 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Training of Mixture-of-Experts Models with Megatron Core
Mar 10, 2026Scaling Mixture-of-Experts (MoE) training introduces systems challenges absent in dense models. Because each token activates only a subset of experts, this sparsity allows total parameters to grow much faster than per-token computation, creating coupled constraints across memory, communication, and computation. Optimizing one dimension often shifts pressure to another, demanding co-design across the full system stack. We address these challenges for MoE training through integrated optimizations spanning memory (fine-grained recomputation, offloading, etc.), communication (optimized dispatchers, overlapping, etc.), and computation (Grouped GEMM, fusions, CUDA Graphs, etc.). The framework also provides Parallel Folding for flexible multi-dimensional parallelism, low-precision training support for FP8 and NVFP4, and efficient long-context training. On NVIDIA GB300 and GB200, it achieves 1,233/1,048 TFLOPS/GPU for DeepSeek-V3-685B and 974/919 TFLOPS/GPU for Qwen3-235B. As a performant, scalable, and production-ready open-source solution, it has been used across academia and industry for training MoE models ranging from billions to trillions of parameters on clusters scaling up to thousands of GPUs. This report explains how these techniques work, their trade-offs, and their interactions at the systems level, providing practical guidance for scaling MoE models with Megatron Core.
Plug-and-Play Parameter-Efficient Tuning of Embeddings for Federated Recommendation
Dec 14, 2025With the rise of cloud-edge collaboration, recommendation services are increasingly trained in distributed environments. Federated Recommendation (FR) enables such multi-end collaborative training while preserving privacy by sharing model parameters instead of raw data. However, the large number of parameters, primarily due to the massive item embeddings, significantly hampers communication efficiency. While existing studies mainly focus on improving the efficiency of FR models, they largely overlook the issue of embedding parameter overhead. To address this gap, we propose a FR training framework with Parameter-Efficient Fine-Tuning (PEFT) based embedding designed to reduce the volume of embedding parameters that need to be transmitted. Our approach offers a lightweight, plugin-style solution that can be seamlessly integrated into existing FR methods. In addition to incorporating common PEFT techniques such as LoRA and Hash-based encoding, we explore the use of Residual Quantized Variational Autoencoders (RQ-VAE) as a novel PEFT strategy within our framework. Extensive experiments across various FR model backbones and datasets demonstrate that our framework significantly reduces communication overhead while improving accuracy. The source code is available at https://github.com/young1010/FedPEFT.
Your Offline Policy is Not Trustworthy: Bilevel Reinforcement Learning for Sequential Portfolio Optimization
May 19, 2025Reinforcement learning (RL) has shown significant promise for sequential portfolio optimization tasks, such as stock trading, where the objective is to maximize cumulative returns while minimizing risks using historical data. However, traditional RL approaches often produce policies that merely memorize the optimal yet impractical buying and selling behaviors within the fixed dataset. These offline policies are less generalizable as they fail to account for the non-stationary nature of the market. Our approach, MetaTrader, frames portfolio optimization as a new type of partial-offline RL problem and makes two technical contributions. First, MetaTrader employs a bilevel learning framework that explicitly trains the RL agent to improve both in-domain profits on the original dataset and out-of-domain performance across diverse transformations of the raw financial data. Second, our approach incorporates a new temporal difference (TD) method that approximates worst-case TD estimates from a batch of transformed TD targets, addressing the value overestimation issue that is particularly challenging in scenarios with limited offline data. Our empirical results on two public stock datasets show that MetaTrader outperforms existing methods, including both RL-based approaches and traditional stock prediction models.
