 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Offline Policy is Not Trustworthy: Bilevel Reinforcement Learning for Sequential Portfolio Optimization
May 19, 2025Reinforcement learning (RL) has shown significant promise for sequential portfolio optimization tasks, such as stock trading, where the objective is to maximize cumulative returns while minimizing risks using historical data. However, traditional RL approaches often produce policies that merely memorize the optimal yet impractical buying and selling behaviors within the fixed dataset. These offline policies are less generalizable as they fail to account for the non-stationary nature of the market. Our approach, MetaTrader, frames portfolio optimization as a new type of partial-offline RL problem and makes two technical contributions. First, MetaTrader employs a bilevel learning framework that explicitly trains the RL agent to improve both in-domain profits on the original dataset and out-of-domain performance across diverse transformations of the raw financial data. Second, our approach incorporates a new temporal difference (TD) method that approximates worst-case TD estimates from a batch of transformed TD targets, addressing the value overestimation issue that is particularly challenging in scenarios with limited offline data. Our empirical results on two public stock datasets show that MetaTrader outperforms existing methods, including both RL-based approaches and traditional stock prediction models.
Video-Enhanced Offline Reinforcement Learning: A Model-Based Approach
May 10, 2025Offline reinforcement learning (RL) enables policy optimization in static datasets, avoiding the risks and costs of real-world exploration. However, it struggles with suboptimal behavior learning and inaccurate value estimation due to the lack of environmental interaction. In this paper, we present Video-Enhanced Offline RL (VeoRL), a model-based approach that constructs an interactive world model from diverse, unlabeled video data readily available online. Leveraging model-based behavior guidance, VeoRL transfers commonsense knowledge of control policy and physical dynamics from natural videos to the RL agent within the target domain. Our method achieves substantial performance gains (exceeding 100% in some cases) across visuomotor control tasks in robotic manipulation, autonomous driving, and open-world video games.
Vid2Act: Activate Offline Videos for Visual RL
Jun 07, 2023Pretraining RL models on offline video datasets is a promising way to improve their training efficiency in online tasks, but challenging due to the inherent mismatch in tasks, dynamics, and behaviors across domains. A recent model, APV, sidesteps the accompanied action records in offline datasets and instead focuses on pretraining a task-irrelevant, action-free world model within the source domains. We present Vid2Act, a model-based RL method that learns to transfer valuable action-conditioned dynamics and potentially useful action demonstrations from offline to online settings. The main idea is to use the world models not only as simulators for behavior learning but also as tools to measure the domain relevance for both dynamics representation transfer and policy transfer. Specifically, we train the world models to generate a set of time-varying task similarities using a domain-selective knowledge distillation loss. These similarities serve two purposes: (i) adaptively transferring the most useful source knowledge to facilitate dynamics learning, and (ii) learning to replay the most relevant source actions to guide the target policy. We demonstrate the advantages of Vid2Act over the action-free visual RL pretraining method in both Meta-World and DeepMind Control Suite.
Model-Based Reinforcement Learning with Isolated Imaginations
Mar 27, 2023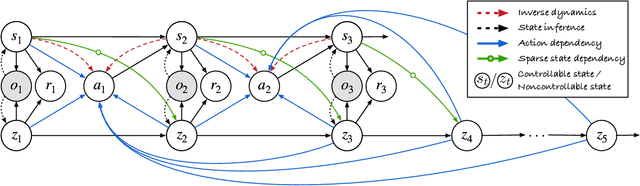

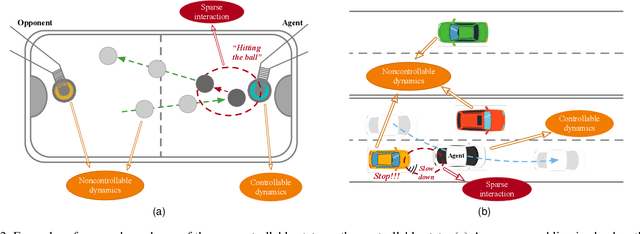
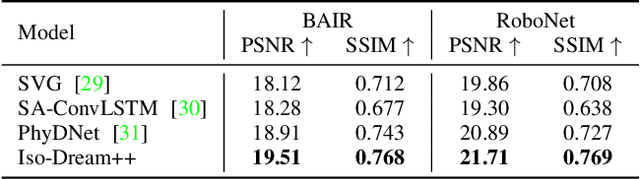
World models learn the consequences of actions in vision-based interactive systems. However, in practical scenarios like autonomous driving, noncontrollable dynamics that are independent or sparsely dependent on action signals often exist, making it challenging to learn effective world models. To address this issue, we propose Iso-Dream++, a model-based reinforcement learning approach that has two main contributions. First, we optimize the inverse dynamics to encourage the world model to isolate controllable state transitions from the mixed spatiotemporal variations of the environment. Second, we perform policy optimization based on the decoupled latent imaginations, where we roll out noncontrollable states into the future and adaptively associate them with the current controllable state. This enables long-horizon visuomotor control tasks to benefit from isolating mixed dynamics sources in the wild, such as self-driving cars that can anticipate the movement of other vehicles, thereby avoiding potential risks. On top of our previous work, we further consider the sparse dependencies between controllable and noncontrollable states, address the training collapse problem of state decoupling, and validate our approach in transfer learning setups. Our empirical study demonstrates that Iso-Dream++ outperforms existing reinforcement learning models significantly on CARLA and DeepMind Control.
