 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Multimodal Planning Agent for Visual Question-Answering
Jan 28, 2026Visual Question-Answering (VQA) is a challenging multimodal task that requires integrating visual and textual information to generate accurate responses. While multimodal Retrieval-Augmented Generation (mRAG) has shown promise in enhancing VQA systems by providing more evidence on both image and text sides, the default procedure that addresses VQA queries, especially the knowledge-intensive ones, often relies on multi-stage pipelines of mRAG with inherent dependencies. To mitigate the inefficiency limitations while maintaining VQA task performance, this paper proposes a method that trains a multimodal planning agent, dynamically decomposing the mRAG pipeline to solve the VQA task. Our method optimizes the trade-off between efficiency and effectiveness by training the agent to intelligently determine the necessity of each mRAG step. In our experiments, the agent can help reduce redundant computations, cutting search time by over 60\% compared to existing methods and decreasing costly tool calls. Meanwhile, experiments demonstrate that our method outperforms all baselines, including a Deep Research agent and a carefully designed prompt-based method, on average over six various datasets. Code will be released.
EvolveSearch: An Iterative Self-Evolving Search Agent
May 28, 2025The rapid advancement of large language models (LLMs) has transformed the landscape of agentic information seeking capabilities through the integration of tools such as search engines and web browsers. However, current mainstream approaches for enabling LLM web search proficiency face significant challenges: supervised fine-tuning struggles with data production in open-search domains, while RL converges quickly, limiting their data utilization efficiency. To address these issues, we propose EvolveSearch, a novel iterative self-evolution framework that combines SFT and RL to enhance agentic web search capabilities without any external human-annotated reasoning data. Extensive experiments on seven multi-hop question-answering (MHQA) benchmarks demonstrate that EvolveSearch consistently improves performance across iterations, ultimately achieving an average improvement of 4.7\% over the current state-of-the-art across seven benchmarks, opening the door to self-evolution agentic capabilities in open web search domains.
Random Long-Context Access for Mamba via Hardware-aligned Hierarchical Sparse Attention
Apr 23, 2025A key advantage of Recurrent Neural Networks (RNNs) over Transformers is their linear computational and space complexity enables faster training and inference for long sequences. However, RNNs are fundamentally unable to randomly access historical context, and simply integrating attention mechanisms may undermine their efficiency advantages. To overcome this limitation, we propose \textbf{H}ierarchical \textbf{S}parse \textbf{A}ttention (HSA), a novel attention mechanism that enhances RNNs with long-range random access flexibility while preserving their merits in efficiency and length generalization. HSA divides inputs into chunks, selecting the top-$k$ chunks and hierarchically aggregates information. The core innovation lies in learning token-to-chunk relevance based on fine-grained token-level information inside each chunk. This approach enhances the precision of chunk selection across both in-domain and out-of-domain context lengths. To make HSA efficient, we further introduce a hardware-aligned kernel design. By combining HSA with Mamba, we introduce RAMba, which achieves perfect accuracy in passkey retrieval across 64 million contexts despite pre-training on only 4K-length contexts, and significant improvements on various downstream tasks, with nearly constant memory footprint. These results show RAMba's huge potential in long-context modeling.
Detecting Knowledge Boundary of Vision Large Language Models by Sampling-Based Inference
Feb 25, 2025Despite the advancements made in Visual Large Language Models (VLLMs), like text Large Language Models (LLMs), they have limitations in addressing questions that require real-time information or are knowledge-intensive. Indiscriminately adopting Retrieval Augmented Generation (RAG) techniques is an effective yet expensive way to enable models to answer queries beyond their knowledge scopes. To mitigate the dependence on retrieval and simultaneously maintain, or even improve, the performance benefits provided by retrieval, we propose a method to detect the knowledge boundary of VLLMs, allowing for more efficient use of techniques like RAG. Specifically, we propose a method with two variants that fine-tunes a VLLM on an automatically constructed dataset for boundary identification. Experimental results on various types of Visual Question Answering datasets show that our method successfully depicts a VLLM's knowledge boundary based on which we are able to reduce indiscriminate retrieval while maintaining or improving the performance. In addition, we show that the knowledge boundary identified by our method for one VLLM can be used as a surrogate boundary for other VLLMs. Code will be released at https://github.com/Chord-Chen-30/VLLM-KnowledgeBoundary
A Systematic Study of Cross-Layer KV Sharing for Efficient LLM Inference
Oct 18, 2024



Recently, sharing key-value (KV) cache across layers has been found effective in efficient inference of large language models (LLMs). To systematically investigate different techniques of cross-layer KV sharing, we propose a unified framework that covers several recent methods and their novel variants. We conduct comprehensive experiments on all the configurations of the framework, evaluating their generation throughput and performance in language modeling and downstream tasks. We find that when reducing the size of the KV cache by 2x, most configurations can achieve competitive performance to and higher throughput than standard transformers, but when further reducing the size of the KV cache, pairing queries of all layers with KVs of upper layers can better maintain performance, although it also introduces additional training cost and prefilling latency. We hope that this work will help users choose the appropriate approach according to their requirements and facilitate research on the acceleration of LLM inference.
