 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Scene Understanding through Object-Centric Voxelization and Neural Rendering
Jul 30, 2024


Learning object-centric representations from unsupervised videos is challenging. Unlike most previous approaches that focus on decomposing 2D images, we present a 3D generative model named DynaVol-S for dynamic scenes that enables object-centric learning within a differentiable volume rendering framework. The key idea is to perform object-centric voxelization to capture the 3D nature of the scene, which infers per-object occupancy probabilities at individual spatial locations. These voxel features evolve through a canonical-space deformation function and are optimized in an inverse rendering pipeline with a compositional NeRF. Additionally, our approach integrates 2D semantic features to create 3D semantic grids, representing the scene through multiple disentangled voxel grids. DynaVol-S significantly outperforms existing models in both novel view synthesis and unsupervised decomposition tasks for dynamic scenes. By jointly considering geometric structures and semantic features, it effectively addresses challenging real-world scenarios involving complex object interactions. Furthermore, once trained, the explicitly meaningful voxel features enable additional capabilities that 2D scene decomposition methods cannot achieve, such as novel scene generation through editing geometric shapes or manipulating the motion trajectories of objects.
Never Miss A Beat: An Efficient Recipe for Context Window Extension of Large Language Models with Consistent "Middle" Enhancement
Jun 11, 2024Recently, many methods have been developed to extend the context length of pre-trained large language models (LLMs), but they often require fine-tuning at the target length ($\gg4K$) and struggle to effectively utilize information from the middle part of the context. To address these issues, we propose $\textbf{C}$ontinuity-$\textbf{R}$elativity ind$\textbf{E}$xing with g$\textbf{A}$ussian $\textbf{M}$iddle (CREAM), which interpolates positional encodings by manipulating position indices. Apart from being simple, CREAM is training-efficient: it only requires fine-tuning at the pre-trained context window (eg, Llama 2-4K) and can extend LLMs to a much longer target context length (eg, 256K). To ensure that the model focuses more on the information in the middle, we introduce a truncated Gaussian to encourage sampling from the middle part of the context during fine-tuning, thus alleviating the ``Lost-in-the-Middle'' problem faced by long-context LLMs. Experimental results show that CREAM successfully extends LLMs to the target length for both Base and Chat versions of $\texttt{Llama2-7B}$ with ``Never Miss A Beat''. Our code will be publicly available soon.
On the Transferability of Visually Grounded PCFGs
Oct 21, 2023



