 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebSailor-V2: Bridging the Chasm to Proprietary Agents via Synthetic Data and Scalable Reinforcement Learning
Sep 16, 2025



Transcending human cognitive limitations represents a critical frontier in LLM training. Proprietary agentic systems like DeepResearch have demonstrated superhuman capabilities on extremely complex information-seeking benchmarks such as BrowseComp, a feat previously unattainable. We posit that their success hinges on a sophisticated reasoning pattern absent in open-source models: the ability to systematically reduce extreme uncertainty when navigating vast information landscapes. Based on this insight, we introduce WebSailor, a complete post-training methodology designed to instill this crucial capability. Our approach involves generating novel, high-uncertainty tasks through structured sampling and information obfuscation, RFT cold start, and an efficient agentic RL training algorithm, Duplicating Sampling Policy Optimization (DUPO). With this integrated pipeline, WebSailor significantly outperforms all open-source agents in complex information-seeking tasks, matching proprietary agents' performance and closing the capability gap.
ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization
Sep 16, 2025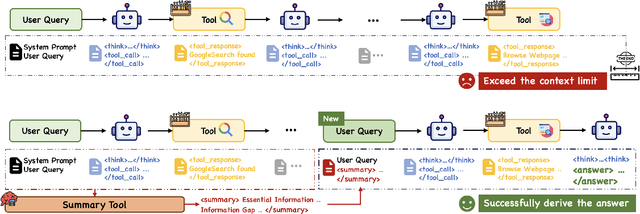
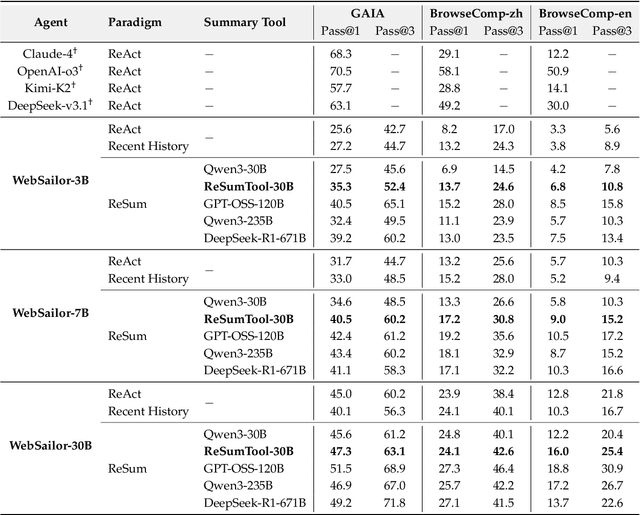
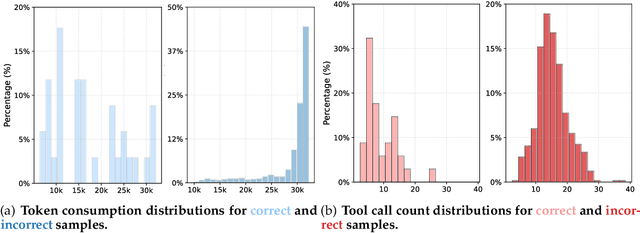
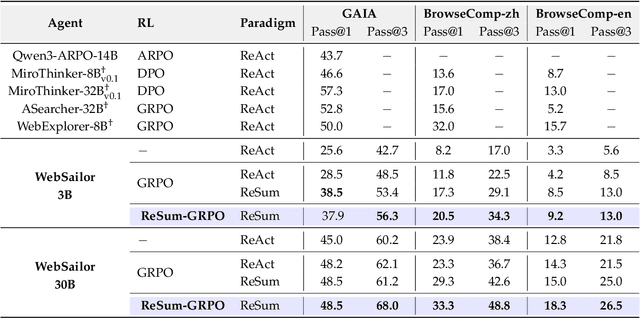
Large Language Model (LLM)-based web agents demonstrate strong performance on knowledge-intensive tasks but are hindered by context window limitations in paradigms like ReAct. Complex queries involving multiple entities, intertwined relationships, and high uncertainty demand extensive search cycles that rapidly exhaust context budgets before reaching complete solutions. To overcome this challenge, we introduce ReSum, a novel paradigm that enables indefinite exploration through periodic context summarization. ReSum converts growing interaction histories into compact reasoning states, maintaining awareness of prior discoveries while bypassing context constraints. For paradigm adaptation, we propose ReSum-GRPO, integrating GRPO with segmented trajectory training and advantage broadcasting to familiarize agents with summary-conditioned reasoning. Extensive experiments on web agents of varying scales across three benchmarks demonstrate that ReSum delivers an average absolute improvement of 4.5\% over ReAct, with further gains of up to 8.2\% following ReSum-GRPO training. Notably, with only 1K training samples, our WebResummer-30B (a ReSum-GRPO-trained version of WebSailor-30B) achieves 33.3\% Pass@1 on BrowseComp-zh and 18.3\% on BrowseComp-en, surpassing existing open-source web agents.
