 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic activations
Sep 26, 2025We introduce stochastic activations. This novel strategy randomly selects between several non-linear functions in the feed-forward layer of a large language model. In particular, we choose between SILU or RELU depending on a Bernoulli draw. This strategy circumvents the optimization problem associated with RELU, namely, the constant shape for negative inputs that prevents the gradient flow. We leverage this strategy in two ways: (1) We use stochastic activations during pre-training and fine-tune the model with RELU, which is used at inference time to provide sparse latent vectors. This reduces the inference FLOPs and translates into a significant speedup in the CPU. Interestingly, this leads to much better results than training from scratch with the RELU activation function. (2) We evaluate stochastic activations for generation. This strategy performs reasonably well: it is only slightly inferior to the best deterministic non-linearity, namely SILU combined with temperature scaling. This offers an alternative to existing strategies by providing a controlled way to increase the diversity of the generated text.
Inference-time sparse attention with asymmetric indexing
Feb 12, 2025



Self-attention in transformer models is an incremental associative memory that maps key vectors to value vectors. One way to speed up self-attention is to employ GPU-compliant vector search algorithms, yet the standard partitioning methods yield poor results in this context, because (1) keys and queries follow different distributions and (2) the effect of RoPE positional encoding. In this paper, we introduce SAAP (Self-Attention with Asymmetric Partitions), which overcomes these problems. It is an asymmetrical indexing technique that employs distinct partitions for keys and queries, thereby approximating self-attention with a data-adaptive sparsity pattern. It works on pretrained language models without finetuning, as it only requires to train (offline) a small query classifier. On a long context Llama 3.1-8b model, with sequences ranging from 100k to 500k tokens, our method typically reduces by a factor 20 the fraction of memory that needs to be looked-up, which translates to a time saving of 60\% when compared to FlashAttention-v2.
