 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Pruned Key-Value Attention: Learning When to Write by Predicting Future Utility
May 13, 2026Under modern test-time compute and agentic paradigms, language models process ever-longer sequences. Efficient text generation with transformer architectures is increasingly constrained by the Key-Value cache memory footprint and bandwidth. To address this limitation, we introduce Self-Pruned Key-Value Attention (SP-KV), a mechanism designed to predict future KV utility in order to reduce the size of the long-term KV cache. This strategy operates at a fine granularity: a lightweight utility predictor scores each key-value pair, and while recent KVs are always available via a local window, older pairs are written in the cache and used in global attention only if their predicted utility surpasses a given threshold. The LLM and the utility predictor are trained jointly end-to-end exclusively through next-token prediction loss, and are adapted from pretrained LLM checkpoints. Rather than enforcing a fixed compression ratio, SP-KV performs dynamic sparsification: the mechanism adapts to the input and typically reduces the KV cache size by a factor of $3$ to $10\times$, longer sequences often being more compressible. This leads to vast improvements in memory usage and decoding speed, with little to no degradation of validation loss nor performance on a broad set of downstream tasks. Beyond serving as an effective KV-cache reduction mechanism, our method reveals structured layer- and head-specific sparsity patterns that we can use to guide the design of hybrid local-global attention architectures.
Stochastic activations
Sep 26, 2025We introduce stochastic activations. This novel strategy randomly selects between several non-linear functions in the feed-forward layer of a large language model. In particular, we choose between SILU or RELU depending on a Bernoulli draw. This strategy circumvents the optimization problem associated with RELU, namely, the constant shape for negative inputs that prevents the gradient flow. We leverage this strategy in two ways: (1) We use stochastic activations during pre-training and fine-tune the model with RELU, which is used at inference time to provide sparse latent vectors. This reduces the inference FLOPs and translates into a significant speedup in the CPU. Interestingly, this leads to much better results than training from scratch with the RELU activation function. (2) We evaluate stochastic activations for generation. This strategy performs reasonably well: it is only slightly inferior to the best deterministic non-linearity, namely SILU combined with temperature scaling. This offers an alternative to existing strategies by providing a controlled way to increase the diversity of the generated text.
Machine learning and high dimensional vector search
Feb 24, 2025Machine learning and vector search are two research topics that developed in parallel in nearby communities. However, unlike many other fields related to big data, machine learning has not significantly impacted vector search. In this opinion paper we attempt to explain this oddity. Along the way, we wander over the numerous bridges between the two fields.
Inference-time sparse attention with asymmetric indexing
Feb 12, 2025



Self-attention in transformer models is an incremental associative memory that maps key vectors to value vectors. One way to speed up self-attention is to employ GPU-compliant vector search algorithms, yet the standard partitioning methods yield poor results in this context, because (1) keys and queries follow different distributions and (2) the effect of RoPE positional encoding. In this paper, we introduce SAAP (Self-Attention with Asymmetric Partitions), which overcomes these problems. It is an asymmetrical indexing technique that employs distinct partitions for keys and queries, thereby approximating self-attention with a data-adaptive sparsity pattern. It works on pretrained language models without finetuning, as it only requires to train (offline) a small query classifier. On a long context Llama 3.1-8b model, with sequences ranging from 100k to 500k tokens, our method typically reduces by a factor 20 the fraction of memory that needs to be looked-up, which translates to a time saving of 60\% when compared to FlashAttention-v2.
Qinco2: Vector Compression and Search with Improved Implicit Neural Codebooks
Jan 06, 2025



Vector quantization is a fundamental technique for compression and large-scale nearest neighbor search. For high-accuracy operating points, multi-codebook quantization associates data vectors with one element from each of multiple codebooks. An example is residual quantization (RQ), which iteratively quantizes the residual error of previous steps. Dependencies between the different parts of the code are, however, ignored in RQ, which leads to suboptimal rate-distortion performance. QINCo recently addressed this inefficiency by using a neural network to determine the quantization codebook in RQ based on the vector reconstruction from previous steps. In this paper we introduce QINCo2 which extends and improves QINCo with (i) improved vector encoding using codeword pre-selection and beam-search, (ii) a fast approximate decoder leveraging codeword pairs to establish accurate short-lists for search, and (iii) an optimized training procedure and network architecture. We conduct experiments on four datasets to evaluate QINCo2 for vector compression and billion-scale nearest neighbor search. We obtain outstanding results in both settings, improving the state-of-the-art reconstruction MSE by 34% for 16-byte vector compression on BigANN, and search accuracy by 24% with 8-byte encodings on Deep1M.
