 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMERLOT Reserve: Neural Script Knowledge through Vision and Language and Sound
Paper and Code
Jan 07, 2022
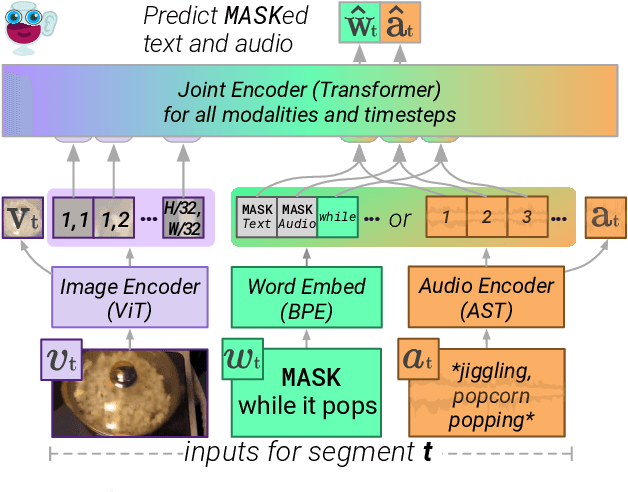

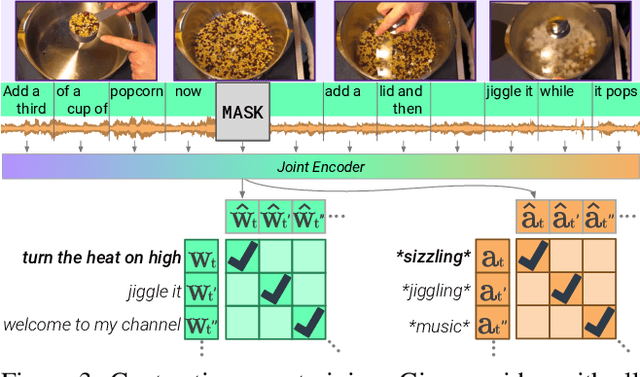
As humans, we navigate the world through all our senses, using perceptual input from each one to correct the others. We introduce MERLOT Reserve, a model that represents videos jointly over time -- through a new training objective that learns from audio, subtitles, and video frames. Given a video, we replace snippets of text and audio with a MASK token; the model learns by choosing the correct masked-out snippet. Our objective learns faster than alternatives, and performs well at scale: we pretrain on 20 million YouTube videos. Empirical results show that MERLOT Reserve learns strong representations about videos through all constituent modalities. When finetuned, it sets a new state-of-the-art on both VCR and TVQA, outperforming prior work by 5% and 7% respectively. Ablations show that both tasks benefit from audio pretraining -- even VCR, a QA task centered around images (without sound). Moreover, our objective enables out-of-the-box prediction, revealing strong multimodal commonsense understanding. In a fully zero-shot setting, our model obtains competitive results on four video understanding tasks, even outperforming supervised approaches on the recently proposed Situated Reasoning (STAR) benchmark. We analyze why incorporating audio leads to better vision-language representations, suggesting significant opportunities for future research. We conclude by discussing ethical and societal implications of multimodal pretraining.