 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Fact Checking Briefs
Nov 10, 2020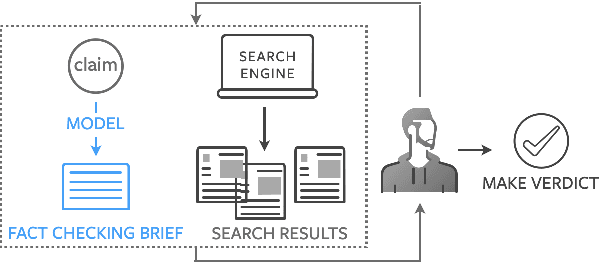
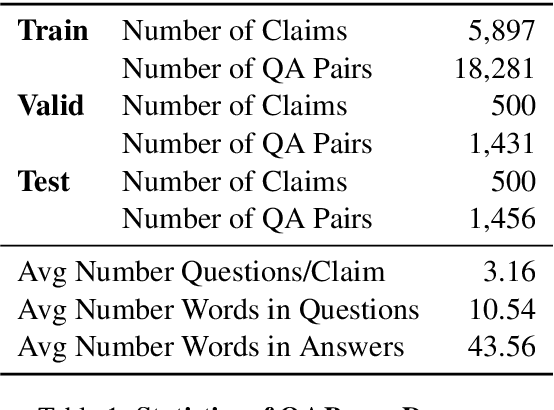

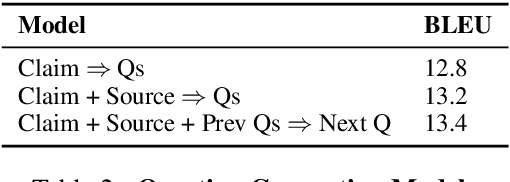
Fact checking at scale is difficult -- while the number of active fact checking websites is growing, it remains too small for the needs of the contemporary media ecosystem. However, despite good intentions, contributions from volunteers are often error-prone, and thus in practice restricted to claim detection. We investigate how to increase the accuracy and efficiency of fact checking by providing information about the claim before performing the check, in the form of natural language briefs. We investigate passage-based briefs, containing a relevant passage from Wikipedia, entity-centric ones consisting of Wikipedia pages of mentioned entities, and Question-Answering Briefs, with questions decomposing the claim, and their answers. To produce QABriefs, we develop QABriefer, a model that generates a set of questions conditioned on the claim, searches the web for evidence, and generates answers. To train its components, we introduce QABriefDataset which we collected via crowdsourcing. We show that fact checking with briefs -- in particular QABriefs -- increases the accuracy of crowdworkers by 10% while slightly decreasing the time taken. For volunteer (unpaid) fact checkers, QABriefs slightly increase accuracy and reduce the time required by around 20%.
Open-Domain Conversational Agents: Current Progress, Open Problems, and Future Directions
Jul 13, 2020We present our view of what is necessary to build an engaging open-domain conversational agent: covering the qualities of such an agent, the pieces of the puzzle that have been built so far, and the gaping holes we have not filled yet. We present a biased view, focusing on work done by our own group, while citing related work in each area. In particular, we discuss in detail the properties of continual learning, providing engaging content, and being well-behaved -- and how to measure success in providing them. We end with a discussion of our experience and learnings, and our recommendations to the community.