Vector search with small radiuses
Mar 16, 2024
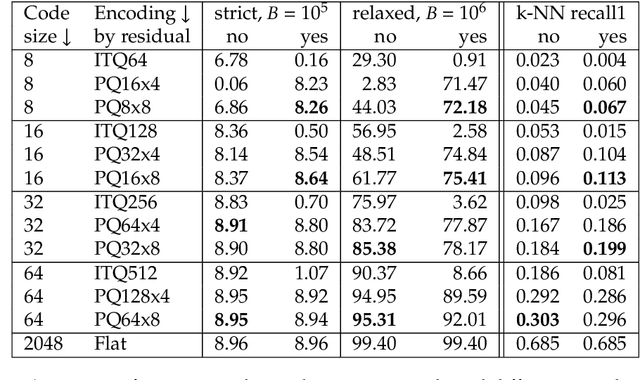
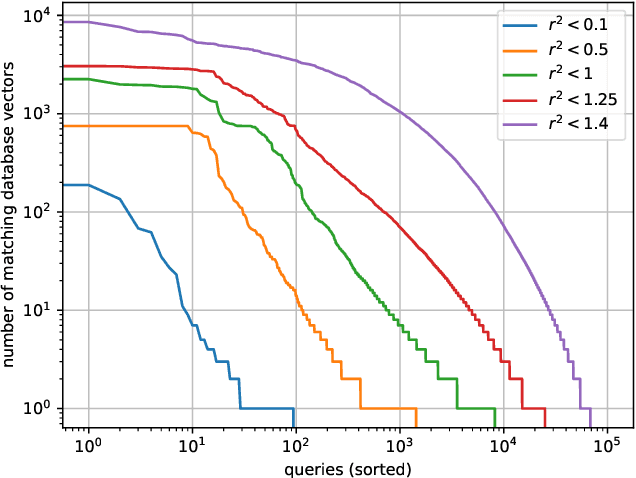
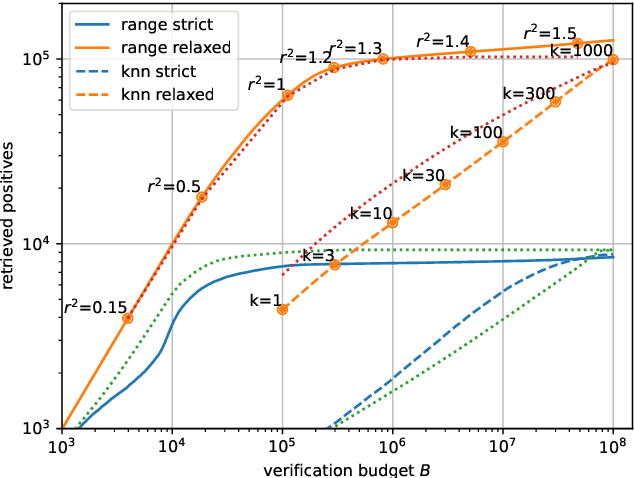
In recent years, the dominant accuracy metric for vector search is the recall of a result list of fixed size (top-k retrieval), considering as ground truth the exact vector retrieval results. Although convenient to compute, this metric is distantly related to the end-to-end accuracy of a full system that integrates vector search. In this paper we focus on the common case where a hard decision needs to be taken depending on the vector retrieval results, for example, deciding whether a query image matches a database image or not. We solve this as a range search task, where all vectors within a certain radius from the query are returned. We show that the value of a range search result can be modeled rigorously based on the query-to-vector distance. This yields a metric for range search, RSM, that is both principled and easy to compute without running an end-to-end evaluation. We apply this metric to the case of image retrieval. We show that indexing methods that are adapted for top-k retrieval do not necessarily maximize the RSM. In particular, for inverted file based indexes, we show that visiting a limited set of clusters and encoding vectors compactly yields near optimal results.
The Faiss library
Jan 16, 2024
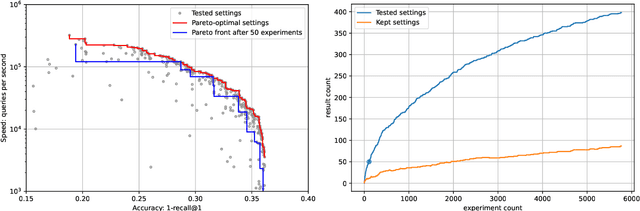

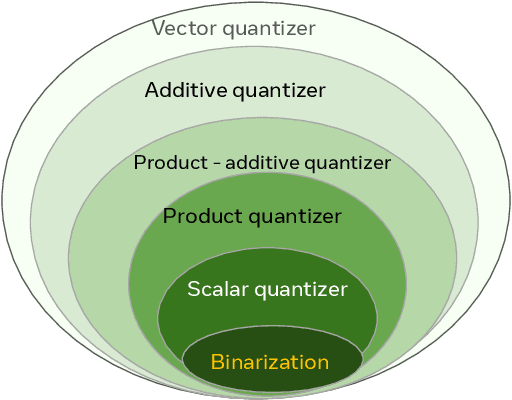
Vector databases manage large collections of embedding vectors. As AI applications are growing rapidly, so are the number of embeddings that need to be stored and indexed. The Faiss library is dedicated to vector similarity search, a core functionality of vector databases. Faiss is a toolkit of indexing methods and related primitives used to search, cluster, compress and transform vectors. This paper first describes the tradeoff space of vector search, then the design principles of Faiss in terms of structure, approach to optimization and interfacing. We benchmark key features of the library and discuss a few selected applications to highlight its broad applicability.