Watermark Anything with Localized Messages
Nov 11, 2024



Image watermarking methods are not tailored to handle small watermarked areas. This restricts applications in real-world scenarios where parts of the image may come from different sources or have been edited. We introduce a deep-learning model for localized image watermarking, dubbed the Watermark Anything Model (WAM). The WAM embedder imperceptibly modifies the input image, while the extractor segments the received image into watermarked and non-watermarked areas and recovers one or several hidden messages from the areas found to be watermarked. The models are jointly trained at low resolution and without perceptual constraints, then post-trained for imperceptibility and multiple watermarks. Experiments show that WAM is competitive with state-of-the art methods in terms of imperceptibility and robustness, especially against inpainting and splicing, even on high-resolution images. Moreover, it offers new capabilities: WAM can locate watermarked areas in spliced images and extract distinct 32-bit messages with less than 1 bit error from multiple small regions - no larger than 10% of the image surface - even for small $256\times 256$ images.
MagicPIG: LSH Sampling for Efficient LLM Generation
Oct 21, 2024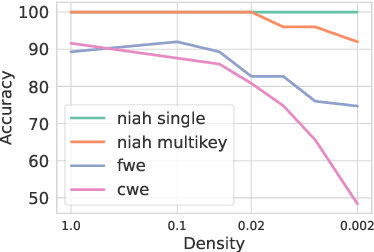
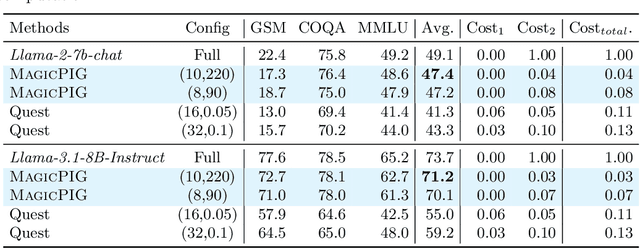
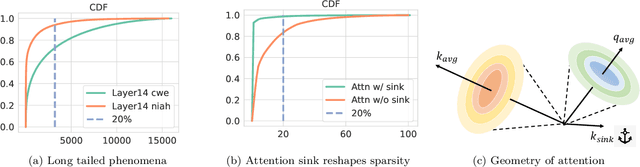
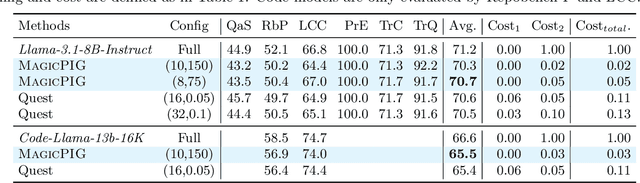
Large language models (LLMs) with long context windows have gained significant attention. However, the KV cache, stored to avoid re-computation, becomes a bottleneck. Various dynamic sparse or TopK-based attention approximation methods have been proposed to leverage the common insight that attention is sparse. In this paper, we first show that TopK attention itself suffers from quality degradation in certain downstream tasks because attention is not always as sparse as expected. Rather than selecting the keys and values with the highest attention scores, sampling with theoretical guarantees can provide a better estimation for attention output. To make the sampling-based approximation practical in LLM generation, we propose MagicPIG, a heterogeneous system based on Locality Sensitive Hashing (LSH). MagicPIG significantly reduces the workload of attention computation while preserving high accuracy for diverse tasks. MagicPIG stores the LSH hash tables and runs the attention computation on the CPU, which allows it to serve longer contexts and larger batch sizes with high approximation accuracy. MagicPIG can improve decoding throughput by $1.9\sim3.9\times$ across various GPU hardware and achieve 110ms decoding latency on a single RTX 4090 for Llama-3.1-8B-Instruct model with a context of 96k tokens. The code is available at \url{https://github.com/Infini-AI-Lab/MagicPIG}.