EvolveSearch: An Iterative Self-Evolving Search Agent
May 28, 2025The rapid advancement of large language models (LLMs) has transformed the landscape of agentic information seeking capabilities through the integration of tools such as search engines and web browsers. However, current mainstream approaches for enabling LLM web search proficiency face significant challenges: supervised fine-tuning struggles with data production in open-search domains, while RL converges quickly, limiting their data utilization efficiency. To address these issues, we propose EvolveSearch, a novel iterative self-evolution framework that combines SFT and RL to enhance agentic web search capabilities without any external human-annotated reasoning data. Extensive experiments on seven multi-hop question-answering (MHQA) benchmarks demonstrate that EvolveSearch consistently improves performance across iterations, ultimately achieving an average improvement of 4.7\% over the current state-of-the-art across seven benchmarks, opening the door to self-evolution agentic capabilities in open web search domains.
Dependency Transformer Grammars: Integrating Dependency Structures into Transformer Language Models
Jul 24, 2024Syntactic Transformer language models aim to achieve better generalization through simultaneously modeling syntax trees and sentences. While prior work has been focusing on adding constituency-based structures to Transformers, we introduce Dependency Transformer Grammars (DTGs), a new class of Transformer language model with explicit dependency-based inductive bias. DTGs simulate dependency transition systems with constrained attention patterns by modifying attention masks, incorporate the stack information through relative positional encoding, and augment dependency arc representation with a combination of token embeddings and operation embeddings. When trained on a dataset of sentences annotated with dependency trees, DTGs achieve better generalization while maintaining comparable perplexity with Transformer language model baselines. DTGs also outperform recent constituency-based models, showing that dependency can better guide Transformer language models. Our code is released at https://github.com/zhaoyd1/Dep_Transformer_Grammars.
Progressive Learning for Image Retrieval with Hybrid-Modality Queries
Apr 24, 2022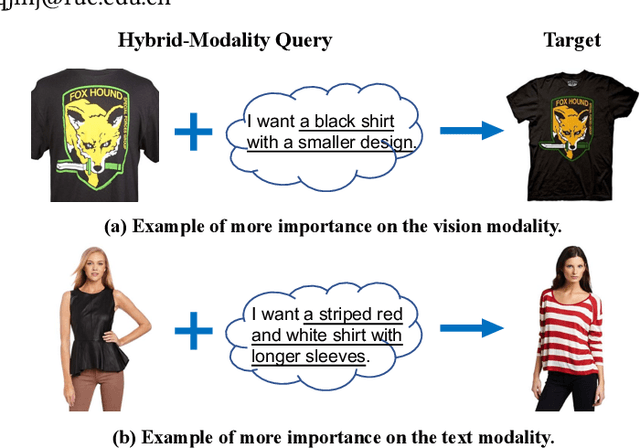
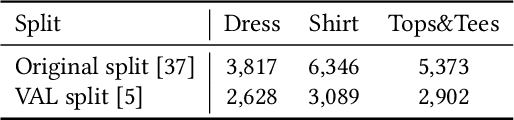
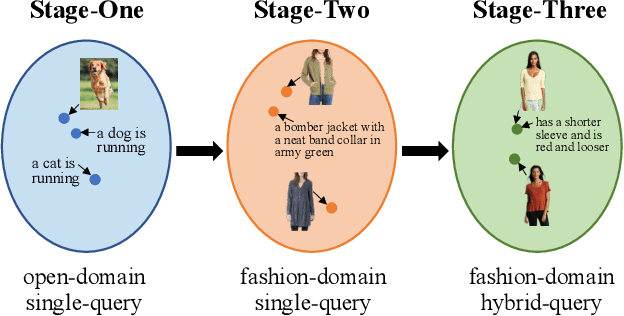
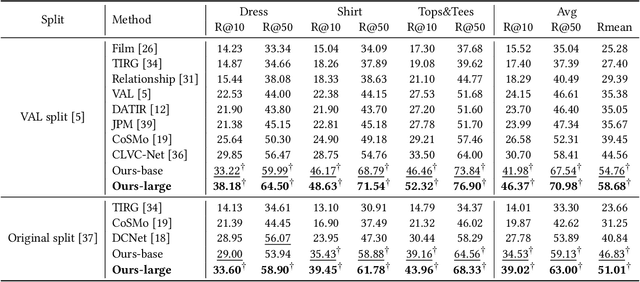