Improving Wikipedia Verifiability with AI
Jul 08, 2022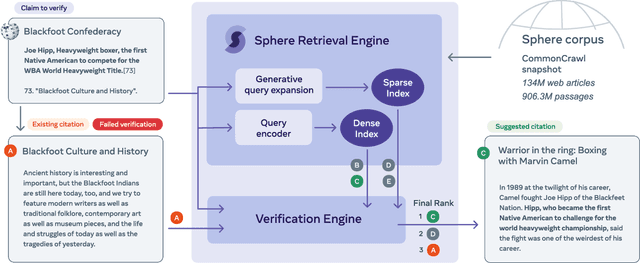

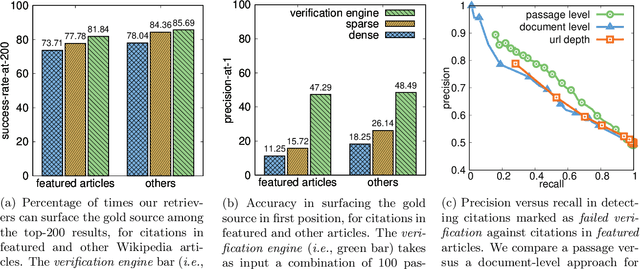
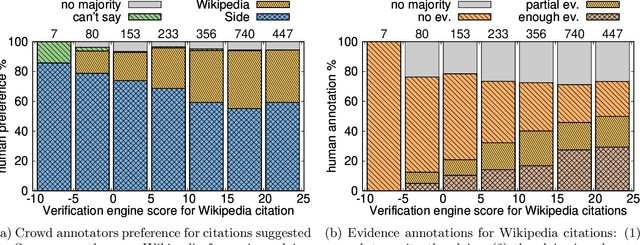
Verifiability is a core content policy of Wikipedia: claims that are likely to be challenged need to be backed by citations. There are millions of articles available online and thousands of new articles are released each month. For this reason, finding relevant sources is a difficult task: many claims do not have any references that support them. Furthermore, even existing citations might not support a given claim or become obsolete once the original source is updated or deleted. Hence, maintaining and improving the quality of Wikipedia references is an important challenge and there is a pressing need for better tools to assist humans in this effort. Here, we show that the process of improving references can be tackled with the help of artificial intelligence (AI). We develop a neural network based system, called Side, to identify Wikipedia citations that are unlikely to support their claims, and subsequently recommend better ones from the web. We train this model on existing Wikipedia references, therefore learning from the contributions and combined wisdom of thousands of Wikipedia editors. Using crowd-sourcing, we observe that for the top 10% most likely citations to be tagged as unverifiable by our system, humans prefer our system's suggested alternatives compared to the originally cited reference 70% of the time. To validate the applicability of our system, we built a demo to engage with the English-speaking Wikipedia community and find that Side's first citation recommendation collects over 60% more preferences than existing Wikipedia citations for the same top 10% most likely unverifiable claims according to Side. Our results indicate that an AI-based system could be used, in tandem with humans, to improve the verifiability of Wikipedia. More generally, we hope that our work can be used to assist fact checking efforts and increase the general trustworthiness of information online.