Results of the Big ANN: NeurIPS'23 competition
Sep 25, 2024


The 2023 Big ANN Challenge, held at NeurIPS 2023, focused on advancing the state-of-the-art in indexing data structures and search algorithms for practical variants of Approximate Nearest Neighbor (ANN) search that reflect the growing complexity and diversity of workloads. Unlike prior challenges that emphasized scaling up classical ANN search ~\cite{DBLP:conf/nips/SimhadriWADBBCH21}, this competition addressed filtered search, out-of-distribution data, sparse and streaming variants of ANNS. Participants developed and submitted innovative solutions that were evaluated on new standard datasets with constrained computational resources. The results showcased significant improvements in search accuracy and efficiency over industry-standard baselines, with notable contributions from both academic and industrial teams. This paper summarizes the competition tracks, datasets, evaluation metrics, and the innovative approaches of the top-performing submissions, providing insights into the current advancements and future directions in the field of approximate nearest neighbor search.
Vector search with small radiuses
Mar 16, 2024
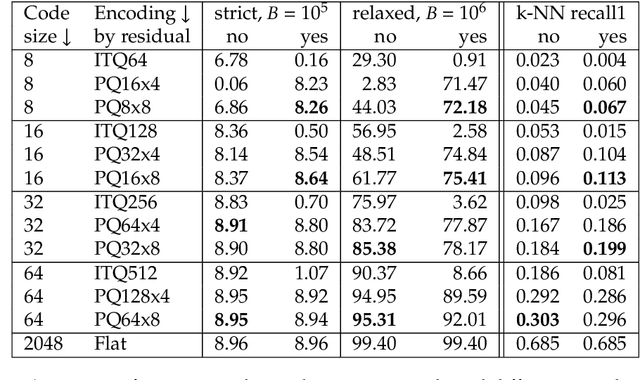
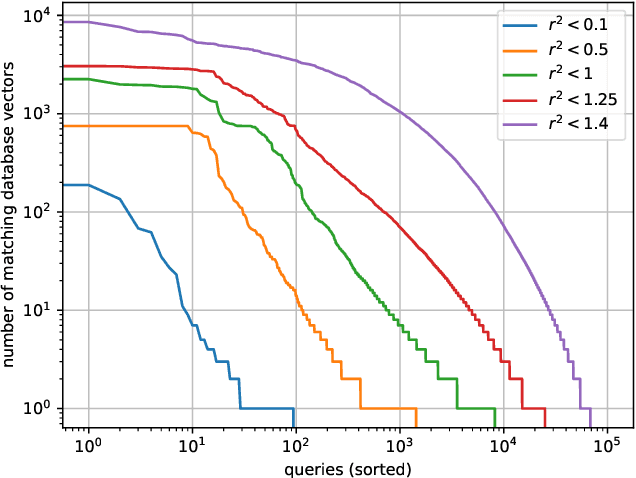
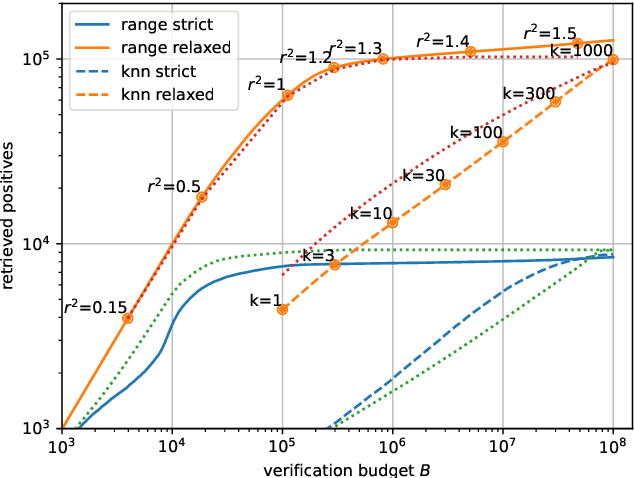
In recent years, the dominant accuracy metric for vector search is the recall of a result list of fixed size (top-k retrieval), considering as ground truth the exact vector retrieval results. Although convenient to compute, this metric is distantly related to the end-to-end accuracy of a full system that integrates vector search. In this paper we focus on the common case where a hard decision needs to be taken depending on the vector retrieval results, for example, deciding whether a query image matches a database image or not. We solve this as a range search task, where all vectors within a certain radius from the query are returned. We show that the value of a range search result can be modeled rigorously based on the query-to-vector distance. This yields a metric for range search, RSM, that is both principled and easy to compute without running an end-to-end evaluation. We apply this metric to the case of image retrieval. We show that indexing methods that are adapted for top-k retrieval do not necessarily maximize the RSM. In particular, for inverted file based indexes, we show that visiting a limited set of clusters and encoding vectors compactly yields near optimal results.