ASSET: A Dataset for Tuning and Evaluation of Sentence Simplification Models with Multiple Rewriting Transformations
May 01, 2020
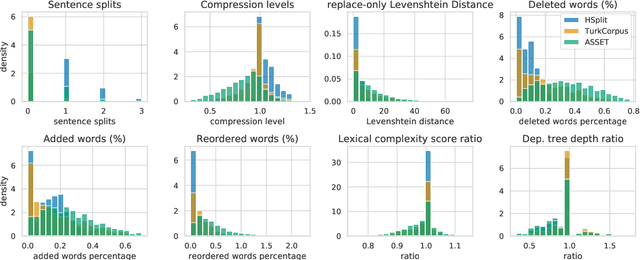
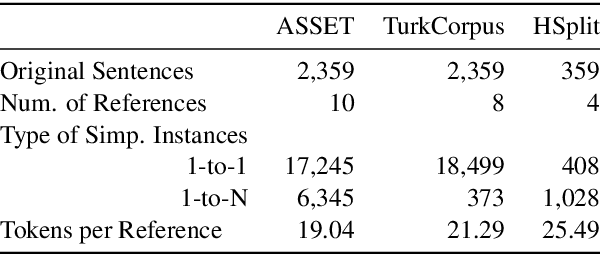
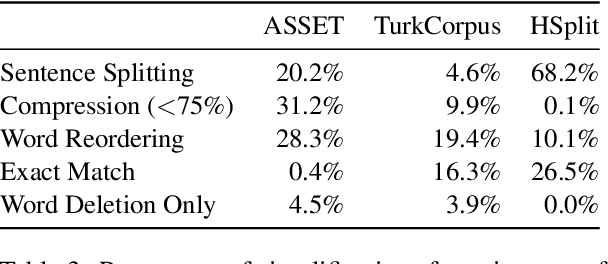
In order to simplify a sentence, human editors perform multiple rewriting transformations: they split it into several shorter sentences, paraphrase words (i.e. replacing complex words or phrases by simpler synonyms), reorder components, and/or delete information deemed unnecessary. Despite these varied range of possible text alterations, current models for automatic sentence simplification are evaluated using datasets that are focused on a single transformation, such as lexical paraphrasing or splitting. This makes it impossible to understand the ability of simplification models in more realistic settings. To alleviate this limitation, this paper introduces ASSET, a new dataset for assessing sentence simplification in English. ASSET is a crowdsourced multi-reference corpus where each simplification was produced by executing several rewriting transformations. Through quantitative and qualitative experiments, we show that simplifications in ASSET are better at capturing characteristics of simplicity when compared to other standard evaluation datasets for the task. Furthermore, we motivate the need for developing better methods for automatic evaluation using ASSET, since we show that current popular metrics may not be suitable when multiple simplification transformations are performed.
Multilingual Unsupervised Sentence Simplification
May 01, 2020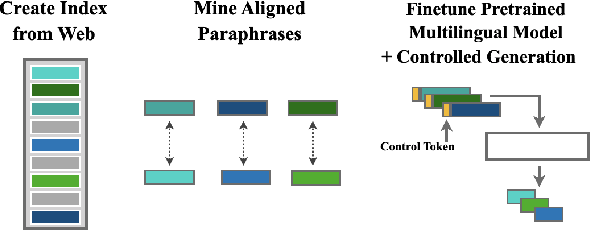

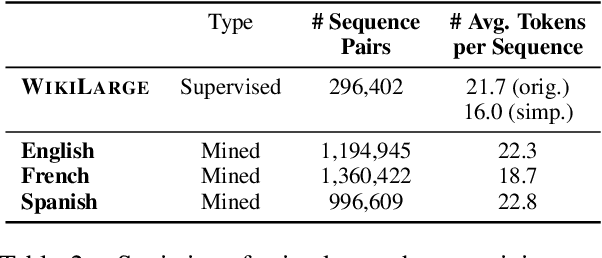
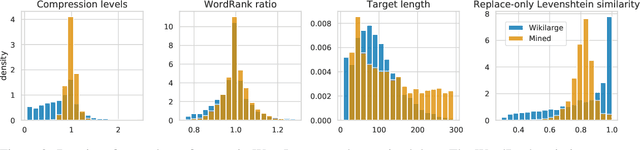
Progress in Sentence Simplification has been hindered by the lack of supervised data, particularly in languages other than English. Previous work has aligned sentences from original and simplified corpora such as English Wikipedia and Simple English Wikipedia, but this limits corpus size, domain, and language. In this work, we propose using unsupervised mining techniques to automatically create training corpora for simplification in multiple languages from raw Common Crawl web data. When coupled with a controllable generation mechanism that can flexibly adjust attributes such as length and lexical complexity, these mined paraphrase corpora can be used to train simplification systems in any language. We further incorporate multilingual unsupervised pretraining methods to create even stronger models and show that by training on mined data rather than supervised corpora, we outperform the previous best results. We evaluate our approach on English, French, and Spanish simplification benchmarks and reach state-of-the-art performance with a totally unsupervised approach. We will release our models and code to mine the data in any language included in Common Crawl.
