 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacter-aware audio-visual subtitling in context
Oct 14, 2024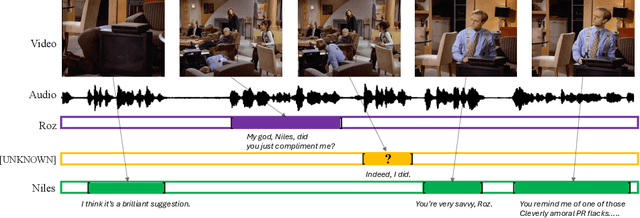


This paper presents an improved framework for character-aware audio-visual subtitling in TV shows. Our approach integrates speech recognition, speaker diarisation, and character recognition, utilising both audio and visual cues. This holistic solution addresses what is said, when it's said, and who is speaking, providing a more comprehensive and accurate character-aware subtitling for TV shows. Our approach brings improvements on two fronts: first, we show that audio-visual synchronisation can be used to pick out the talking face amongst others present in a video clip, and assign an identity to the corresponding speech segment. This audio-visual approach improves recognition accuracy and yield over current methods. Second, we show that the speaker of short segments can be determined by using the temporal context of the dialogue within a scene. We propose an approach using local voice embeddings of the audio, and large language model reasoning on the text transcription. This overcomes a limitation of existing methods that they are unable to accurately assign speakers to short temporal segments. We validate the method on a dataset with 12 TV shows, demonstrating superior performance in speaker diarisation and character recognition accuracy compared to existing approaches. Project page : https://www.robots.ox.ac.uk/~vgg/research/llr-context/
The VoxCeleb Speaker Recognition Challenge: A Retrospective
Aug 27, 2024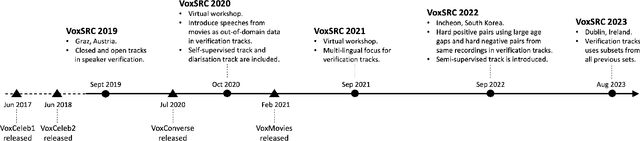
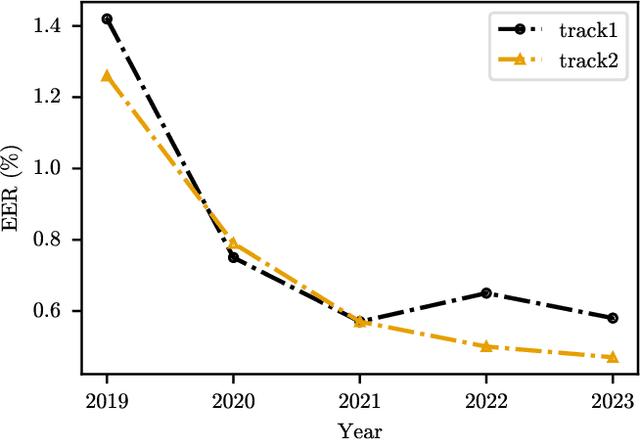
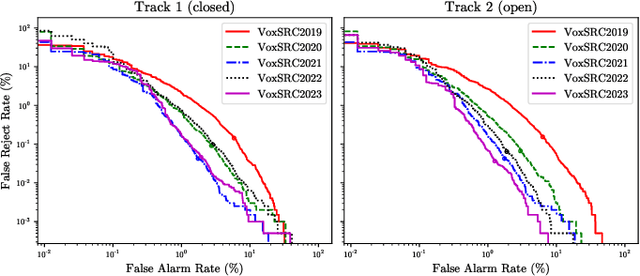
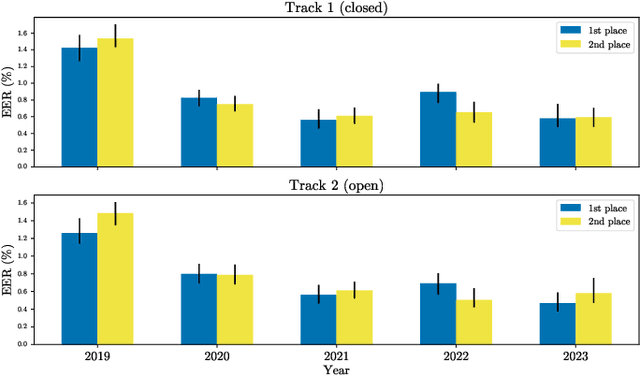
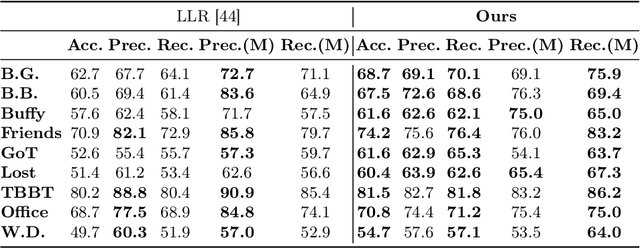
The VoxCeleb Speaker Recognition Challenges (VoxSRC) were a series of challenges and workshops that ran annually from 2019 to 2023. The challenges primarily evaluated the tasks of speaker recognition and diarisation under various settings including: closed and open training data; as well as supervised, self-supervised, and semi-supervised training for domain adaptation. The challenges also provided publicly available training and evaluation datasets for each task and setting, with new test sets released each year. In this paper, we provide a review of these challenges that covers: what they explored; the methods developed by the challenge participants and how these evolved; and also the current state of the field for speaker verification and diarisation. We chart the progress in performance over the five installments of the challenge on a common evaluation dataset and provide a detailed analysis of how each year's special focus affected participants' performance. This paper is aimed both at researchers who want an overview of the speaker recognition and diarisation field, and also at challenge organisers who want to benefit from the successes and avoid the mistakes of the VoxSRC challenges. We end with a discussion of the current strengths of the field and open challenges. Project page : https://mm.kaist.ac.kr/datasets/voxceleb/voxsrc/workshop.html
TIM: A Time Interval Machine for Audio-Visual Action Recognition
Apr 09, 2024



