 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook, Listen and Recognise: Character-Aware Audio-Visual Subtitling
Jan 22, 2024



The goal of this paper is automatic character-aware subtitle generation. Given a video and a minimal amount of metadata, we propose an audio-visual method that generates a full transcript of the dialogue, with precise speech timestamps, and the character speaking identified. The key idea is to first use audio-visual cues to select a set of high-precision audio exemplars for each character, and then use these exemplars to classify all speech segments by speaker identity. Notably, the method does not require face detection or tracking. We evaluate the method over a variety of TV sitcoms, including Seinfeld, Fraiser and Scrubs. We envision this system being useful for the automatic generation of subtitles to improve the accessibility of the vast amount of videos available on modern streaming services. Project page : \url{https://www.robots.ox.ac.uk/~vgg/research/look-listen-recognise/}
Text-Conditioned Resampler For Long Form Video Understanding
Dec 19, 2023



Videos are highly redundant data source and it is often enough to identify a few key moments to solve any given task. In this paper, we present a text-conditioned video resampler (TCR) module that uses a pre-trained and frozen visual encoder and large language model (LLM) to process long video sequences for a task. TCR localises relevant visual features from the video given a text condition and provides them to a LLM to generate a text response. Due to its lightweight design and use of cross-attention, TCR can process more than 100 frames at a time allowing the model to use much longer chunks of video than earlier works. We make the following contributions: (i) we design a transformer-based sampling architecture that can process long videos conditioned on a task, together with a training method that enables it to bridge pre-trained visual and language models; (ii) we empirically validate its efficacy on a wide variety of evaluation tasks, and set a new state-of-the-art on NextQA, EgoSchema, and the EGO4D-LTA challenge; and (iii) we determine tasks which require longer video contexts and that can thus be used effectively for further evaluation of long-range video models.
End-to-end Tracking with a Multi-query Transformer
Oct 26, 2022



Multiple-object tracking (MOT) is a challenging task that requires simultaneous reasoning about location, appearance, and identity of the objects in the scene over time. Our aim in this paper is to move beyond tracking-by-detection approaches, that perform well on datasets where the object classes are known, to class-agnostic tracking that performs well also for unknown object classes.To this end, we make the following three contributions: first, we introduce {\em semantic detector queries} that enable an object to be localized by specifying its approximate position, or its appearance, or both; second, we use these queries within an auto-regressive framework for tracking, and propose a multi-query tracking transformer (\textit{MQT}) model for simultaneous tracking and appearance-based re-identification (reID) based on the transformer architecture with deformable attention. This formulation allows the tracker to operate in a class-agnostic manner, and the model can be trained end-to-end; finally, we demonstrate that \textit{MQT} performs competitively on standard MOT benchmarks, outperforms all baselines on generalised-MOT, and generalises well to a much harder tracking problems such as tracking any object on the TAO dataset.
Generalized Many-Way Few-Shot Video Classification
Jul 09, 2020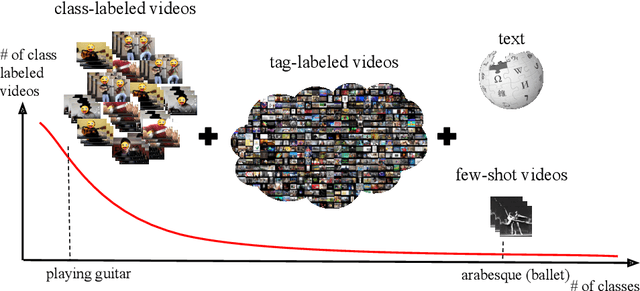
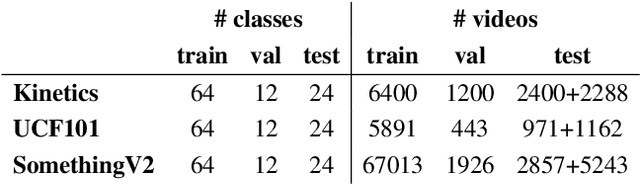
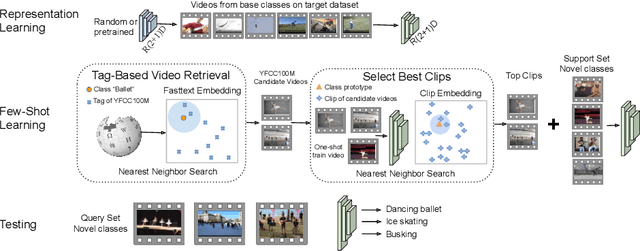
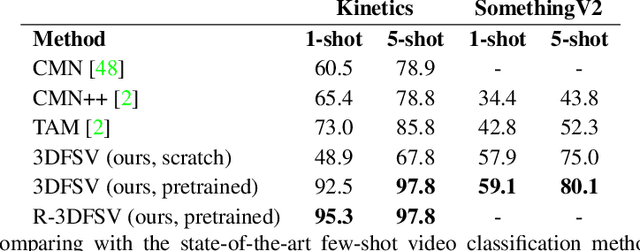
Few-shot learning methods operate in low data regimes. The aim is to learn with few training examples per class. Although significant progress has been made in few-shot image classification, few-shot video recognition is relatively unexplored and methods based on 2D CNNs are unable to learn temporal information. In this work we thus develop a simple 3D CNN baseline, surpassing existing methods by a large margin. To circumvent the need of labeled examples, we propose to leverage weakly-labeled videos from a large dataset using tag retrieval followed by selecting the best clips with visual similarities, yielding further improvement. Our results saturate current 5-way benchmarks for few-shot video classification and therefore we propose a new challenging benchmark involving more classes and a mixture of classes with varying supervision.