Augmenting Transformers with KNN-Based Composite Memory for Dialogue
Apr 27, 2020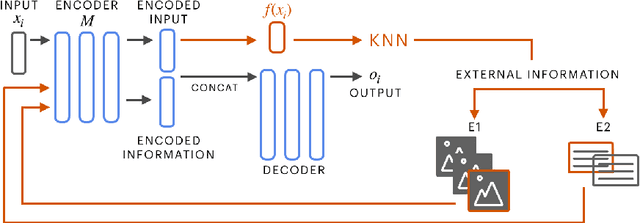
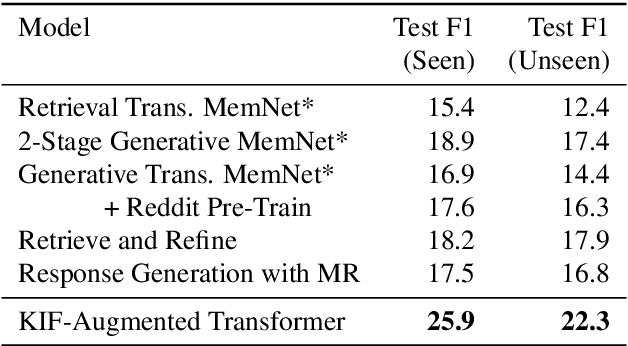
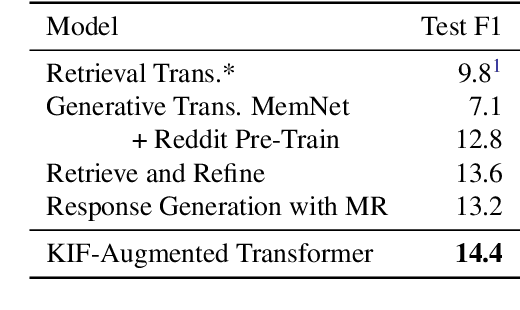
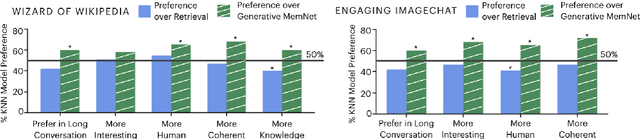
Various machine learning tasks can benefit from access to external information of different modalities, such as text and images. Recent work has focused on learning architectures with large memories capable of storing this knowledge. We propose augmenting generative Transformer neural networks with KNN-based Information Fetching (KIF) modules. Each KIF module learns a read operation to access fixed external knowledge. We apply these modules to generative dialogue modeling, a challenging task where information must be flexibly retrieved and incorporated to maintain the topic and flow of conversation. We demonstrate the effectiveness of our approach by identifying relevant knowledge from Wikipedia, images, and human-written dialogue utterances, and show that leveraging this retrieved information improves model performance, measured by automatic and human evaluation.