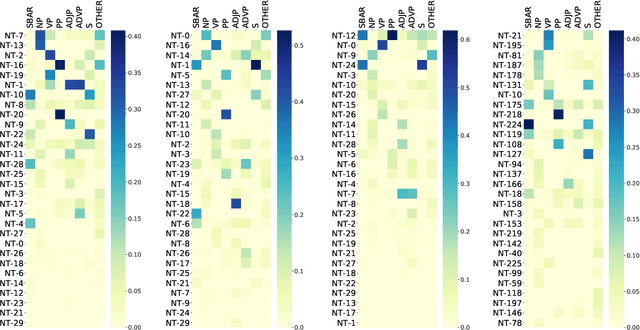
There has been a significant surge of interest in visually grounded grammar induction in recent times. While a variety of models have been developed for the task and have demonstrated impressive performance, they have not been evaluated on text domains that are different from the training domain, so it is unclear if the improvements brought by visual groundings are transferable. Our study aims to fill this gap and assess the degree of transferability. We start by extending VC-PCFG (short for Visually-grounded Compound PCFG~\citep{zhao-titov-2020-visually}) in such a way that it can transfer across text domains. We consider a zero-shot transfer learning setting where a model is trained on the source domain and is directly applied to target domains, without any further training. Our experimental results suggest that: the benefits from using visual groundings transfer to text in a domain similar to the training domain but fail to transfer to remote domains. Further, we conduct data and result analysis; we find that the lexicon overlap between the source domain and the target domain is the most important factor in the transferability of VC-PCFG.
Object-Centric Voxelization of Dynamic Scenes via Inverse Neural Rendering
Apr 30, 2023Understanding the compositional dynamics of the world in unsupervised 3D scenarios is challenging. Existing approaches either fail to make effective use of time cues or ignore the multi-view consistency of scene decomposition. In this paper, we propose DynaVol, an inverse neural rendering framework that provides a pilot study for learning time-varying volumetric representations for dynamic scenes with multiple entities (like objects). It has two main contributions. First, it maintains a time-dependent 3D grid, which dynamically and flexibly binds the spatial locations to different entities, thus encouraging the separation of information at a representational level. Second, our approach jointly learns grid-level local dynamics, object-level global dynamics, and the compositional neural radiance fields in an end-to-end architecture, thereby enhancing the spatiotemporal consistency of object-centric scene voxelization. We present a two-stage training scheme for DynaVol and validate its effectiveness on various benchmarks with multiple objects, diverse dynamics, and real-world shapes and textures. We present visualization at https://sites.google.com/view/dynavol-visual.
MERLOT Reserve: Neural Script Knowledge through Vision and Language and Sound
Jan 07, 2022
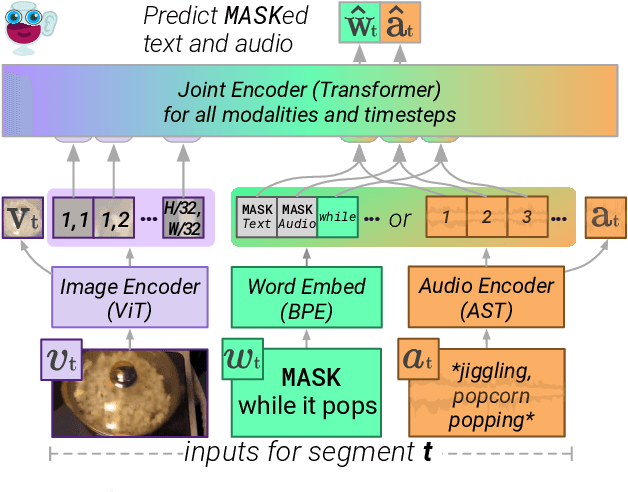

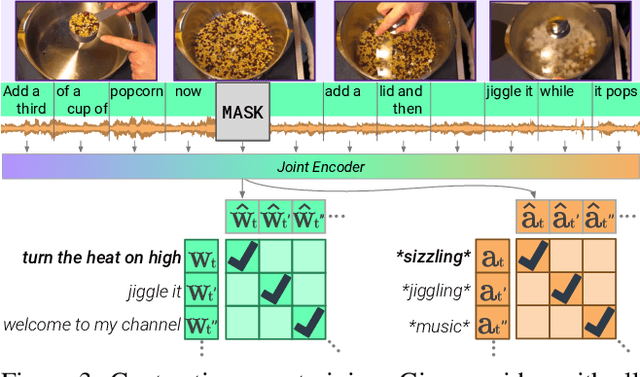
As humans, we navigate the world through all our senses, using perceptual input from each one to correct the others. We introduce MERLOT Reserve, a model that represents videos jointly over time -- through a new training objective that learns from audio, subtitles, and video frames. Given a video, we replace snippets of text and audio with a MASK token; the model learns by choosing the correct masked-out snippet. Our objective learns faster than alternatives, and performs well at scale: we pretrain on 20 million YouTube videos. Empirical results show that MERLOT Reserve learns strong representations about videos through all constituent modalities. When finetuned, it sets a new state-of-the-art on both VCR and TVQA, outperforming prior work by 5% and 7% respectively. Ablations show that both tasks benefit from audio pretraining -- even VCR, a QA task centered around images (without sound). Moreover, our objective enables out-of-the-box prediction, revealing strong multimodal commonsense understanding. In a fully zero-shot setting, our model obtains competitive results on four video understanding tasks, even outperforming supervised approaches on the recently proposed Situated Reasoning (STAR) benchmark. We analyze why incorporating audio leads to better vision-language representations, suggesting significant opportunities for future research. We conclude by discussing ethical and societal implications of multimodal pretraining.
Connecting the Dots between Audio and Text without Parallel Data through Visual Knowledge Transfer
Dec 16, 2021