Video Understanding as Machine Translation
Jun 12, 2020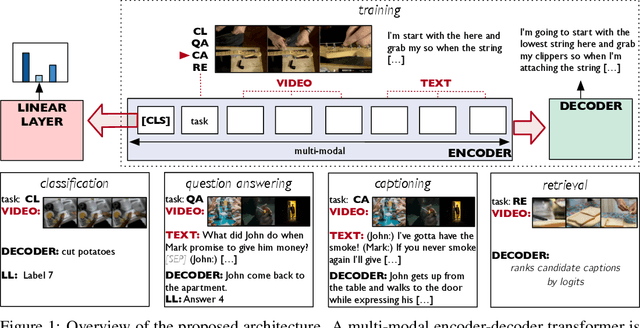
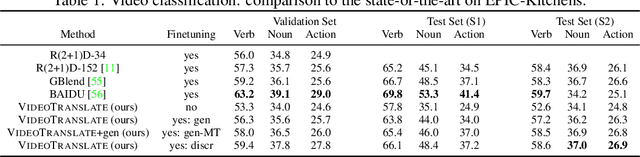
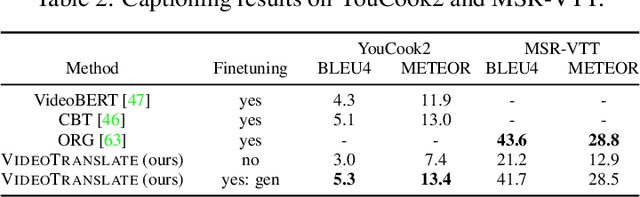

With the advent of large-scale multimodal video datasets, especially sequences with audio or transcribed speech, there has been a growing interest in self-supervised learning of video representations. Most prior work formulates the objective as a contrastive metric learning problem between the modalities. To enable effective learning, however, these strategies require a careful selection of positive and negative samples often combined with hand-designed curriculum policies. In this work we remove the need for negative sampling by taking a generative modeling approach that poses the objective as a translation problem between modalities. Such a formulation allows us to tackle a wide variety of downstream video understanding tasks by means of a single unified framework, without the need for large batches of negative samples common in contrastive metric learning. We experiment with the large-scale HowTo100M dataset for training, and report performance gains over the state-of-the-art on several downstream tasks including video classification (EPIC-Kitchens), question answering (TVQA), captioning (TVC, YouCook2, and MSR-VTT), and text-based clip retrieval (YouCook2 and MSR-VTT).