Data Augmenting Contrastive Learning of Speech Representations in the Time Domain
Jul 02, 2020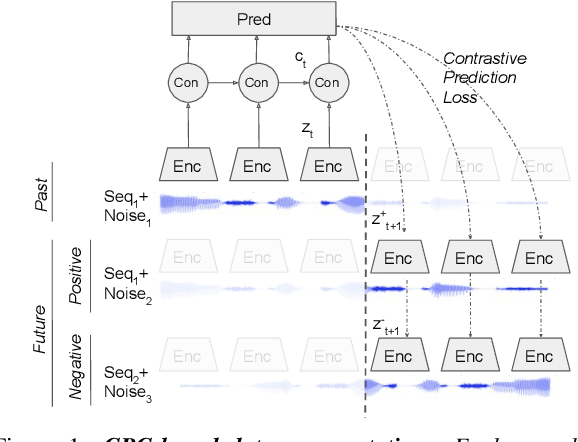
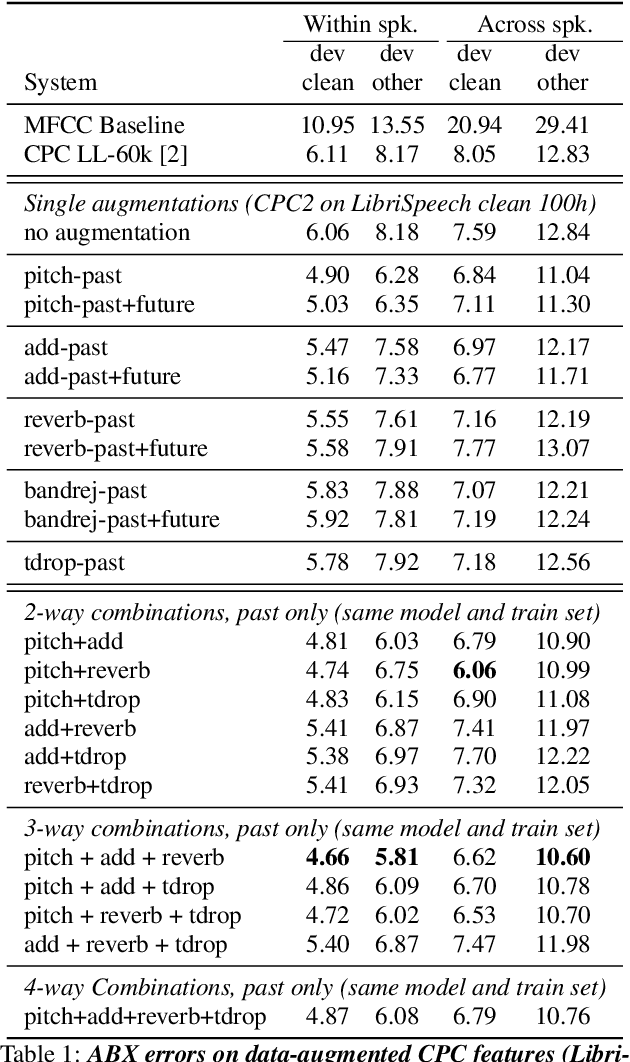

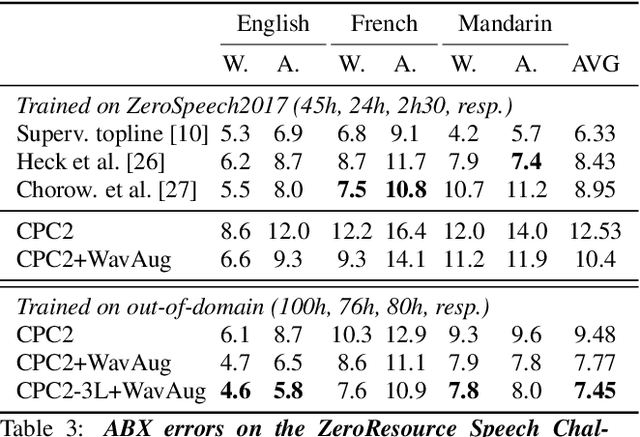
Contrastive Predictive Coding (CPC), based on predicting future segments of speech based on past segments is emerging as a powerful algorithm for representation learning of speech signal. However, it still under-performs other methods on unsupervised evaluation benchmarks. Here, we introduce WavAugment, a time-domain data augmentation library and find that applying augmentation in the past is generally more efficient and yields better performances than other methods. We find that a combination of pitch modification, additive noise and reverberation substantially increase the performance of CPC (relative improvement of 18-22%), beating the reference Libri-light results with 600 times less data. Using an out-of-domain dataset, time-domain data augmentation can push CPC to be on par with the state of the art on the Zero Speech Benchmark 2017. We also show that time-domain data augmentation consistently improves downstream limited-supervision phoneme classification tasks by a factor of 12-15% relative.