Isolating and Leveraging Controllable and Noncontrollable Visual Dynamics in World Models
May 27, 2022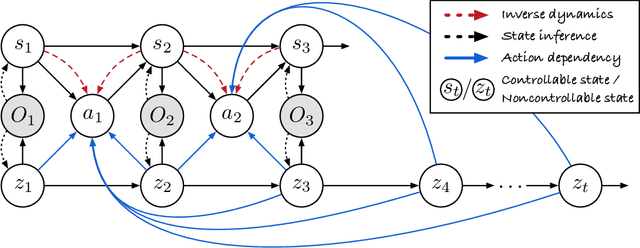
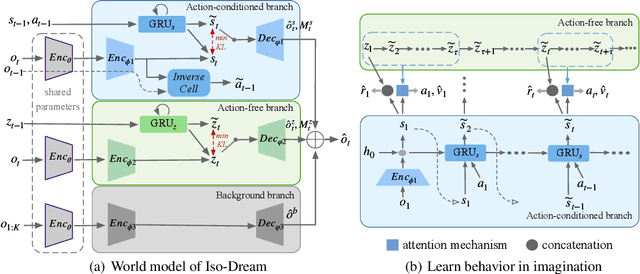
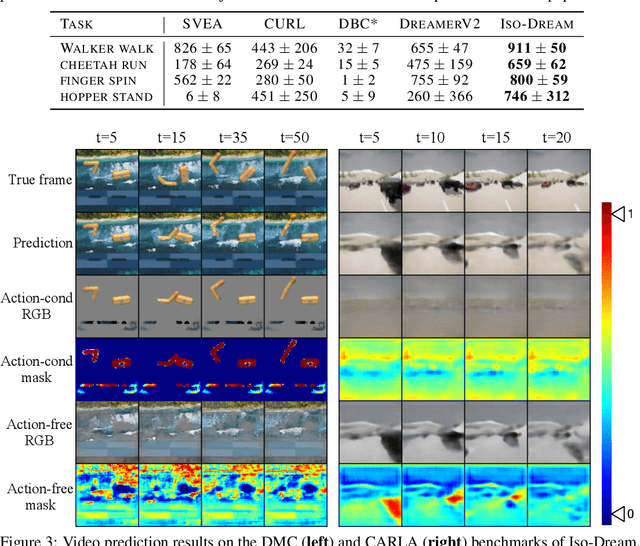

World models learn the consequences of actions in vision-based interactive systems. However, in practical scenarios such as autonomous driving, there commonly exists noncontrollable dynamics independent of the action signals, making it difficult to learn effective world models. To tackle this problem, we present a novel reinforcement learning approach named Iso-Dream, which improves the Dream-to-Control framework in two aspects. First, by optimizing the inverse dynamics, we encourage the world model to learn controllable and noncontrollable sources of spatiotemporal changes on isolated state transition branches. Second, we optimize the behavior of the agent on the decoupled latent imaginations of the world model. Specifically, to estimate state values, we roll-out the noncontrollable states into the future and associate them with the current controllable state. In this way, the isolation of dynamics sources can greatly benefit long-horizon decision-making of the agent, such as a self-driving car that can avoid potential risks by anticipating the movement of other vehicles. Experiments show that Iso-Dream is effective in decoupling the mixed dynamics and remarkably outperforms existing approaches in a wide range of visual control and prediction domains.