Diverse actions give rise to rich audio-visual signals in long videos. Recent works showcase that the two modalities of audio and video exhibit different temporal extents of events and distinct labels. We address the interplay between the two modalities in long videos by explicitly modelling the temporal extents of audio and visual events. We propose the Time Interval Machine (TIM) where a modality-specific time interval poses as a query to a transformer encoder that ingests a long video input. The encoder then attends to the specified interval, as well as the surrounding context in both modalities, in order to recognise the ongoing action. We test TIM on three long audio-visual video datasets: EPIC-KITCHENS, Perception Test, and AVE, reporting state-of-the-art (SOTA) for recognition. On EPIC-KITCHENS, we beat previous SOTA that utilises LLMs and significantly larger pre-training by 2.9% top-1 action recognition accuracy. Additionally, we show that TIM can be adapted for action detection, using dense multi-scale interval queries, outperforming SOTA on EPIC-KITCHENS-100 for most metrics, and showing strong performance on the Perception Test. Our ablations show the critical role of integrating the two modalities and modelling their time intervals in achieving this performance. Code and models at: https://github.com/JacobChalk/TIM
Look, Listen and Recognise: Character-Aware Audio-Visual Subtitling
Jan 22, 2024



The goal of this paper is automatic character-aware subtitle generation. Given a video and a minimal amount of metadata, we propose an audio-visual method that generates a full transcript of the dialogue, with precise speech timestamps, and the character speaking identified. The key idea is to first use audio-visual cues to select a set of high-precision audio exemplars for each character, and then use these exemplars to classify all speech segments by speaker identity. Notably, the method does not require face detection or tracking. We evaluate the method over a variety of TV sitcoms, including Seinfeld, Fraiser and Scrubs. We envision this system being useful for the automatic generation of subtitles to improve the accessibility of the vast amount of videos available on modern streaming services. Project page : \url{https://www.robots.ox.ac.uk/~vgg/research/look-listen-recognise/}
OxfordVGG Submission to the EGO4D AV Transcription Challenge
Jul 18, 2023This report presents the technical details of our submission on the EGO4D Audio-Visual (AV) Automatic Speech Recognition Challenge 2023 from the OxfordVGG team. We present WhisperX, a system for efficient speech transcription of long-form audio with word-level time alignment, along with two text normalisers which are publicly available. Our final submission obtained 56.0% of the Word Error Rate (WER) on the challenge test set, ranked 1st on the leaderboard. All baseline codes and models are available on https://github.com/m-bain/whisperX.
VoxSRC 2022: The Fourth VoxCeleb Speaker Recognition Challenge
Mar 06, 2023This paper summarises the findings from the VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC-22), which was held in conjunction with INTERSPEECH 2022. The goal of this challenge was to evaluate how well state-of-the-art speaker recognition systems can diarise and recognise speakers from speech obtained "in the wild". The challenge consisted of: (i) the provision of publicly available speaker recognition and diarisation data from YouTube videos together with ground truth annotation and standardised evaluation software; and (ii) a public challenge and hybrid workshop held at INTERSPEECH 2022. We describe the four tracks of our challenge along with the baselines, methods, and results. We conclude with a discussion on the new domain-transfer focus of VoxSRC-22, and on the progression of the challenge from the previous three editions.