Unsupervised pretraining transfers well across languages
Feb 07, 2020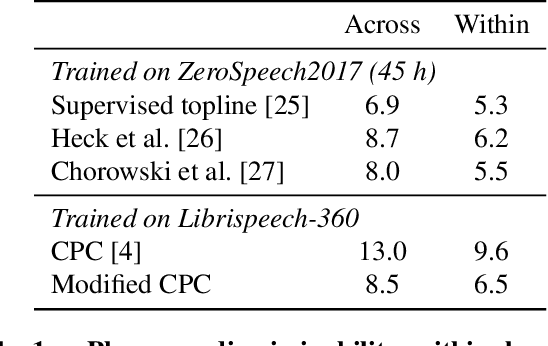
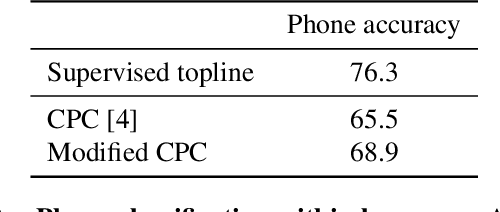
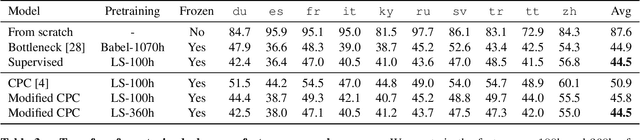
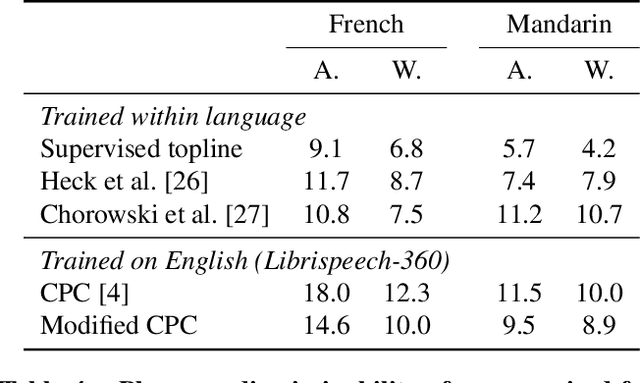
Cross-lingual and multi-lingual training of Automatic Speech Recognition (ASR) has been extensively investigated in the supervised setting. This assumes the existence of a parallel corpus of speech and orthographic transcriptions. Recently, contrastive predictive coding (CPC) algorithms have been proposed to pretrain ASR systems with unlabelled data. In this work, we investigate whether unsupervised pretraining transfers well across languages. We show that a slight modification of the CPC pretraining extracts features that transfer well to other languages, being on par or even outperforming supervised pretraining. This shows the potential of unsupervised methods for languages with few linguistic resources.