Using Local Knowledge Graph Construction to Scale Seq2Seq Models to Multi-Document Inputs
Oct 18, 2019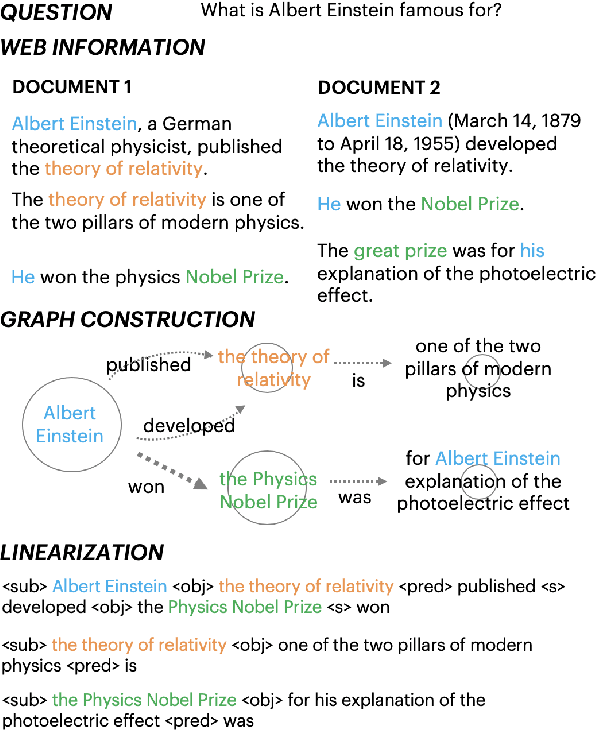
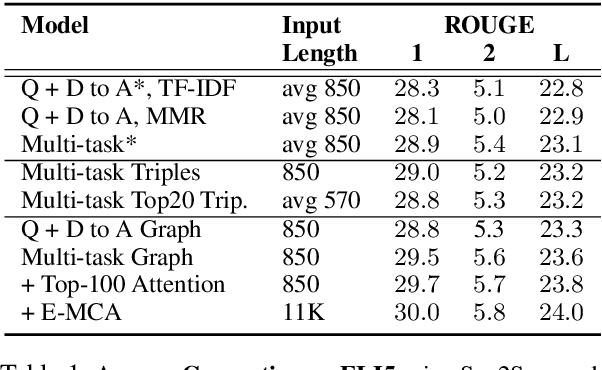
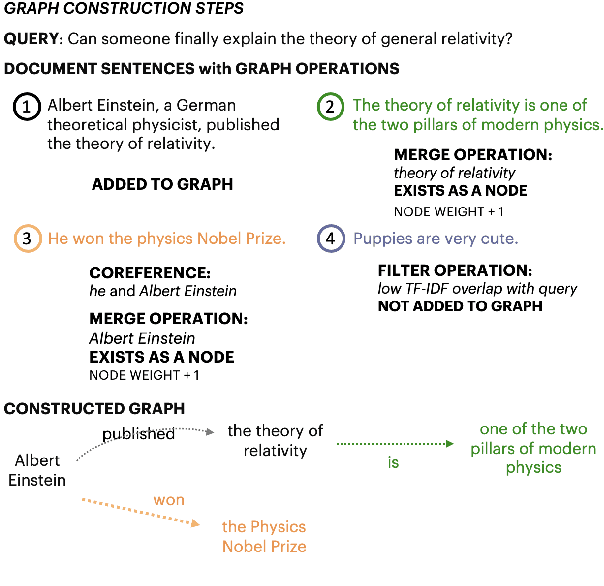
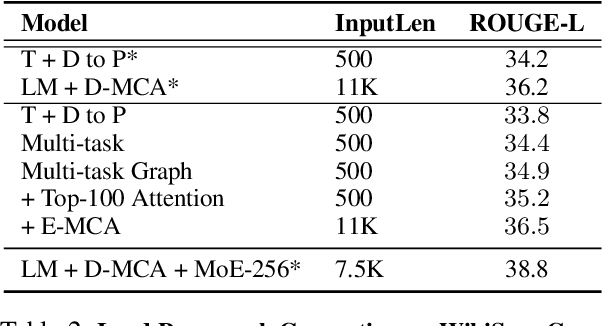
Query-based open-domain NLP tasks require information synthesis from long and diverse web results. Current approaches extractively select portions of web text as input to Sequence-to-Sequence models using methods such as TF-IDF ranking. We propose constructing a local graph structured knowledge base for each query, which compresses the web search information and reduces redundancy. We show that by linearizing the graph into a structured input sequence, models can encode the graph representations within a standard Sequence-to-Sequence setting. For two generative tasks with very long text input, long-form question answering and multi-document summarization, feeding graph representations as input can achieve better performance than using retrieved text portions.