Efficient Long-range Language Modeling with Self-supervised Causal Retrieval
Oct 02, 2024Recently, retrieval-based language models (RLMs) have received much attention. However, most of them leverage a pre-trained retriever with fixed parameters, which may not adapt well to causal language models. In this work, we propose Grouped Cross-Attention, a novel module enabling joint pre-training of the retriever and causal LM, and apply it to long-context modeling. For a given input sequence, we split it into chunks and use the current chunk to retrieve past chunks for subsequent text generation. Our innovation allows the retriever to learn how to retrieve past chunks that better minimize the auto-regressive loss of subsequent tokens in an end-to-end manner. By integrating top-$k$ retrieval, our model can be pre-trained efficiently from scratch with context lengths up to 64K tokens. Our experiments show our model, compared with long-range LM baselines, can achieve lower perplexity with comparable or lower pre-training and inference costs.
Learning Robust Named Entity Recognizers From Noisy Data With Retrieval Augmentation
Jul 26, 2024



Named entity recognition (NER) models often struggle with noisy inputs, such as those with spelling mistakes or errors generated by Optical Character Recognition processes, and learning a robust NER model is challenging. Existing robust NER models utilize both noisy text and its corresponding gold text for training, which is infeasible in many real-world applications in which gold text is not available. In this paper, we consider a more realistic setting in which only noisy text and its NER labels are available. We propose to retrieve relevant text of the noisy text from a knowledge corpus and use it to enhance the representation of the original noisy input. We design three retrieval methods: sparse retrieval based on lexicon similarity, dense retrieval based on semantic similarity, and self-retrieval based on task-specific text. After retrieving relevant text, we concatenate the retrieved text with the original noisy text and encode them with a transformer network, utilizing self-attention to enhance the contextual token representations of the noisy text using the retrieved text. We further employ a multi-view training framework that improves robust NER without retrieving text during inference. Experiments show that our retrieval-augmented model achieves significant improvements in various noisy NER settings.
Dependency Transformer Grammars: Integrating Dependency Structures into Transformer Language Models
Jul 24, 2024Syntactic Transformer language models aim to achieve better generalization through simultaneously modeling syntax trees and sentences. While prior work has been focusing on adding constituency-based structures to Transformers, we introduce Dependency Transformer Grammars (DTGs), a new class of Transformer language model with explicit dependency-based inductive bias. DTGs simulate dependency transition systems with constrained attention patterns by modifying attention masks, incorporate the stack information through relative positional encoding, and augment dependency arc representation with a combination of token embeddings and operation embeddings. When trained on a dataset of sentences annotated with dependency trees, DTGs achieve better generalization while maintaining comparable perplexity with Transformer language model baselines. DTGs also outperform recent constituency-based models, showing that dependency can better guide Transformer language models. Our code is released at https://github.com/zhaoyd1/Dep_Transformer_Grammars.
