the next hierarchy according to different physical contexts, thereby creating more flexible message shortcuts for learning remote node relations. Our experiments demonstrate the effectiveness of DHMP, achieving 22.7% improvement on average compared to recent fixed-hierarchy message passing networks across five classic physics simulation datasets.
Latent Intuitive Physics: Learning to Transfer Hidden Physics from A 3D Video
Jun 18, 2024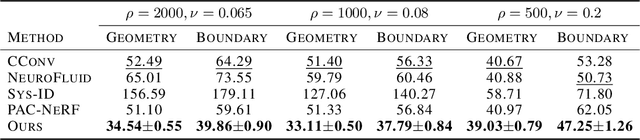
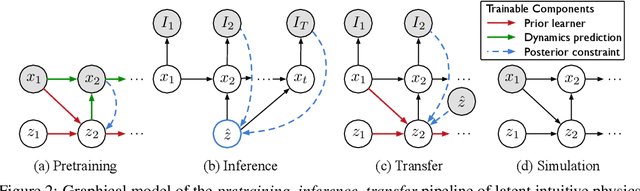

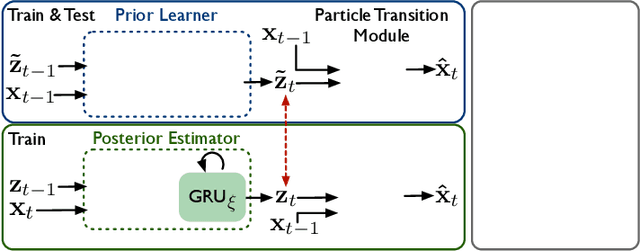
We introduce latent intuitive physics, a transfer learning framework for physics simulation that can infer hidden properties of fluids from a single 3D video and simulate the observed fluid in novel scenes. Our key insight is to use latent features drawn from a learnable prior distribution conditioned on the underlying particle states to capture the invisible and complex physical properties. To achieve this, we train a parametrized prior learner given visual observations to approximate the visual posterior of inverse graphics, and both the particle states and the visual posterior are obtained from a learned neural renderer. The converged prior learner is embedded in our probabilistic physics engine, allowing us to perform novel simulations on unseen geometries, boundaries, and dynamics without knowledge of the true physical parameters. We validate our model in three ways: (i) novel scene simulation with the learned visual-world physics, (ii) future prediction of the observed fluid dynamics, and (iii) supervised particle simulation. Our model demonstrates strong performance in all three tasks.
* Published as a conference paper at ICLR 2024
Model-Based Reinforcement Learning with Isolated Imaginations
Mar 27, 2023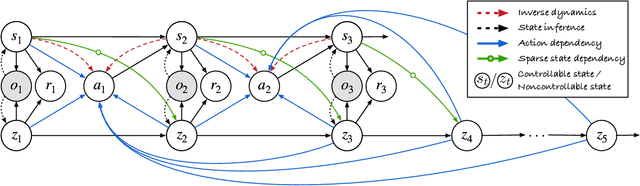

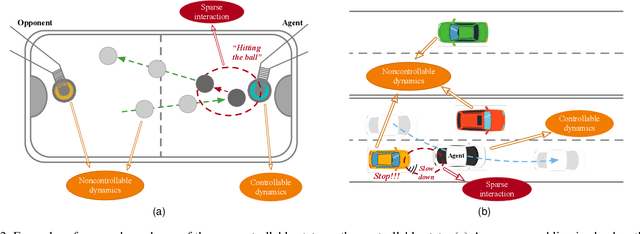
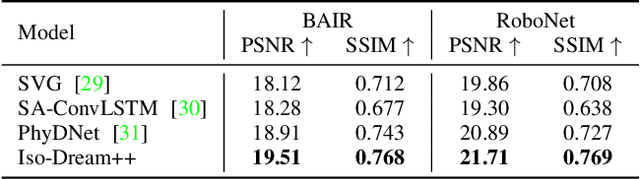
World models learn the consequences of actions in vision-based interactive systems. However, in practical scenarios like autonomous driving, noncontrollable dynamics that are independent or sparsely dependent on action signals often exist, making it challenging to learn effective world models. To address this issue, we propose Iso-Dream++, a model-based reinforcement learning approach that has two main contributions. First, we optimize the inverse dynamics to encourage the world model to isolate controllable state transitions from the mixed spatiotemporal variations of the environment. Second, we perform policy optimization based on the decoupled latent imaginations, where we roll out noncontrollable states into the future and adaptively associate them with the current controllable state. This enables long-horizon visuomotor control tasks to benefit from isolating mixed dynamics sources in the wild, such as self-driving cars that can anticipate the movement of other vehicles, thereby avoiding potential risks. On top of our previous work, we further consider the sparse dependencies between controllable and noncontrollable states, address the training collapse problem of state decoupling, and validate our approach in transfer learning setups. Our empirical study demonstrates that Iso-Dream++ outperforms existing reinforcement learning models significantly on CARLA and DeepMind Control.