Controllable Sentence Simplification
Oct 16, 2019



Text simplification aims at making a text easier to read and understand by simplifying grammar and structure while keeping the underlying information identical. It is often considered an all-purpose generic task where the same simplification is suitable for all; however multiple audiences can benefit from simplified text in different ways. We adapt a discrete parametrization mechanism that provides explicit control on simplification systems based on Sequence-to-Sequence models. As a result, users can condition the simplifications returned by a model on parameters such as length, amount of paraphrasing, lexical complexity and syntactic complexity. We also show that carefully chosen values of these parameters allow out-of-the-box Sequence-to-Sequence models to outperform their standard counterparts on simplification benchmarks. Our model, which we call ACCESS (as shorthand for AudienCe-CEntric Sentence Simplification), increases the state of the art to 41.87 SARI on the WikiLarge test set, a +1.42 gain over previously reported scores.
Reference-less Quality Estimation of Text Simplification Systems
Jan 30, 2019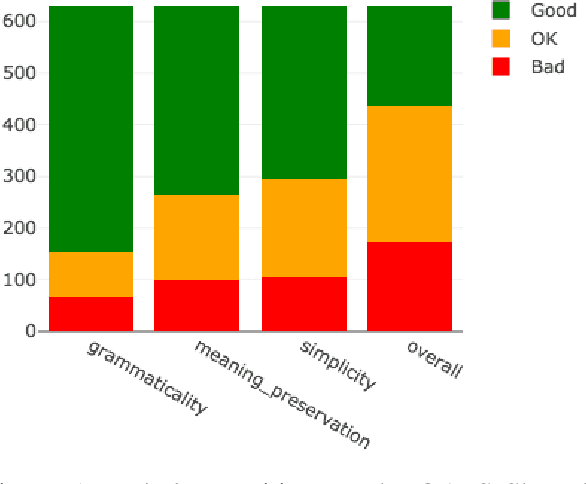
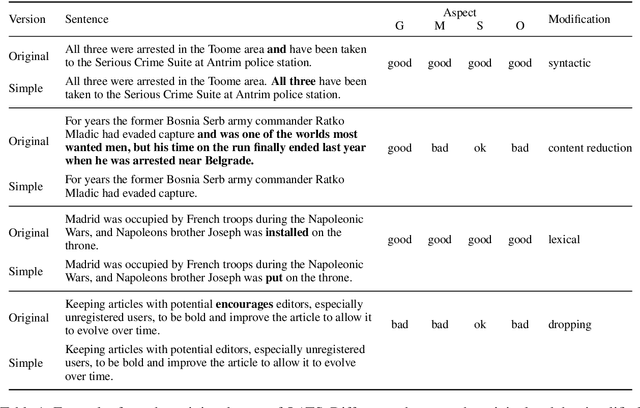
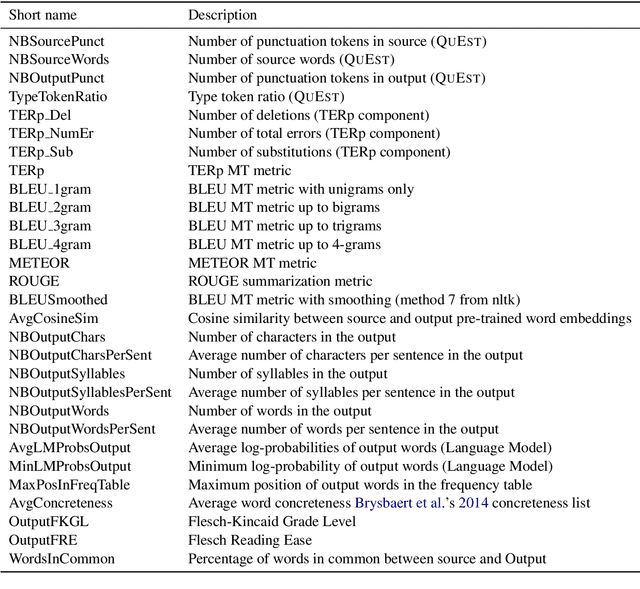
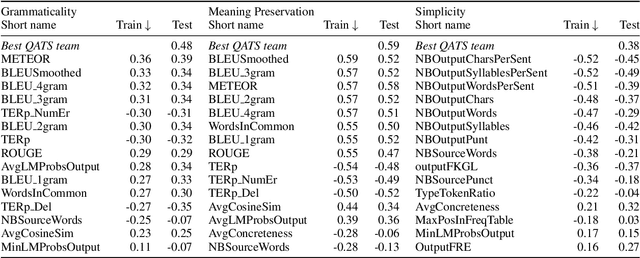
The evaluation of text simplification (TS) systems remains an open challenge. As the task has common points with machine translation (MT), TS is often evaluated using MT metrics such as BLEU. However, such metrics require high quality reference data, which is rarely available for TS. TS has the advantage over MT of being a monolingual task, which allows for direct