WhisperX: Time-Accurate Speech Transcription of Long-Form Audio
Mar 01, 2023



Large-scale, weakly-supervised speech recognition models, such as Whisper, have demonstrated impressive results on speech recognition across domains and languages. However, their application to long audio transcription via buffered or sliding window approaches is prone to drifting, hallucination & repetition; and prohibits batched transcription due to their sequential nature. Further, timestamps corresponding each utterance are prone to inaccuracies and word-level timestamps are not available out-of-the-box. To overcome these challenges, we present WhisperX, a time-accurate speech recognition system with word-level timestamps utilising voice activity detection and forced phoneme alignment. In doing so, we demonstrate state-of-the-art performance on long-form transcription and word segmentation benchmarks. Additionally, we show that pre-segmenting audio with our proposed VAD Cut & Merge strategy improves transcription quality and enables a twelve-fold transcription speedup via batched inference.
Epic-Sounds: A Large-scale Dataset of Actions That Sound
Feb 01, 2023



We introduce EPIC-SOUNDS, a large-scale dataset of audio annotations capturing temporal extents and class labels within the audio stream of the egocentric videos. We propose an annotation pipeline where annotators temporally label distinguishable audio segments and describe the action that could have caused this sound. We identify actions that can be discriminated purely from audio, through grouping these free-form descriptions of audio into classes. For actions that involve objects colliding, we collect human annotations of the materials of these objects (e.g. a glass object being placed on a wooden surface), which we verify from visual labels, discarding ambiguities. Overall, EPIC-SOUNDS includes 78.4k categorised segments of audible events and actions, distributed across 44 classes as well as 39.2k non-categorised segments. We train and evaluate two state-of-the-art audio recognition models on our dataset, highlighting the importance of audio-only labels and the limitations of current models to recognise actions that sound.
In search of strong embedding extractors for speaker diarisation
Oct 26, 2022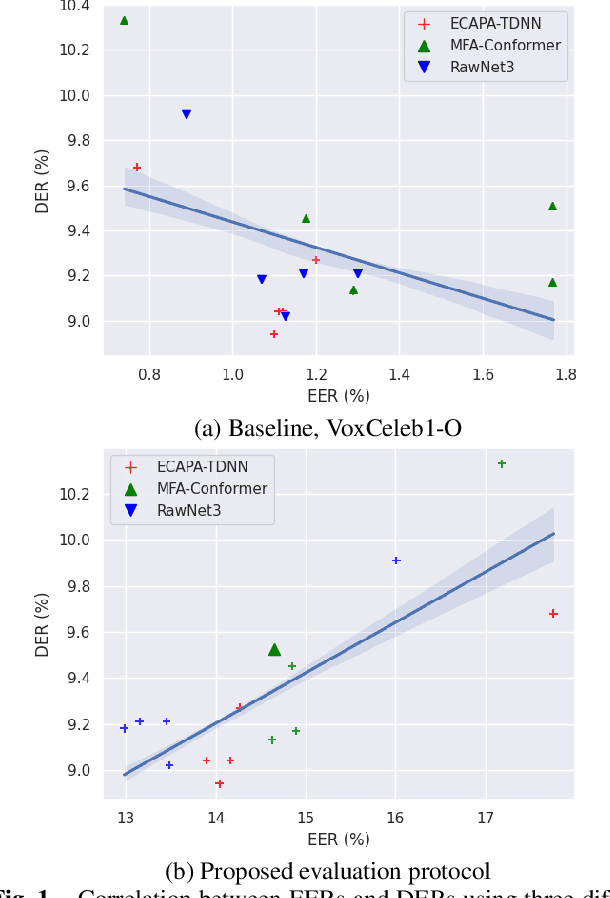
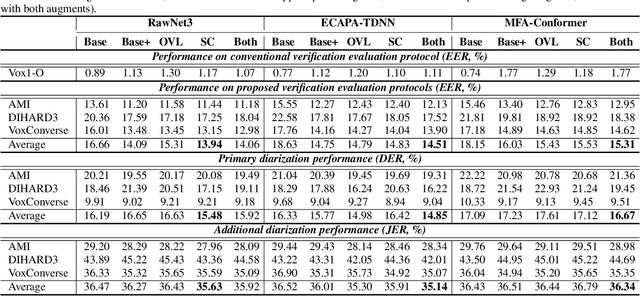