Predictive Experience Replay for Continual Visual Control and Forecasting
Mar 12, 2023



Learning physical dynamics in a series of non-stationary environments is a challenging but essential task for model-based reinforcement learning (MBRL) with visual inputs. It requires the agent to consistently adapt to novel tasks without forgetting previous knowledge. In this paper, we present a new continual learning approach for visual dynamics modeling and explore its efficacy in visual control and forecasting. The key assumption is that an ideal world model can provide a non-forgetting environment simulator, which enables the agent to optimize the policy in a multi-task learning manner based on the imagined trajectories from the world model. To this end, we first propose the mixture world model that learns task-specific dynamics priors with a mixture of Gaussians, and then introduce a new training strategy to overcome catastrophic forgetting, which we call predictive experience replay. Finally, we extend these methods to continual RL and further address the value estimation problems with the exploratory-conservative behavior learning approach. Our model remarkably outperforms the naive combinations of existing continual learning and visual RL algorithms on DeepMind Control and Meta-World benchmarks with continual visual control tasks. It is also shown to effectively alleviate the forgetting of spatiotemporal dynamics in video prediction datasets with evolving domains.
An Adaptive Deep RL Method for Non-Stationary Environments with Piecewise Stable Context
Dec 24, 2022One of the key challenges in deploying RL to real-world applications is to adapt to variations of unknown environment contexts, such as changing terrains in robotic tasks and fluctuated bandwidth in congestion control. Existing works on adaptation to unknown environment contexts either assume the contexts are the same for the whole episode or assume the context variables are Markovian. However, in many real-world applications, the environment context usually stays stable for a stochastic period and then changes in an abrupt and unpredictable manner within an episode, resulting in a segment structure, which existing works fail to address. To leverage the segment structure of piecewise stable context in real-world applications, in this paper, we propose a \textit{\textbf{Se}gmented \textbf{C}ontext \textbf{B}elief \textbf{A}ugmented \textbf{D}eep~(SeCBAD)} RL method. Our method can jointly infer the belief distribution over latent context with the posterior over segment length and perform more accurate belief context inference with observed data within the current context segment. The inferred belief context can be leveraged to augment the state, leading to a policy that can adapt to abrupt variations in context. We demonstrate empirically that SeCBAD can infer context segment length accurately and outperform existing methods on a toy grid world environment and Mujuco tasks with piecewise-stable context.