Image retrieval with hybrid-modality queries, also known as composing text and image for image retrieval (CTI-IR), is a retrieval task where the search intention is expressed in a more complex query format, involving both vision and text modalities. For example, a target product image is searched using a reference product image along with text about changing certain attributes of the reference image as the query. It is a more challenging image retrieval task that requires both semantic space learning and cross-modal fusion. Previous approaches that attempt to deal with both aspects achieve unsatisfactory performance. In this paper, we decompose the CTI-IR task into a three-stage learning problem to progressively learn the complex knowledge for image retrieval with hybrid-modality queries. We first leverage the semantic embedding space for open-domain image-text retrieval, and then transfer the learned knowledge to the fashion-domain with fashion-related pre-training tasks. Finally, we enhance the pre-trained model from single-query to hybrid-modality query for the CTI-IR task. Furthermore, as the contribution of individual modality in the hybrid-modality query varies for different retrieval scenarios, we propose a self-supervised adaptive weighting strategy to dynamically determine the importance of image and text in the hybrid-modality query for better retrieval. Extensive experiments show that our proposed model significantly outperforms state-of-the-art methods in the mean of Recall@K by 24.9% and 9.5% on the Fashion-IQ and Shoes benchmark datasets respectively.
WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training
Mar 19, 2021
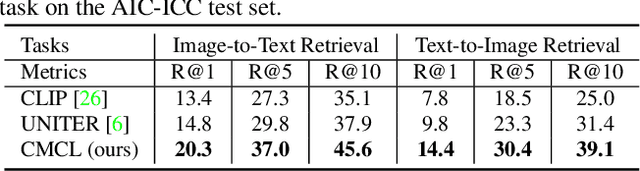
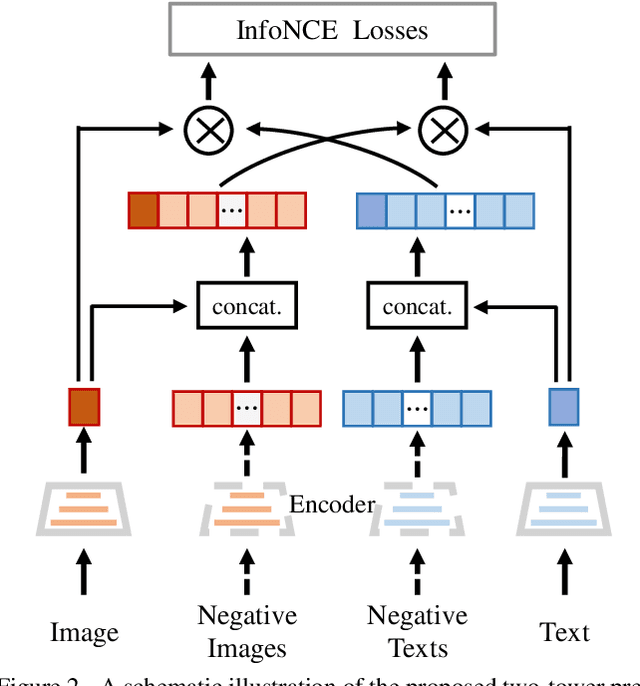
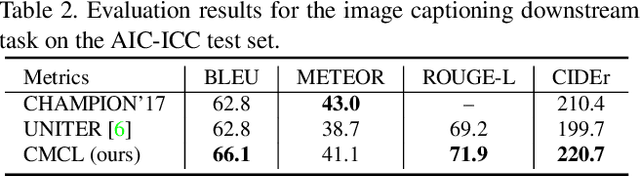
Multi-modal pre-training models have been intensively explored to bridge vision and language in recent years. However, most of them explicitly model the cross-modal interaction between image-text pairs, by assuming that there exists strong semantic correlation between the text and image modalities. Since this strong assumption is often invalid in real-world scenarios, we choose to implicitly model the cross-modal correlation for large-scale multi-modal pre-training, which is the focus of the Chinese project `WenLan' led by our team. Specifically, with the weak correlation assumption over image-text pairs, we propose a two-tower pre-training model called BriVL within the cross-modal contrastive learning framework. Unlike OpenAI CLIP that adopts a simple contrastive learning method, we devise a more advanced algorithm by adapting the latest method MoCo into the cross-modal scenario. By building a large queue-based dictionary, our BriVL can incorporate more negative samples in limited GPU resources. We further construct a large Chinese multi-source image-text dataset called RUC-CAS-WenLan for pre-training our BriVL model. Extensive experiments demonstrate that the pre-trained BriVL model outperforms both UNITER and OpenAI CLIP on various downstream tasks.
