 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Offline Policy is Not Trustworthy: Bilevel Reinforcement Learning for Sequential Portfolio Optimization
May 19, 2025Reinforcement learning (RL) has shown significant promise for sequential portfolio optimization tasks, such as stock trading, where the objective is to maximize cumulative returns while minimizing risks using historical data. However, traditional RL approaches often produce policies that merely memorize the optimal yet impractical buying and selling behaviors within the fixed dataset. These offline policies are less generalizable as they fail to account for the non-stationary nature of the market. Our approach, MetaTrader, frames portfolio optimization as a new type of partial-offline RL problem and makes two technical contributions. First, MetaTrader employs a bilevel learning framework that explicitly trains the RL agent to improve both in-domain profits on the original dataset and out-of-domain performance across diverse transformations of the raw financial data. Second, our approach incorporates a new temporal difference (TD) method that approximates worst-case TD estimates from a batch of transformed TD targets, addressing the value overestimation issue that is particularly challenging in scenarios with limited offline data. Our empirical results on two public stock datasets show that MetaTrader outperforms existing methods, including both RL-based approaches and traditional stock prediction models.
Dynamic Scene Understanding through Object-Centric Voxelization and Neural Rendering
Jul 30, 2024
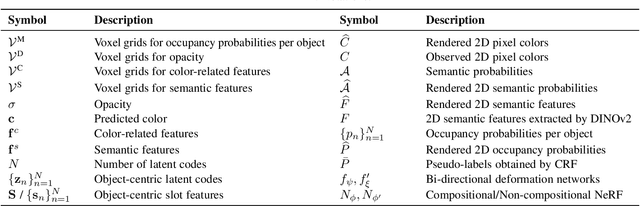


Learning object-centric representations from unsupervised videos is challenging. Unlike most previous approaches that focus on decomposing 2D images, we present a 3D generative model named DynaVol-S for dynamic scenes that enables object-centric learning within a differentiable volume rendering framework. The key idea is to perform object-centric voxelization to capture the 3D nature of the scene, which infers per-object occupancy probabilities at individual spatial locations. These voxel features evolve through a canonical-space deformation function and are optimized in an inverse rendering pipeline with a compositional NeRF. Additionally, our approach integrates 2D semantic features to create 3D semantic grids, representing the scene through multiple disentangled voxel grids. DynaVol-S significantly outperforms existing models in both novel view synthesis and unsupervised decomposition tasks for dynamic scenes. By jointly considering geometric structures and semantic features, it effectively addresses challenging real-world scenarios involving complex object interactions. Furthermore, once trained, the explicitly meaningful voxel features enable additional capabilities that 2D scene decomposition methods cannot achieve, such as novel scene generation through editing geometric shapes or manipulating the motion trajectories of objects.
Object-Centric Voxelization of Dynamic Scenes via Inverse Neural Rendering
Apr 30, 2023Understanding the compositional dynamics of the world in unsupervised 3D scenarios is challenging. Existing approaches either fail to make effective use of time cues or ignore the multi-view consistency of scene decomposition. In this paper, we propose DynaVol, an inverse neural rendering framework that provides a pilot study for learning time-varying volumetric representations for dynamic scenes with multiple entities (like objects). It has two main contributions. First, it maintains a time-dependent 3D grid, which dynamically and flexibly binds the spatial locations to different entities, thus encouraging the separation of information at a representational level. Second, our approach jointly learns grid-level local dynamics, object-level global dynamics, and the compositional neural radiance fields in an end-to-end architecture, thereby enhancing the spatiotemporal consistency of object-centric scene voxelization. We present a two-stage training scheme for DynaVol and validate its effectiveness on various benchmarks with multiple objects, diverse dynamics, and real-world shapes and textures. We present visualization at https://sites.google.com/view/dynavol-visual.
Predictive Experience Replay for Continual Visual Control and Forecasting
Mar 12, 2023