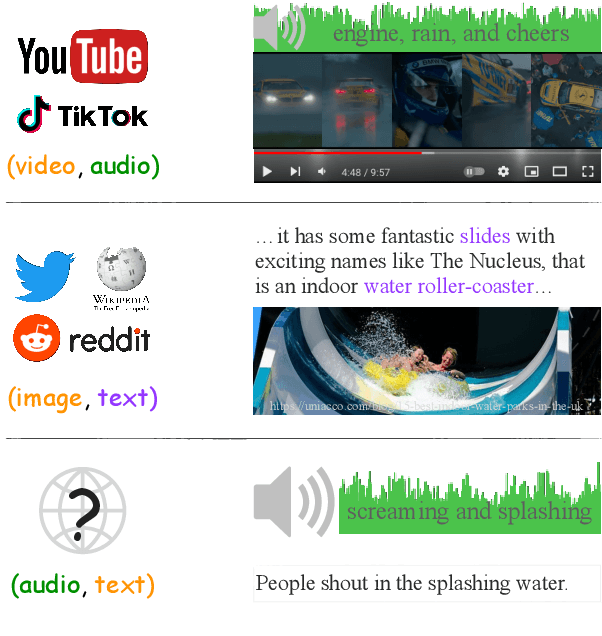

Machines that can represent and describe environmental soundscapes have practical potential, e.g., for audio tagging and captioning systems. Prevailing learning paradigms have been relying on parallel audio-text data, which is, however, scarcely available on the web. We propose VIP-ANT that induces \textbf{A}udio-\textbf{T}ext alignment without using any parallel audio-text data. Our key idea is to share the image modality between bi-modal image-text representations and bi-modal image-audio representations; the image modality functions as a pivot and connects audio and text in a tri-modal embedding space implicitly. In a difficult zero-shot setting with no paired audio-text data, our model demonstrates state-of-the-art zero-shot performance on the ESC50 and US8K audio classification tasks, and even surpasses the supervised state of the art for Clotho caption retrieval (with audio queries) by 2.2\% R@1. We further investigate cases of minimal audio-text supervision, finding that, e.g., just a few hundred supervised audio-text pairs increase the zero-shot audio classification accuracy by 8\% on US8K. However, to match human parity on some zero-shot tasks, our empirical scaling experiments suggest that we would need about $2^{21} \approx 2M$ supervised audio-caption pairs. Our work opens up new avenues for learning audio-text connections with little to no parallel audio-text data.
Neural Bi-Lexicalized PCFG Induction
May 31, 2021



Neural lexicalized PCFGs (L-PCFGs) have been shown effective in grammar induction. However, to reduce computational complexity, they make a strong independence assumption on the generation of the child word and thus bilexical dependencies are ignored. In this paper, we propose an approach to parameterize L-PCFGs without making implausible independence assumptions. Our approach directly models bilexical dependencies and meanwhile reduces both learning and representation complexities of L-PCFGs. Experimental results on the English WSJ dataset confirm the effectiveness of our approach in improving both running speed and unsupervised parsing performance.
PCFGs Can Do Better: Inducing Probabilistic Context-Free Grammars with Many Symbols
Apr 28, 2021


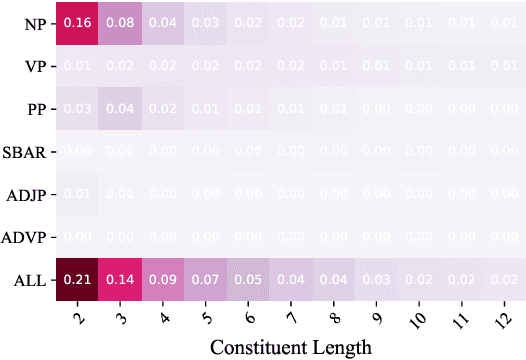
Probabilistic context-free grammars (PCFGs) with neural parameterization have been shown to be effective in unsupervised phrase-structure grammar induction. However, due to the cubic computational complexity of PCFG representation and parsing, previous approaches cannot scale up to a relatively large number of (nonterminal and preterminal) symbols. In this work, we present a new parameterization form of PCFGs based on tensor decomposition, which has at most quadratic computational complexity in the symbol number and therefore allows us to use a much larger number of symbols. We further use neural parameterization for the new form to improve unsupervised parsing performance. We evaluate our model across ten languages and empirically demonstrate the effectiveness of using more symbols. Our code: https://github.com/sustcsonglin/TN-PCFG
An Empirical Study of Compound PCFGs
Mar 03, 2021