The End-of-End-to-End: A Video Understanding Pentathlon Challenge
Aug 03, 2020
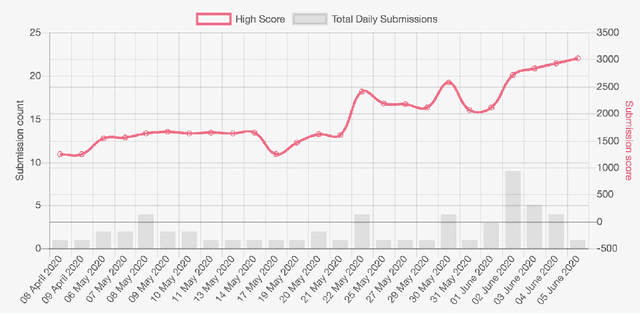
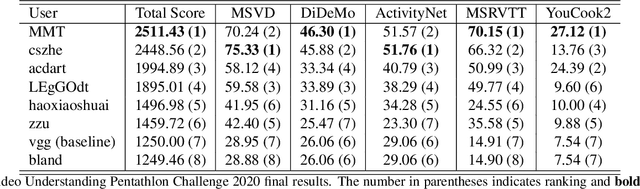
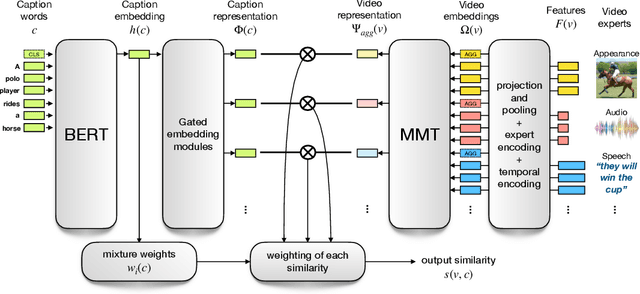
We present a new video understanding pentathlon challenge, an open competition held in conjunction with the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2020. The objective of the challenge was to explore and evaluate new methods for text-to-video retrieval-the task of searching for content within a corpus of videos using natural language queries. This report summarizes the results of the first edition of the challenge together with the findings of the participants.
Team RUC_AIM3 Technical Report at Activitynet 2020 Task 2: Exploring Sequential Events Detection for Dense Video Captioning
Jun 14, 2020

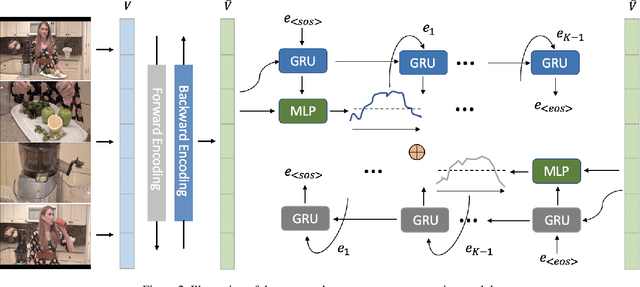
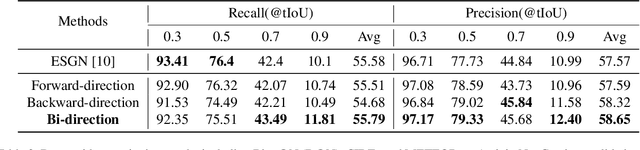
Detecting meaningful events in an untrimmed video is essential for dense video captioning. In this work, we propose a novel and simple model for event sequence generation and explore temporal relationships of the event sequence in the video. The proposed model omits inefficient two-stage proposal generation and directly generates event boundaries conditioned on bi-directional temporal dependency in one pass. Experimental results show that the proposed event sequence generation model can generate more accurate and diverse events within a small number of proposals. For the event captioning, we follow our previous work to employ the intra-event captioning models into our pipeline system. The overall system achieves state-of-the-art performance on the dense-captioning events in video task with 9.894 METEOR score on the challenge testing set.