comparisons to be made between the simplified text and its original version. In this paper, we compare multiple approaches to reference-less quality estimation of sentence-level text simplification systems, based on the dataset used for the QATS 2016 shared task. We distinguish three different dimensions: gram-maticality, meaning preservation and simplicity. We show that n-gram-based MT metrics such as BLEU and METEOR correlate the most with human judgment of grammaticality and meaning preservation, whereas simplicity is best evaluated by basic length-based metrics.
Learning from Dialogue after Deployment: Feed Yourself, Chatbot!
Jan 16, 2019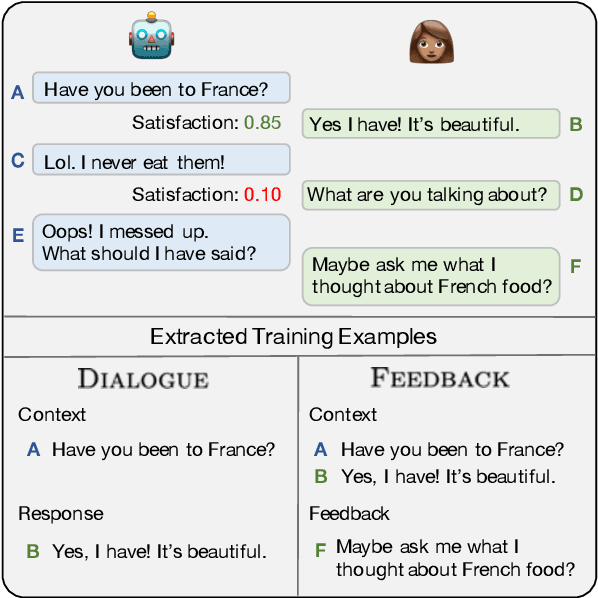
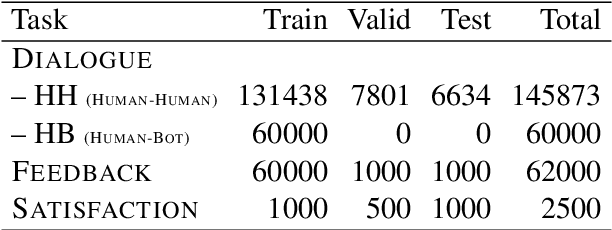
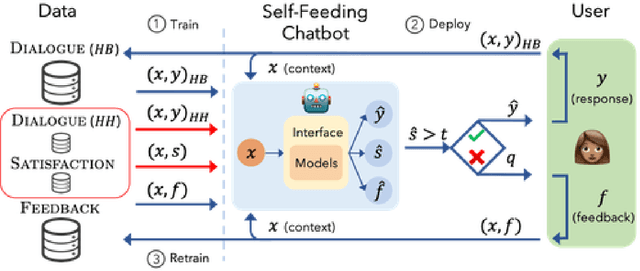

The majority of conversations a dialogue agent sees over its lifetime occur after it has already been trained and deployed, leaving a vast store of potential training signal untapped. In this work, we propose the self-feeding chatbot, a dialogue agent with the ability to extract new training examples from the conversations it participates in. As our agent engages in conversation, it also estimates user satisfaction in its responses. When the conversation appears to be going well, the user's responses become new training examples to imitate. When the agent believes it has made a mistake, it asks for feedback; learning to predict the feedback that will be given improves the chatbot's dialogue abilities further. On the PersonaChat chit-chat dataset with over 131k training examples, we find that learning from dialogue with a self-feeding chatbot significantly improves performance, regardless of the amount of traditional supervision.