* 6 pages. Accepted at ICASSP 2020. However the 2 pages of supplementary materials will appear only in the arxiv version
Libri-Light: A Benchmark for ASR with Limited or No Supervision
Dec 17, 2019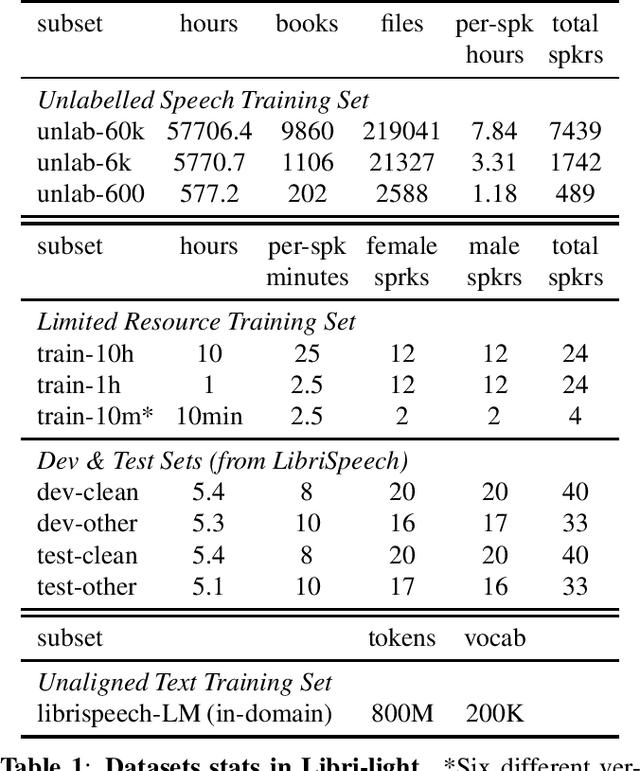
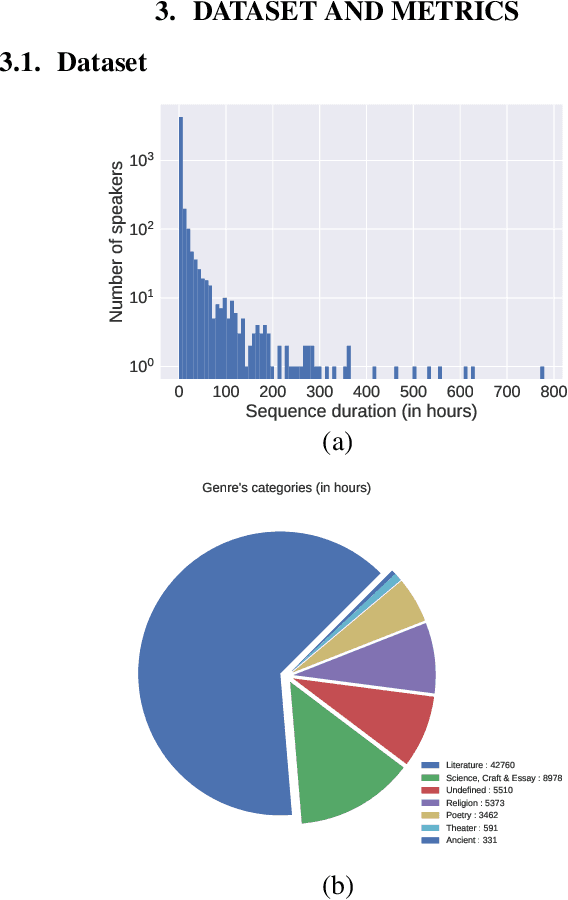
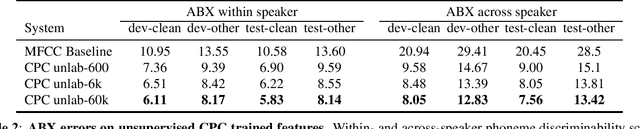
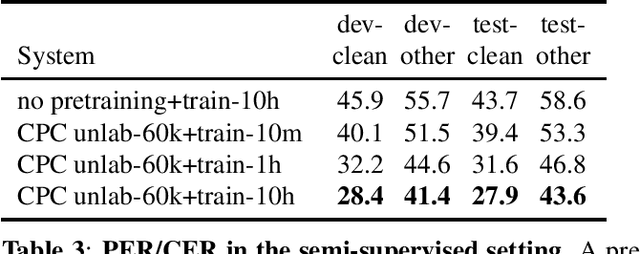
We introduce a new collection of spoken English audio suitable for training speech recognition systems under limited or no supervision. It is derived from open-source audio books from the LibriVox project. It contains over 60K hours of audio, which is, to our knowledge, the largest freely-available corpus of speech. The audio has been segmented using voice activity detection and is tagged with SNR, speaker ID and genre descriptions. Additionally, we provide baseline systems and evaluation metrics working under three settings: (1) the zero resource/unsupervised setting (ABX), (2) the semi-supervised setting (PER, CER) and (3) the distant supervision setting (WER). Settings (2) and (3) use limited textual resources (10 minutes to 10 hours) aligned with the speech. Setting (3) uses large amounts of unaligned text. They are evaluated on the standard LibriSpeech dev and test sets for comparison with the supervised state-of-the-art.