Sparser is Faster and Less is More: Efficient Sparse Attention for Long-Range Transformers
Jun 24, 2024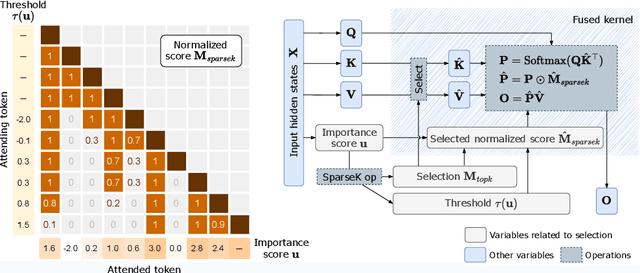
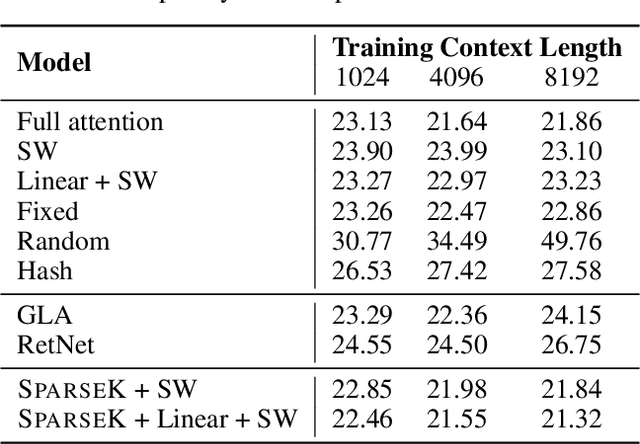
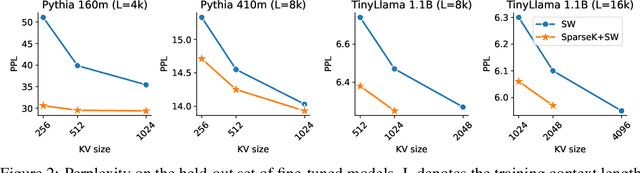
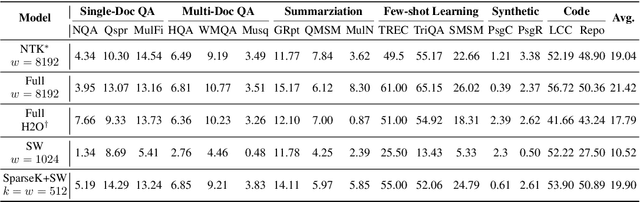
Accommodating long sequences efficiently in autoregressive Transformers, especially within an extended context window, poses significant challenges due to the quadratic computational complexity and substantial KV memory requirements inherent in self-attention mechanisms. In this work, we introduce SPARSEK Attention, a novel sparse attention mechanism designed to overcome these computational and memory obstacles while maintaining performance. Our approach integrates a scoring network and a differentiable top-k mask operator, SPARSEK, to select a constant number of KV pairs for each query, thereby enabling gradient-based optimization. As a result, SPARSEK Attention offers linear time complexity and constant memory footprint during generation. Experimental results reveal that SPARSEK Attention outperforms previous sparse attention methods and provides significant speed improvements during both training and inference, particularly in language modeling and downstream tasks. Furthermore, our method can be seamlessly integrated into pre-trained Large Language Models (LLMs) with minimal fine-tuning, offering a practical solution for effectively managing long-range dependencies in diverse applications.
Unsupervised Morphological Tree Tokenizer
Jun 21, 2024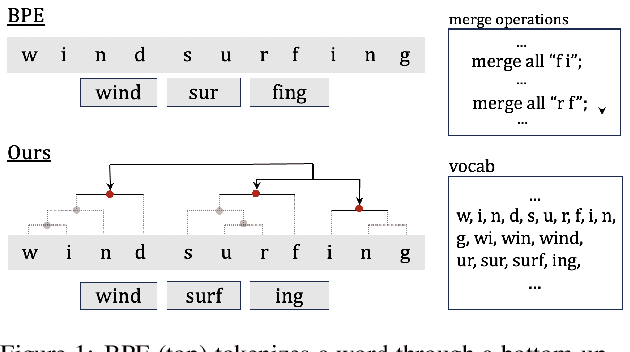
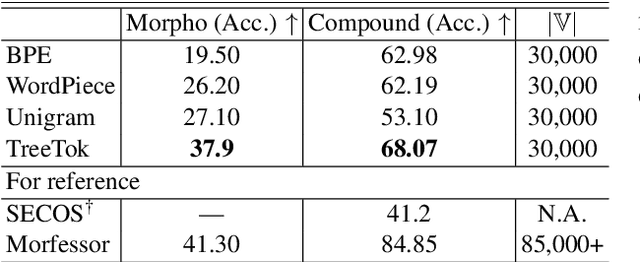
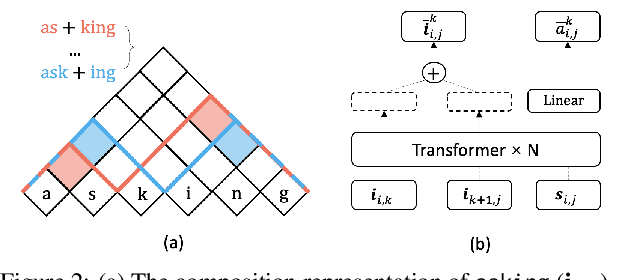
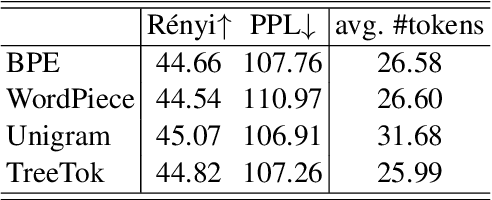
As a cornerstone in language modeling, tokenization involves segmenting text inputs into pre-defined atomic units. Conventional statistical tokenizers often disrupt constituent boundaries within words, thereby corrupting semantic information. To address this drawback, we introduce morphological structure guidance to tokenization and propose a deep model to induce character-level structures of words. Specifically, the deep model jointly encodes internal structures and representations of words with a mechanism named $\textit{MorphOverriding}$ to ensure the indecomposability of morphemes. By training the model with self-supervised objectives, our method is capable of inducing character-level structures that align with morphological rules without annotated training data. Based on the induced structures, our algorithm tokenizes words through vocabulary matching in a top-down manner. Empirical results indicate that the proposed method effectively retains complete morphemes and outperforms widely adopted methods such as BPE and WordPiece on both morphological segmentation tasks and language modeling tasks. The code will be released later.