Engaging Image Chat: Modeling Personality in Grounded Dialogue
Nov 02, 2018
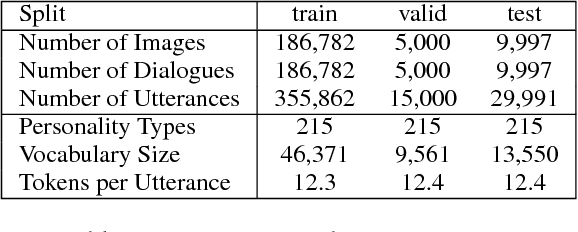
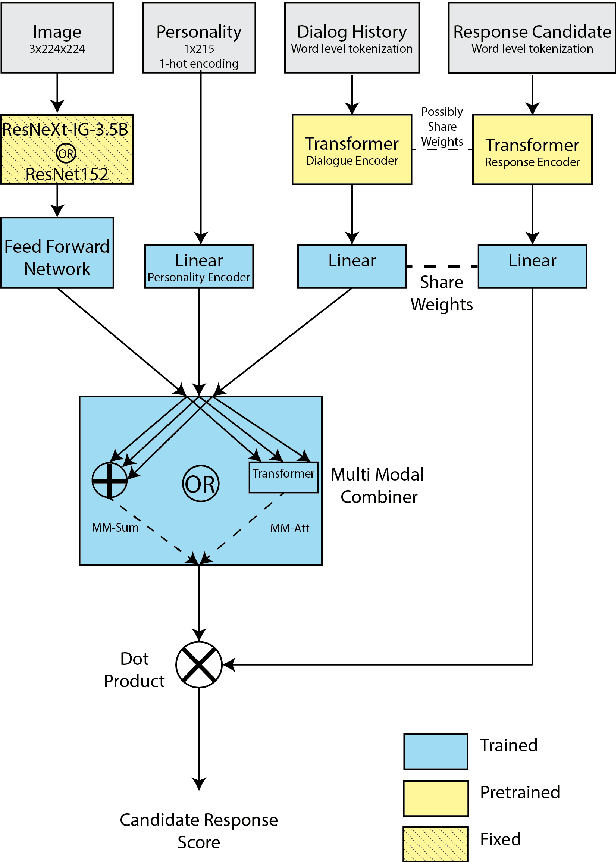

To achieve the long-term goal of machines being able to engage humans in conversation, our models should be engaging. We focus on communication grounded in images, whereby a dialogue is conducted based on a given photo, a setup that is naturally engaging to humans (Hu et al., 2014). We collect a large dataset of grounded human-human conversations, where humans are asked to play the role of a given personality, as the use of personality in conversation has also been shown to be engaging (Shuster et al., 2018). Our dataset, Image-Chat, consists of 202k dialogues and 401k utterances over 202k images using 215 possible personality traits. We then design a set of natural architectures using state-of-the-art image and text representations, considering various ways to fuse the components. Automatic metrics and human evaluations show the efficacy of approach, in particular where our best performing model is preferred over human conversationalists 47.7% of the time