Learning physical dynamics in a series of non-stationary environments is a challenging but essential task for model-based reinforcement learning (MBRL) with visual inputs. It requires the agent to consistently adapt to novel tasks without forgetting previous knowledge. In this paper, we present a new continual learning approach for visual dynamics modeling and explore its efficacy in visual control and forecasting. The key assumption is that an ideal world model can provide a non-forgetting environment simulator, which enables the agent to optimize the policy in a multi-task learning manner based on the imagined trajectories from the world model. To this end, we first propose the mixture world model that learns task-specific dynamics priors with a mixture of Gaussians, and then introduce a new training strategy to overcome catastrophic forgetting, which we call predictive experience replay. Finally, we extend these methods to continual RL and further address the value estimation problems with the exploratory-conservative behavior learning approach. Our model remarkably outperforms the naive combinations of existing continual learning and visual RL algorithms on DeepMind Control and Meta-World benchmarks with continual visual control tasks. It is also shown to effectively alleviate the forgetting of spatiotemporal dynamics in video prediction datasets with evolving domains.
Continual Predictive Learning from Videos
Apr 12, 2022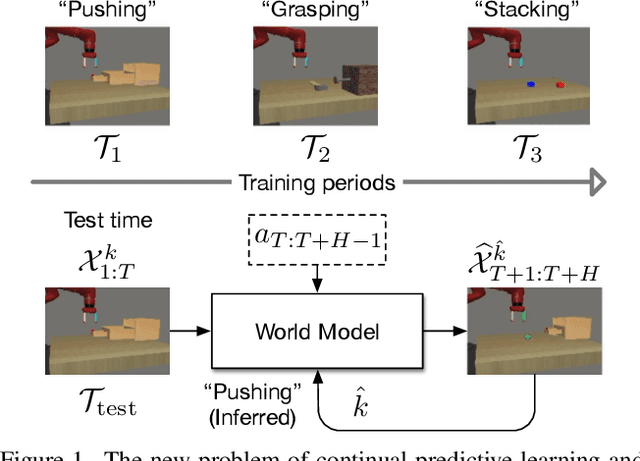
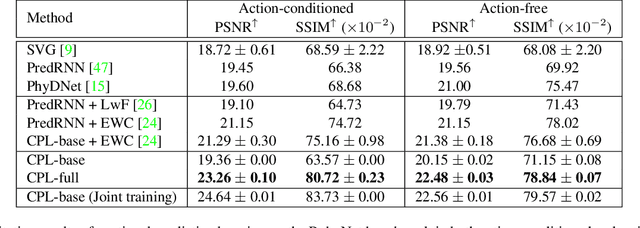
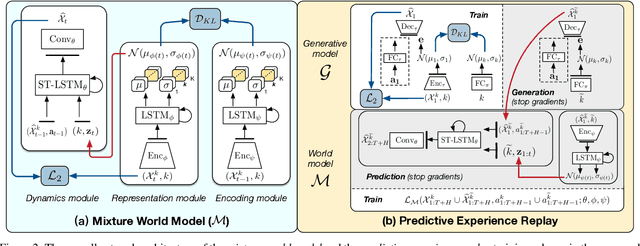
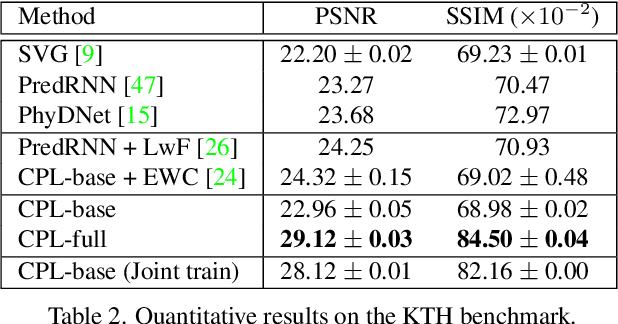
Predictive learning ideally builds the world model of physical processes in one or more given environments. Typical setups assume that we can collect data from all environments at all times. In practice, however, different prediction tasks may arrive sequentially so that the environments may change persistently throughout the training procedure. Can we develop predictive learning algorithms that can deal with more realistic, non-stationary physical environments? In this paper, we study a new continual learning problem in the context of video prediction, and observe that most existing methods suffer from severe catastrophic forgetting in this setup. To tackle this problem, we propose the continual predictive learning (CPL) approach, which learns a mixture world model via predictive experience replay and performs test-time adaptation with non-parametric task inference. We construct two new benchmarks based on RoboNet and KTH, in which different tasks correspond to different physical robotic environments or human actions. Our approach is shown to effectively mitigate forgetting and remarkably outperform the na\"ive combinations of previous art in video prediction and continual learning.
Transfer Learning Based Multi-Objective Genetic Algorithm for Dynamic Community Detection
Oct 09, 2021



Dynamic community detection is the hotspot and basic problem of complex network and artificial intelligence research in recent years. It is necessary to maximize the accuracy of clustering as the network structure changes, but also to minimize the two consecutive clustering differences between the two results. There is a trade-off relationship between these two objectives. In this paper, we propose a Feature Transfer Based Multi-Objective Optimization Genetic Algorithm (TMOGA) based on transfer learning and traditional multi-objective evolutionary algorithm framework. The main idea is to extract stable features from past community structures, retain valuable feature information, and integrate this feature information into current optimization processes to improve the evolutionary algorithms. Additionally, a new theoretical framework is proposed in this paper to analyze community detection problem based on information theory. Then, we exploit this framework to prove the rationality of TMOGA. Finally, the experimental results show that our algorithm can achieve better clustering effects compared with the state-of-the-art dynamic network community detection algorithms in diverse test problems.