SCSampler: Sampling Salient Clips from Video for Efficient Action Recognition
Apr 08, 2019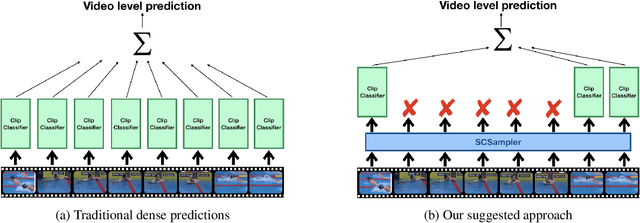


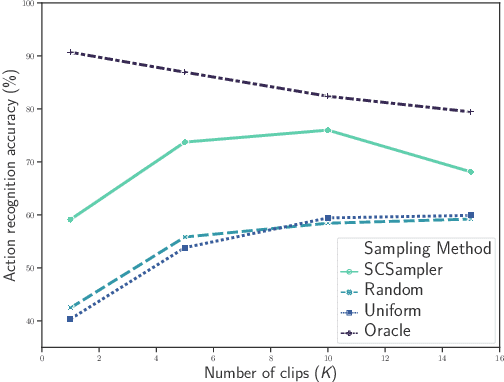
While many action recognition datasets consist of collections of brief, trimmed videos each containing a relevant action, videos in the real-world (e.g., on YouTube) exhibit very different properties: they are often several minutes long, where brief relevant clips are often interleaved with segments of extended duration containing little change. Applying densely an action recognition system to every temporal clip within such videos is prohibitively expensive. Furthermore, as we show in our experiments, this results in suboptimal recognition accuracy as informative predictions from relevant clips are outnumbered by meaningless classification outputs over long uninformative sections of the video. In this paper we introduce a lightweight `clip-sampling' model that can efficiently identify the most salient temporal clips within a long video. We demonstrate that the computational cost of action recognition on untrimmed videos can be dramatically reduced by invoking recognition only on these most salient clips. Furthermore, we show that this yields significant gains in recognition accuracy compared to analysis of all clips or randomly/uniformly selected clips. On Sports1M, our clip sampling scheme elevates the accuracy of an already state-of-the-art action classifier by 7% and reduces by more than 15 times its computational cost.
Co-Training of Audio and Video Representations from Self-Supervised Temporal Synchronization
Jun 30, 2018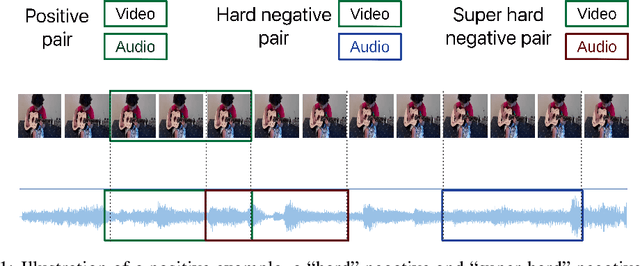

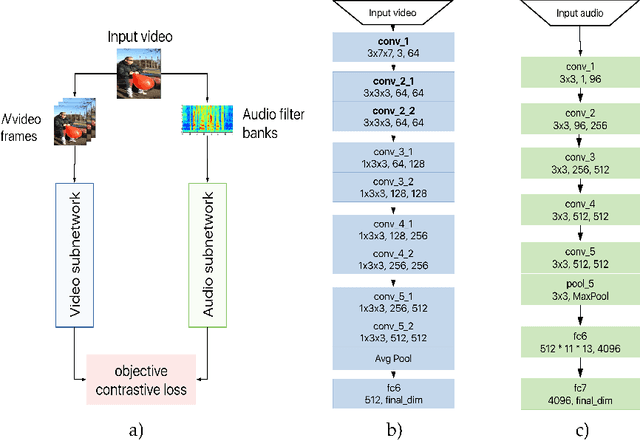
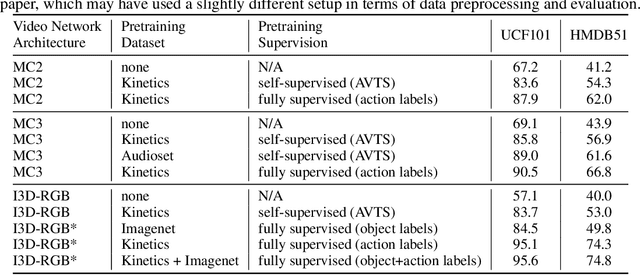
There is a natural correlation between the visual and auditive elements of a video. In this work we leverage this connection to learn general and effective features for both audio and video analysis from self-supervised temporal synchronization. We demonstrate that a calibrated curriculum learning scheme, a careful choice of negative examples, and the use of a contrastive loss are critical ingredients to obtain powerful multi-sensory representations from models optimized to discern temporal synchronization of audio-video pairs. Without further finetuning, the resulting audio features achieve performance superior or comparable to the state-of-the-art on established audio classification benchmarks (DCASE2014 and ESC-50). At the same time, our visual subnet provides a very effective initialization to improve the accuracy of video-based action recognition models: compared to learning from scratch, our self-supervised pretraining yields a remarkable gain of +16.7% in action recognition accuracy on UCF101 and a boost of +13.0% on HMDB51.