Multimodal Transformers are Hierarchical Modal-wise Heterogeneous Graphs
May 02, 2025Multimodal Sentiment Analysis (MSA) is a rapidly developing field that integrates multimodal information to recognize sentiments, and existing models have made significant progress in this area. The central challenge in MSA is multimodal fusion, which is predominantly addressed by Multimodal Transformers (MulTs). Although act as the paradigm, MulTs suffer from efficiency concerns. In this work, from the perspective of efficiency optimization, we propose and prove that MulTs are hierarchical modal-wise heterogeneous graphs (HMHGs), and we introduce the graph-structured representation pattern of MulTs. Based on this pattern, we propose an Interlaced Mask (IM) mechanism to design the Graph-Structured and Interlaced-Masked Multimodal Transformer (GsiT). It is formally equivalent to MulTs which achieves an efficient weight-sharing mechanism without information disorder through IM, enabling All-Modal-In-One fusion with only 1/3 of the parameters of pure MulTs. A Triton kernel called Decomposition is implemented to ensure avoiding additional computational overhead. Moreover, it achieves significantly higher performance than traditional MulTs. To further validate the effectiveness of GsiT itself and the HMHG concept, we integrate them into multiple state-of-the-art models and demonstrate notable performance improvements and parameter reduction on widely used MSA datasets.
Learning Augmentation Policies from A Model Zoo for Time Series Forecasting
Sep 10, 2024



Time series forecasting models typically rely on a fixed-size training set and treat all data uniformly, which may not effectively capture the specific patterns present in more challenging training samples. To address this issue, we introduce AutoTSAug, a learnable data augmentation method based on reinforcement learning. Our approach begins with an empirical analysis to determine which parts of the training data should be augmented. Specifically, we identify the so-called marginal samples by considering the prediction diversity across a set of pretrained forecasting models. Next, we propose using variational masked autoencoders as the augmentation model and applying the REINFORCE algorithm to transform the marginal samples into new data. The goal of this generative model is not only to mimic the distribution of real data but also to reduce the variance of prediction errors across the model zoo. By augmenting the marginal samples with a learnable policy, AutoTSAug substantially improves forecasting performance, advancing the prior art in this field with minimal additional computational cost.
Latent Intuitive Physics: Learning to Transfer Hidden Physics from A 3D Video
Jun 18, 2024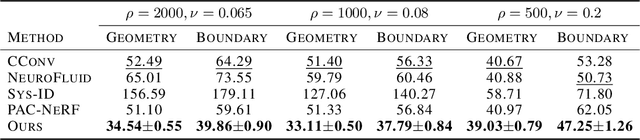
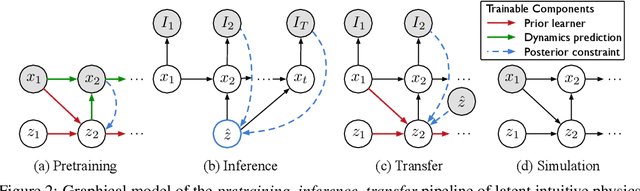

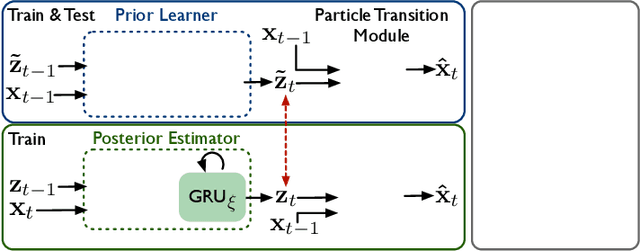
We introduce latent intuitive physics, a transfer learning framework for physics simulation that can infer hidden properties of fluids from a single 3D video and simulate the observed fluid in novel scenes. Our key insight is to use latent features drawn from a learnable prior distribution conditioned on the underlying particle states to capture the invisible and complex physical properties. To achieve this, we train a parametrized prior learner given visual observations to approximate the visual posterior of inverse graphics, and both the particle states and the visual posterior are obtained from a learned neural renderer. The converged prior learner is embedded in our probabilistic physics engine, allowing us to perform novel simulations on unseen geometries, boundaries, and dynamics without knowledge of the true physical parameters. We validate our model in three ways: (i) novel scene simulation with the learned visual-world physics, (ii) future prediction of the observed fluid dynamics, and (iii) supervised particle simulation. Our model demonstrates strong performance in all three tasks.
* Published as a conference paper at ICLR 2024