Proving Common Mechanisms Shared by Twelve Methods of Boosting Adversarial Transferability
Jul 24, 2022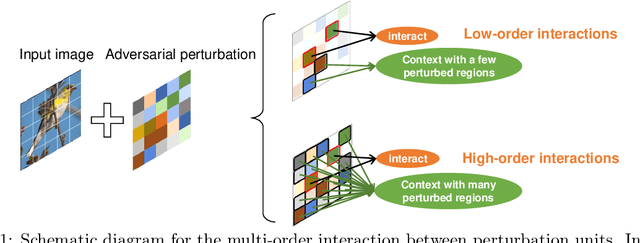
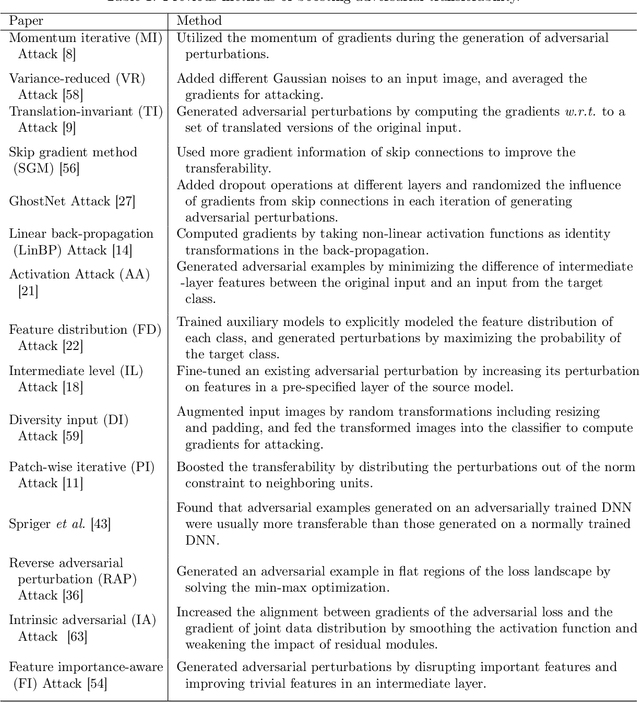
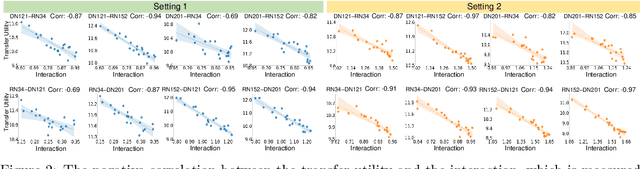
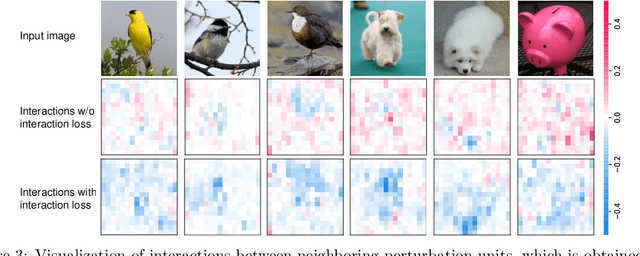
Although many methods have been proposed to enhance the transferability of adversarial perturbations, these methods are designed in a heuristic manner, and the essential mechanism for improving adversarial transferability is still unclear. This paper summarizes the common mechanism shared by twelve previous transferability-boosting methods in a unified view, i.e., these methods all reduce game-theoretic interactions between regional adversarial perturbations. To this end, we focus on the attacking utility of all interactions between regional adversarial perturbations, and we first discover and prove the negative correlation between the adversarial transferability and the attacking utility of interactions. Based on this discovery, we theoretically prove and empirically verify that twelve previous transferability-boosting methods all reduce interactions between regional adversarial perturbations. More crucially, we consider the reduction of interactions as the essential reason for the enhancement of adversarial transferability. Furthermore, we design the interaction loss to directly penalize interactions between regional adversarial perturbations during attacking. Experimental results show that the interaction loss significantly improves the transferability of adversarial perturbations.