Reference-less Quality Estimation of Text Simplification Systems
Jan 30, 2019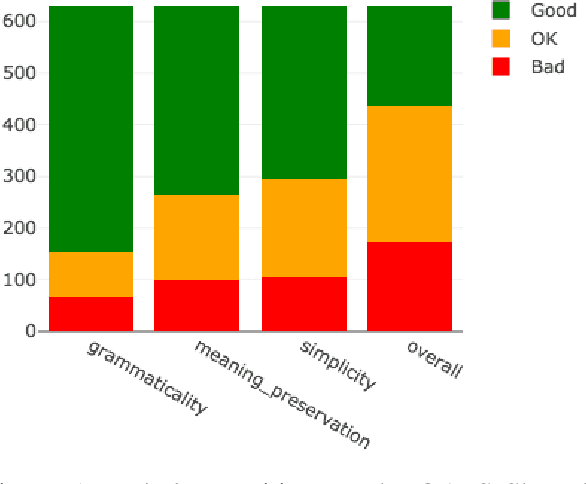
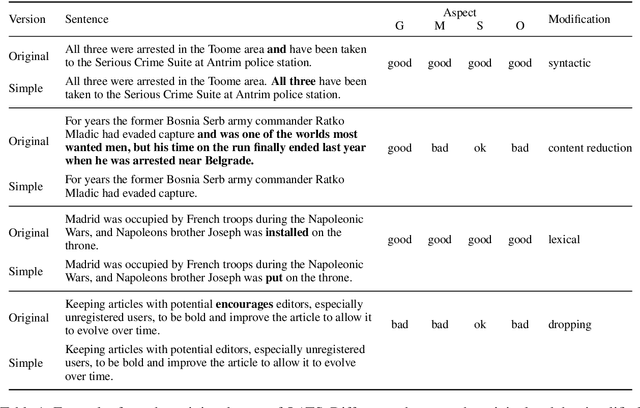
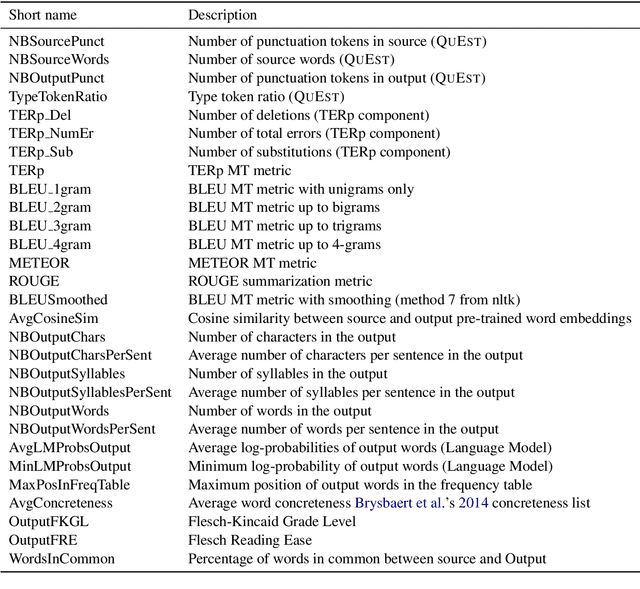
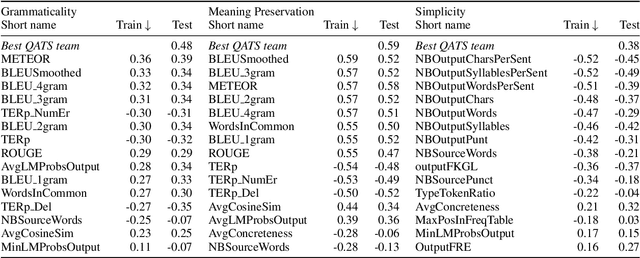
The evaluation of text simplification (TS) systems remains an open challenge. As the task has common points with machine translation (MT), TS is often evaluated using MT metrics such as BLEU. However, such metrics require high quality reference data, which is rarely available for TS. TS has the advantage over MT of being a monolingual task, which allows for direct comparisons to be made between the simplified text and its original version. In this paper, we compare multiple approaches to reference-less quality estimation of sentence-level text simplification systems, based on the dataset used for the QATS 2016 shared task. We distinguish three different dimensions: gram-maticality, meaning preservation and simplicity. We show that n-gram-based MT metrics such as BLEU and METEOR correlate the most with human judgment of grammaticality and meaning preservation, whereas simplicity is best evaluated by basic length-based metrics.
