 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisually Grounded Compound PCFGs
Paper and Code
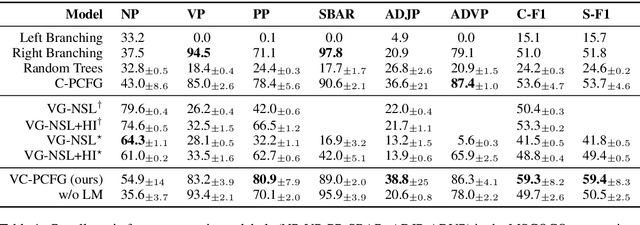
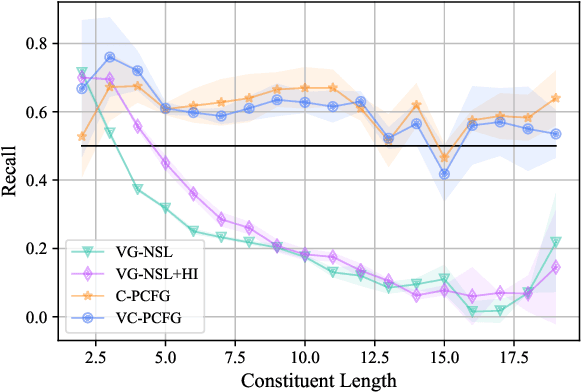

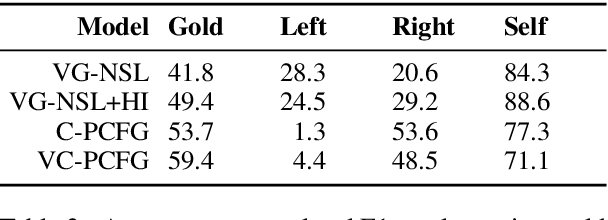
Exploiting visual groundings for language understanding has recently been drawing much attention. In this work, we study visually grounded grammar induction and learn a constituency parser from both unlabeled text and its visual groundings. Existing work on this task (Shi et al., 2019) optimizes a parser via Reinforce and derives the learning signal only from the alignment of images and sentences. While their model is relatively accurate overall, its error distribution is very uneven, with low performance on certain constituents types (e.g., 26.2% recall on verb phrases, VPs) and high on others (e.g., 79.6% recall on noun phrases, NPs). This is not surprising as the learning signal is likely insufficient for deriving all aspects of phrase-structure syntax and gradient estimates are noisy. We show that using an extension of probabilistic context-free grammar model we can do fully-differentiable end-to-end visually grounded learning. Additionally, this enables us to complement the image-text alignment loss with a language modeling objective. On the MSCOCO test captions, our model establishes a new state of the art, outperforming its non-grounded version and, thus, confirming the effectiveness of visual groundings in constituency grammar induction. It also substantially outperforms the previous grounded model, with largest improvements on more `abstract' categories (e.g., +55.1% recall on VPs).