Isolating and Leveraging Controllable and Noncontrollable Visual Dynamics in World Models
May 27, 2022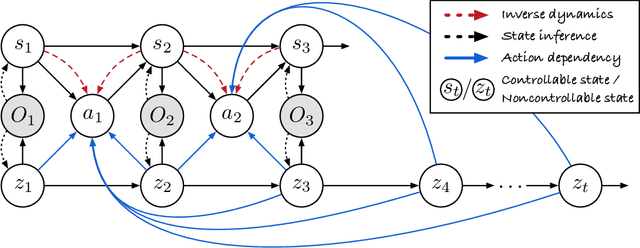
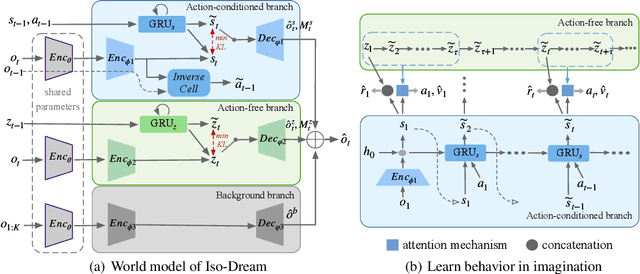
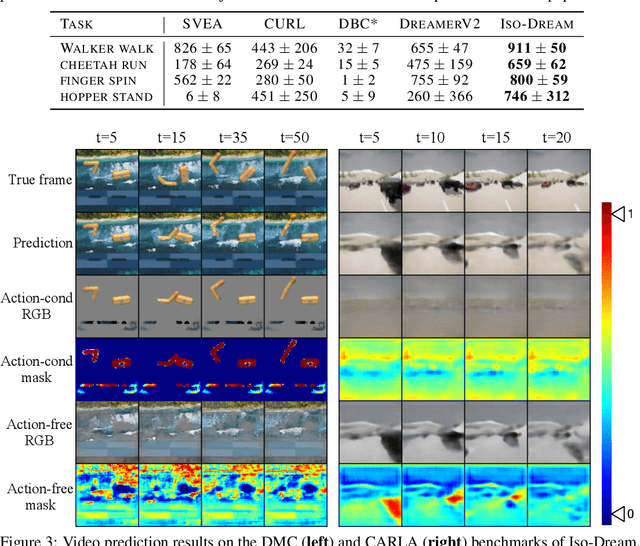

World models learn the consequences of actions in vision-based interactive systems. However, in practical scenarios such as autonomous driving, there commonly exists noncontrollable dynamics independent of the action signals, making it difficult to learn effective world models. To tackle this problem, we present a novel reinforcement learning approach named Iso-Dream, which improves the Dream-to-Control framework in two aspects. First, by optimizing the inverse dynamics, we encourage the world model to learn controllable and noncontrollable sources of spatiotemporal changes on isolated state transition branches. Second, we optimize the behavior of the agent on the decoupled latent imaginations of the world model. Specifically, to estimate state values, we roll-out the noncontrollable states into the future and associate them with the current controllable state. In this way, the isolation of dynamics sources can greatly benefit long-horizon decision-making of the agent, such as a self-driving car that can avoid potential risks by anticipating the movement of other vehicles. Experiments show that Iso-Dream is effective in decoupling the mixed dynamics and remarkably outperforms existing approaches in a wide range of visual control and prediction domains.
A Unified Approach to Interpreting and Boosting Adversarial Transferability
Oct 08, 2020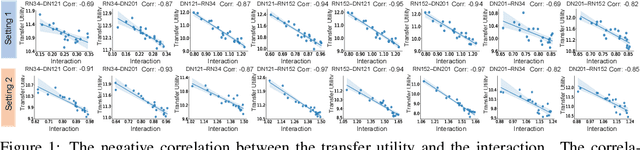



In this paper, we use the interaction inside adversarial perturbations to explain and boost the adversarial transferability. We discover and prove the negative correlation between the adversarial transferability and the interaction inside adversarial perturbations. The negative correlation is further verified through different DNNs with various inputs. Moreover, this negative correlation can be regarded as a unified perspective to understand current transferability-boosting methods. To this end, we prove that some classic methods of enhancing the transferability essentially decease interactions inside adversarial perturbations. Based on this, we propose to directly penalize interactions during the attacking process, which significantly improves the adversarial transferability.