 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Video Labelling: Identifying Faces by Corroborative Evidence
Feb 10, 2021

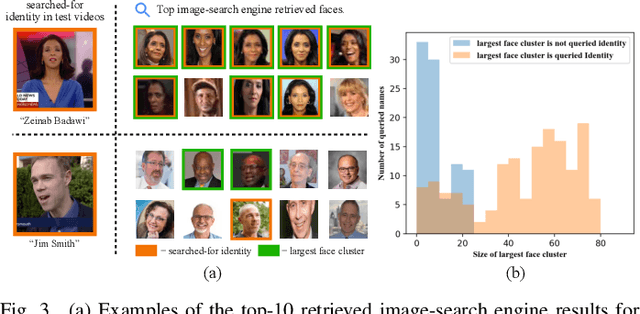

We present a method for automatically labelling all faces in video archives, such as TV broadcasts, by combining multiple evidence sources and multiple modalities (visual and audio). We target the problem of ever-growing online video archives, where an effective, scalable indexing solution cannot require a user to provide manual annotation or supervision. To this end, we make three key contributions: (1) We provide a novel, simple, method for determining if a person is famous or not using image-search engines. In turn this enables a face-identity model to be built reliably and robustly, and used for high precision automatic labelling; (2) We show that even for less-famous people, image-search engines can then be used for corroborative evidence to accurately label faces that are named in the scene or the speech; (3) Finally, we quantitatively demonstrate the benefits of our approach on different video domains and test settings, such as TV shows and news broadcasts. Our method works across three disparate datasets without any explicit domain adaptation, and sets new state-of-the-art results on all the public benchmarks.
VoxSRC 2020: The Second VoxCeleb Speaker Recognition Challenge
Dec 12, 2020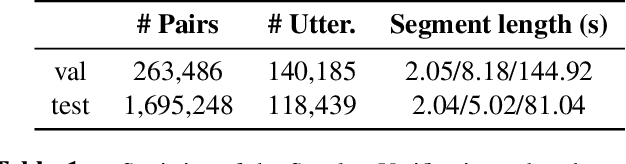
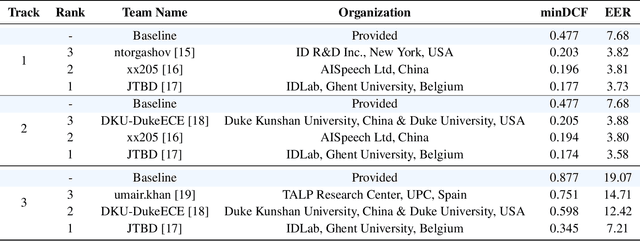

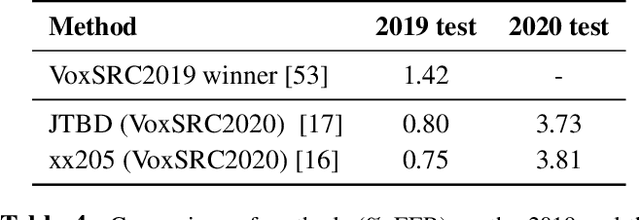
We held the second installment of the VoxCeleb Speaker Recognition Challenge in conjunction with Interspeech 2020. The goal of this challenge was to assess how well current speaker recognition technology is able to diarise and recognize speakers in unconstrained or `in the wild' data. It consisted of: (i) a publicly available speaker recognition and diarisation dataset from YouTube videos together with ground truth annotation and standardised evaluation software; and (ii) a virtual public challenge and workshop held at Interspeech 2020. This paper outlines the challenge, and describes the baselines, methods used, and results. We conclude with a discussion of the progress over the first installment of the challenge.
The End-of-End-to-End: A Video Understanding Pentathlon Challenge
Aug 03, 2020
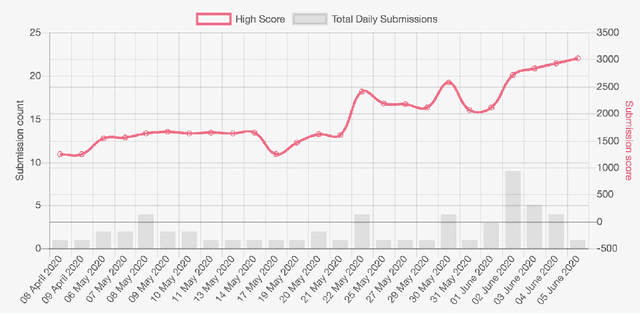
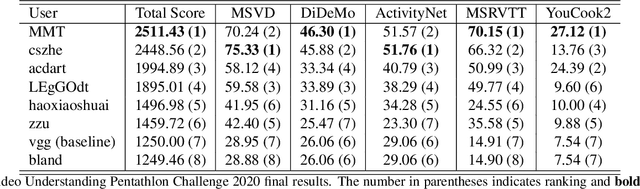
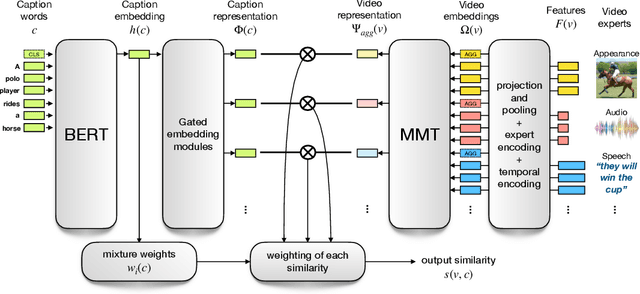
We present a new video understanding pentathlon challenge, an open competition held in conjunction with the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2020. The objective of the challenge was to explore and evaluate new methods for text-to-video retrieval-the task of searching for content within a corpus of videos using natural language queries. This report summarizes the results of the first edition of the challenge together with the findings of the participants.
VoxSRC 2019: The first VoxCeleb Speaker Recognition Challenge
Dec 05, 2019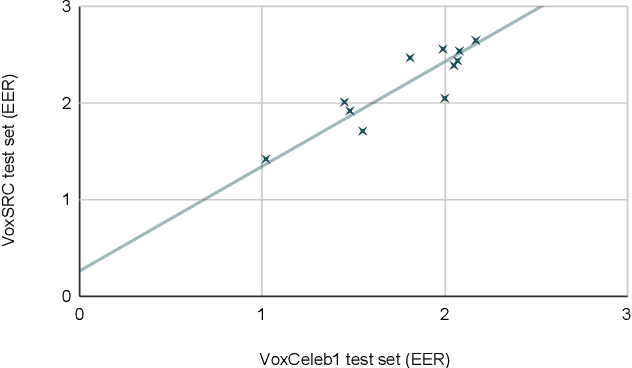

The VoxCeleb Speaker Recognition Challenge 2019 aimed to assess how well current speaker recognition technology is able to identify speakers in unconstrained or `in the wild' data. It consisted of: (i) a publicly available speaker recognition dataset from YouTube videos together with ground truth annotation and standardised evaluation software; and (ii) a public challenge and workshop held at Interspeech 2019 in Graz, Austria. This paper outlines the challenge and provides its baselines, results and discussions.