Watermarking Makes Language Models Radioactive
Feb 22, 2024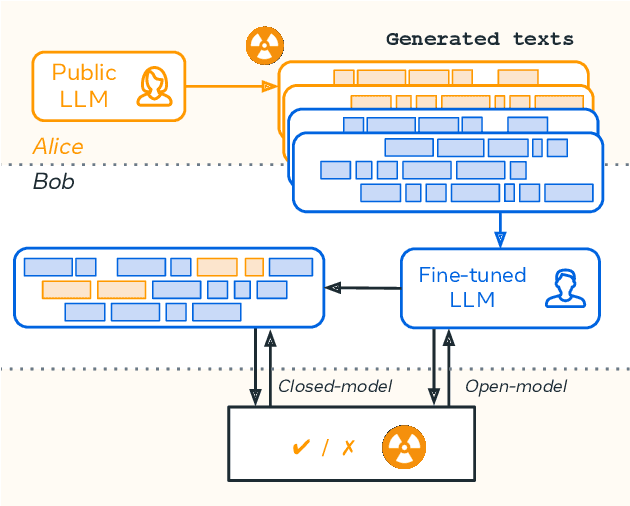
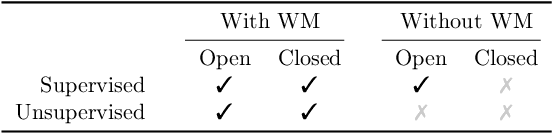
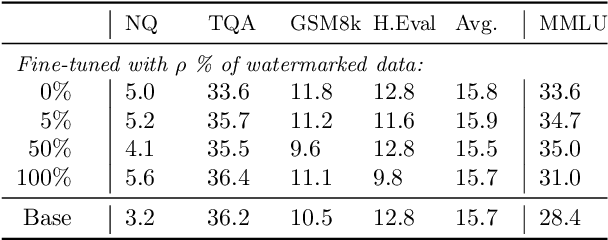
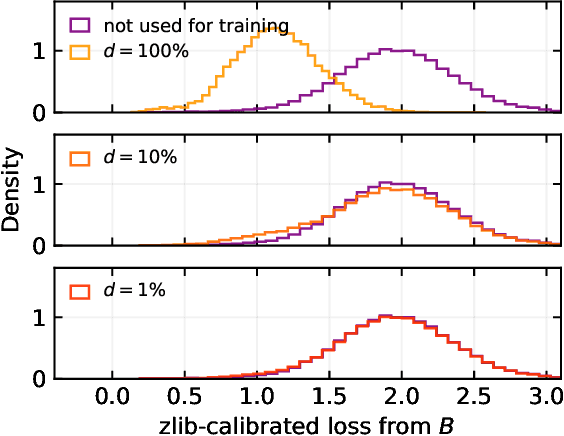
This paper investigates the radioactivity of LLM-generated texts, i.e. whether it is possible to detect that such input was used as training data. Conventional methods like membership inference can carry out this detection with some level of accuracy. We show that watermarked training data leaves traces easier to detect and much more reliable than membership inference. We link the contamination level to the watermark robustness, its proportion in the training set, and the fine-tuning process. We notably demonstrate that training on watermarked synthetic instructions can be detected with high confidence (p-value < 1e-5) even when as little as 5% of training text is watermarked. Thus, LLM watermarking, originally designed for detecting machine-generated text, gives the ability to easily identify if the outputs of a watermarked LLM were used to fine-tune another LLM.