Fine-grained Video-Text Retrieval with Hierarchical Graph Reasoning
Mar 01, 2020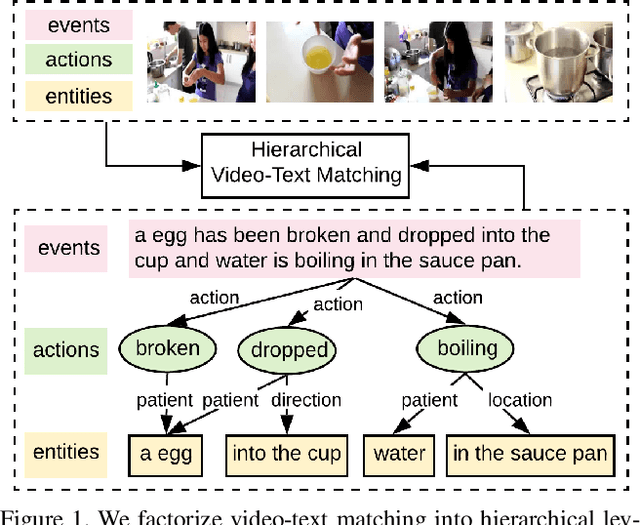
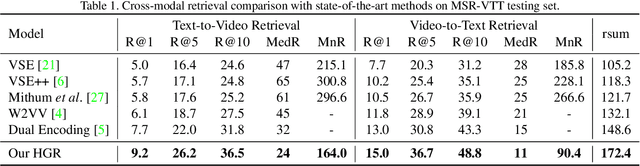
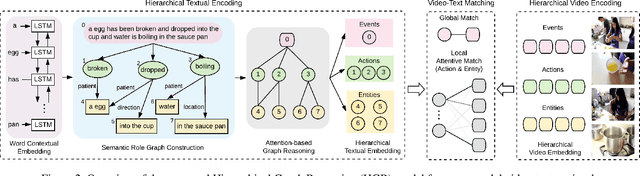

Cross-modal retrieval between videos and texts has attracted growing attentions due to the rapid emergence of videos on the web. The current dominant approach for this problem is to learn a joint embedding space to measure cross-modal similarities. However, simple joint embeddings are insufficient to represent complicated visual and textual details, such as scenes, objects, actions and their compositions. To improve fine-grained video-text retrieval, we propose a Hierarchical Graph Reasoning (HGR) model, which decomposes video-text matching into global-to-local levels. To be specific, the model disentangles texts into hierarchical semantic graph including three levels of events, actions, entities and relationships across levels. Attention-based graph reasoning is utilized to generate hierarchical textual embeddings, which can guide the learning of diverse and hierarchical video representations. The HGR model aggregates matchings from different video-text levels to capture both global and local details. Experimental results on three video-text datasets demonstrate the advantages of our model. Such hierarchical decomposition also enables better generalization across datasets and improves the ability to distinguish fine-grained semantic differences.
Integrating Temporal and Spatial Attentions for VATEX Video Captioning Challenge 2019
Oct 15, 2019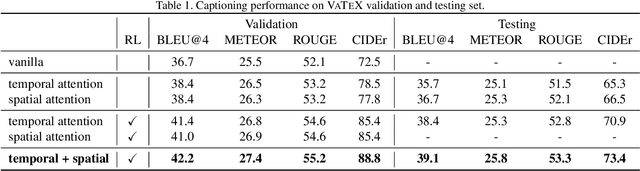
This notebook paper presents our model in the VATEX video captioning challenge. In order to capture multi-level aspects in the video, we propose to integrate both temporal and spatial attentions for video captioning. The temporal attentive module focuses on global action movements while spatial attentive module enables to describe more fine-grained objects. Considering these two types of attentive modules are complementary, we thus fuse them via a late fusion strategy. The proposed model significantly outperforms baselines and achieves 73.4 CIDEr score on the testing set which ranks the second place at the VATEX video captioning challenge leaderboard 2019.