Compound probabilistic context-free grammars (C-PCFGs) have recently established a new state of the art for phrase-structure grammar induction. However, due to the high time-complexity of chart-based representation and inference, it is difficult to investigate them comprehensively. In this work, we rely on a fast implementation of C-PCFGs to conduct evaluation complementary to that of~\citet{kim-etal-2019-compound}. We highlight three key findings: (1) C-PCFGs are data-efficient, (2) C-PCFGs make the best use of global sentence-level information in preterminal rule probabilities, and (3) the best configurations of C-PCFGs on English do not always generalize to morphology-rich languages.
Visually Grounded Compound PCFGs
Sep 25, 2020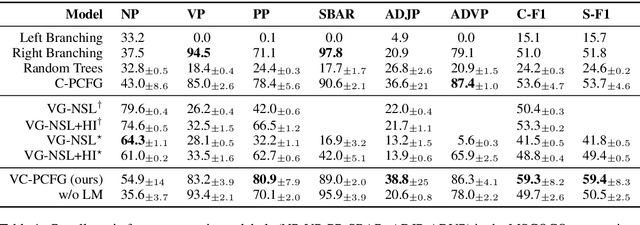
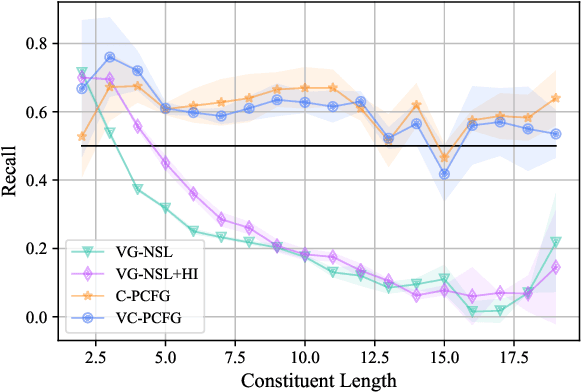

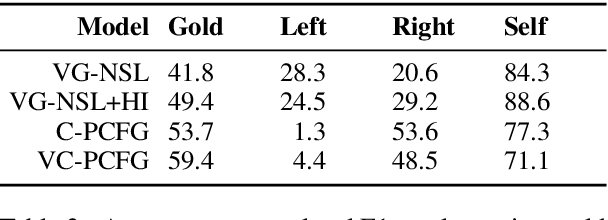
Exploiting visual groundings for language understanding has recently been drawing much attention. In this work, we study visually grounded grammar induction and learn a constituency parser from both unlabeled text and its visual groundings. Existing work on this task (Shi et al., 2019) optimizes a parser via Reinforce and derives the learning signal only from the alignment of images and sentences. While their model is relatively accurate overall, its error distribution is very uneven, with low performance on certain constituents types (e.g., 26.2% recall on verb phrases, VPs) and high on others (e.g., 79.6% recall on noun phrases, NPs). This is not surprising as the learning signal is likely insufficient for deriving all aspects of phrase-structure syntax and gradient estimates are noisy. We show that using an extension of probabilistic context-free grammar model we can do fully-differentiable end-to-end visually grounded learning. Additionally, this enables us to complement the image-text alignment loss with a language modeling objective. On the MSCOCO test captions, our model establishes a new state of the art, outperforming its non-grounded version and, thus, confirming the effectiveness of visual groundings in constituency grammar induction. It also substantially outperforms the previous grounded model, with largest improvements on more `abstract' categories (e.g., +55.1% recall on VPs).