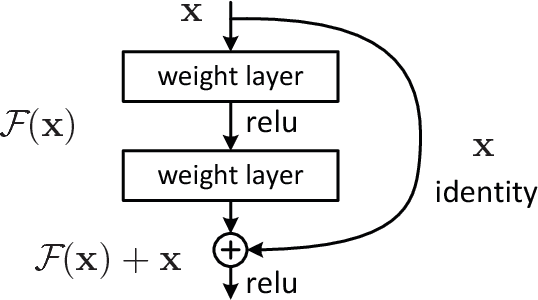
Deep-Learning for Classification of Colorectal Polyps on Whole-Slide Images
Apr 12, 2017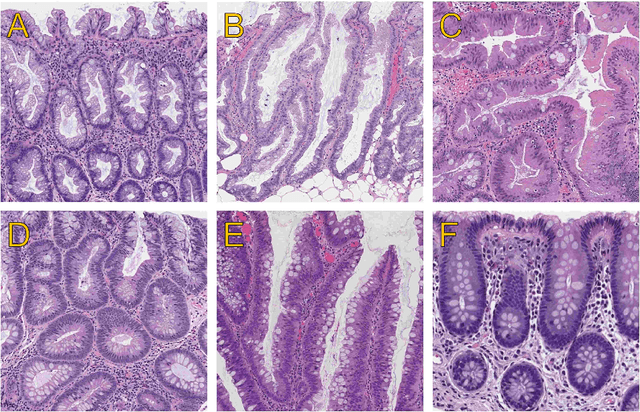
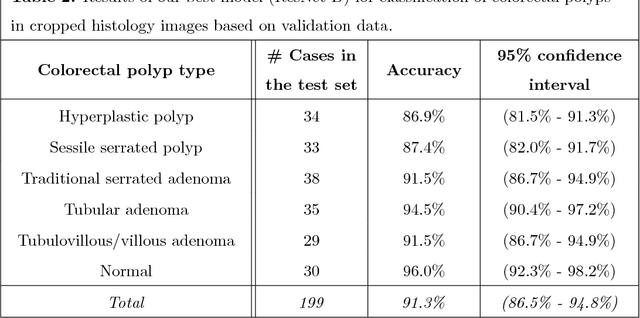
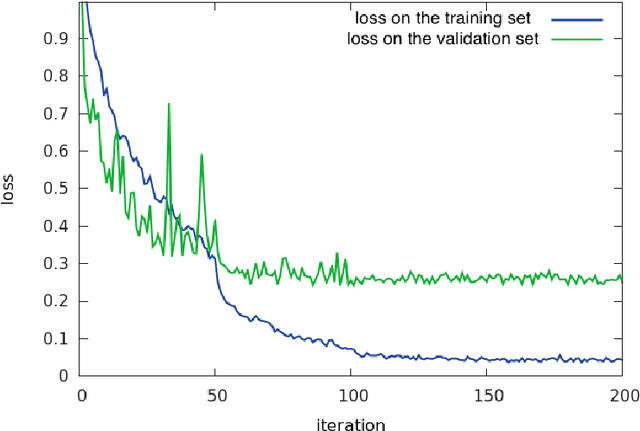
Histopathological characterization of colorectal polyps is an important principle for determining the risk of colorectal cancer and future rates of surveillance for patients. This characterization is time-intensive, requires years of specialized training, and suffers from significant inter-observer and intra-observer variability. In this work, we built an automatic image-understanding method that can accurately classify different types of colorectal polyps in whole-slide histology images to help pathologists with histopathological characterization and diagnosis of colorectal polyps. The proposed image-understanding method is based on deep-learning techniques, which rely on numerous levels of abstraction for data representation and have shown state-of-the-art results for various image analysis tasks. Our image-understanding method covers all five polyp types (hyperplastic polyp, sessile serrated polyp, traditional serrated adenoma, tubular adenoma, and tubulovillous/villous adenoma) that are included in the US multi-society task force guidelines for colorectal cancer risk assessment and surveillance, and encompasses the most common occurrences of colorectal polyps. Our evaluation on 239 independent test samples shows our proposed method can identify the types of colorectal polyps in whole-slide images with a high efficacy (accuracy: 93.0%, precision: 89.7%, recall: 88.3%, F1 score: 88.8%). The presented method in this paper can reduce the cognitive burden on pathologists and improve their accuracy and efficiency in histopathological characterization of colorectal polyps, and in subsequent risk assessment and follow-up recommendations.