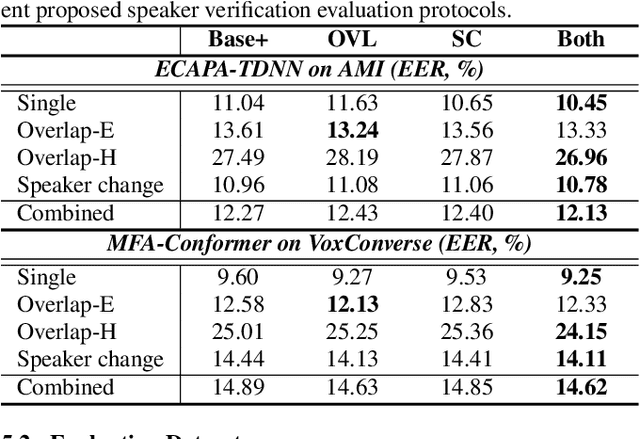
Speaker embedding extractors (EEs), which map input audio to a speaker discriminant latent space, are of paramount importance in speaker diarisation. However, there are several challenges when adopting EEs for diarisation, from which we tackle two key problems. First, the evaluation is not straightforward because the features required for better performance differ between speaker verification and diarisation. We show that better performance on widely adopted speaker verification evaluation protocols does not lead to better diarisation performance. Second, embedding extractors have not seen utterances in which multiple speakers exist. These inputs are inevitably present in speaker diarisation because of overlapped speech and speaker changes; they degrade the performance. To mitigate the first problem, we generate speaker verification evaluation protocols that mimic the diarisation scenario better. We propose two data augmentation techniques to alleviate the second problem, making embedding extractors aware of overlapped speech or speaker change input. One technique generates overlapped speech segments, and the other generates segments where two speakers utter sequentially. Extensive experimental results using three state-of-the-art speaker embedding extractors demonstrate that both proposed approaches are effective.
VoxSRC 2021: The Third VoxCeleb Speaker Recognition Challenge
Jan 12, 2022
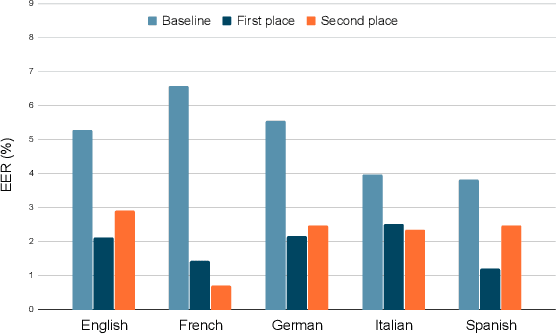
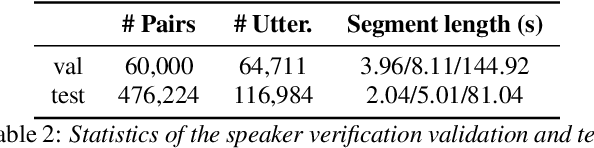
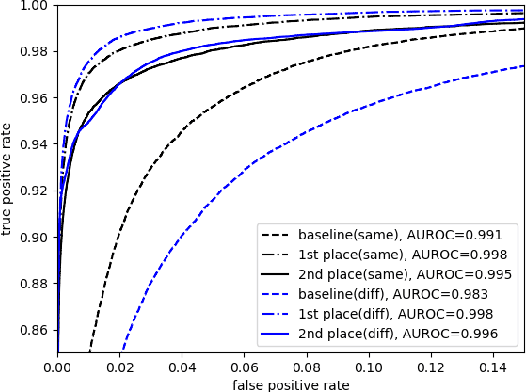
The third instalment of the VoxCeleb Speaker Recognition Challenge was held in conjunction with Interspeech 2021. The aim of this challenge was to assess how well current speaker recognition technology is able to diarise and recognise speakers in unconstrained or `in the wild' data. The challenge consisted of: (i) the provision of publicly available speaker recognition and diarisation data from YouTube videos together with ground truth annotation and standardised evaluation software; and (ii) a virtual public challenge and workshop held at Interspeech 2021. This paper outlines the challenge, and describes the baselines, methods and results. We conclude with a discussion on the new multi-lingual focus of VoxSRC 2021, and on the progression of the challenge since the previous two editions.