Training Millions of Personalized Dialogue Agents
Sep 06, 2018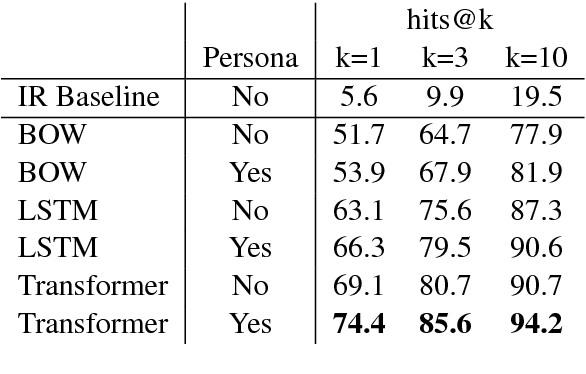
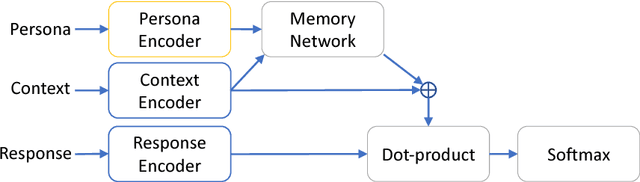
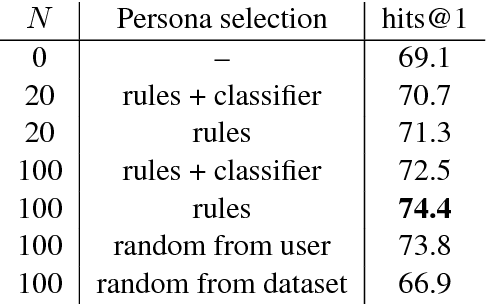
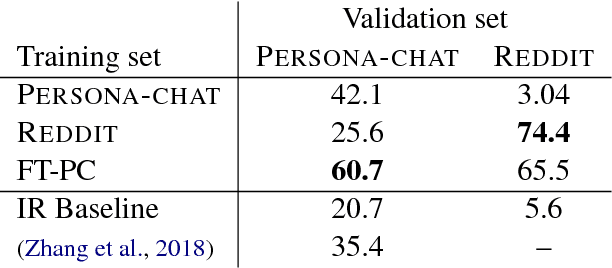
Current dialogue systems are not very engaging for users, especially when trained end-to-end without relying on proactive reengaging scripted strategies. Zhang et al. (2018) showed that the engagement level of end-to-end dialogue models increases when conditioning them on text personas providing some personalized back-story to the model. However, the dataset used in Zhang et al. (2018) is synthetic and of limited size as it contains around 1k different personas. In this paper we introduce a new dataset providing 5 million personas and 700 million persona-based dialogues. Our experiments show that, at this scale, training using personas still improves the performance of end-to-end systems. In addition, we show that other tasks benefit from the wide coverage of our dataset by fine-tuning our model on the data from Zhang et al. (2018) and achieving state-of-the-art results.