 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
DMLR: Data-centric Machine Learning Research -- Past, Present and Future
Nov 21, 2023


Drawing from discussions at the inaugural DMLR workshop at ICML 2023 and meetings prior, in this report we outline the relevance of community engagement and infrastructure development for the creation of next-generation public datasets that will advance machine learning science. We chart a path forward as a collective effort to sustain the creation and maintenance of these datasets and methods towards positive scientific, societal and business impact.
Language Models in the Loop: Incorporating Prompting into Weak Supervision
May 04, 2022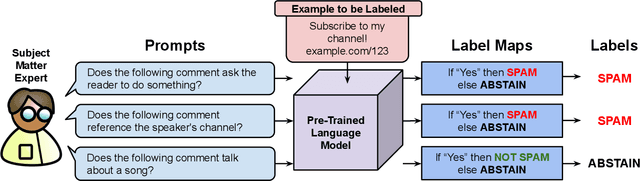

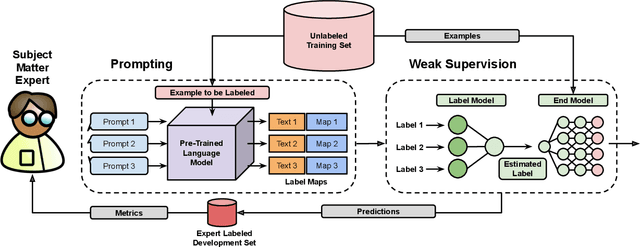

We propose a new strategy for applying large pre-trained language models to novel tasks when labeled training data is limited. Rather than apply the model in a typical zero-shot or few-shot fashion, we treat the model as the basis for labeling functions in a weak supervision framework. To create a classifier, we first prompt the model to answer multiple distinct queries about an example and define how the possible responses should be mapped to votes for labels and abstentions. We then denoise these noisy label sources using the Snorkel system and train an end classifier with the resulting training data. Our experimental evaluation shows that prompting large language models within a weak supervision framework can provide significant gains in accuracy. On the WRENCH weak supervision benchmark, this approach can significantly improve over zero-shot performance, an average 19.5% reduction in errors. We also find that this approach produces classifiers with comparable or superior accuracy to those trained from hand-engineered rules.
Learning from Dialogue after Deployment: Feed Yourself, Chatbot!
Jan 16, 2019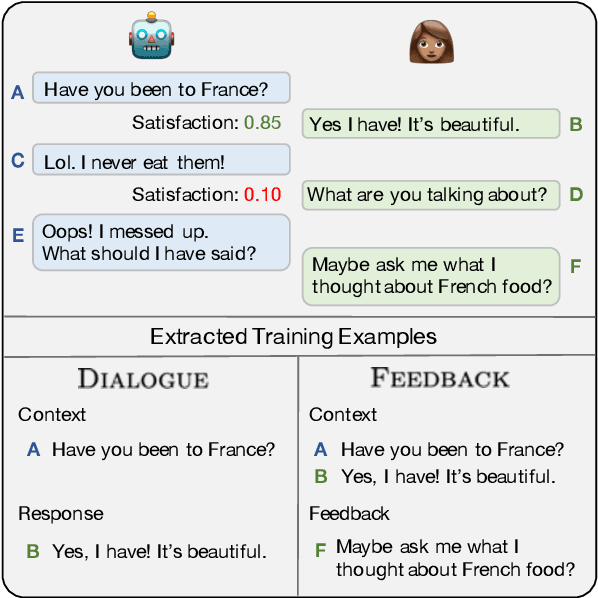
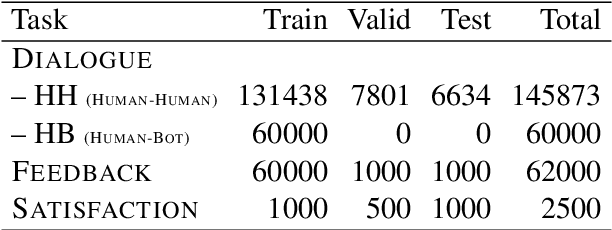
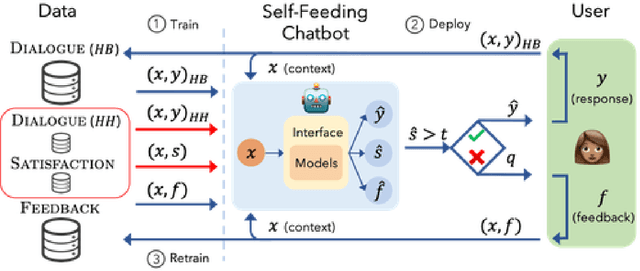

The majority of conversations a dialogue agent sees over its lifetime occur after it has already been trained and deployed, leaving a vast store of potential training signal untapped. In this work, we propose the self-feeding chatbot, a dialogue agent with the ability to extract new training examples from the conversations it participates in. As our agent engages in conversation, it also estimates user satisfaction in its responses. When the conversation appears to be going well, the user's responses become new training examples to imitate. When the agent believes it has made a mistake, it asks for feedback; learning to predict the feedback that will be given improves the chatbot's dialogue abilities further. On the PersonaChat chit-chat dataset with over 131k training examples, we find that learning from dialogue with a self-feeding chatbot significantly improves performance, regardless of the amount of traditional supervision.
Snorkel DryBell: A Case Study in Deploying Weak Supervision at Industrial Scale
Dec 02, 2018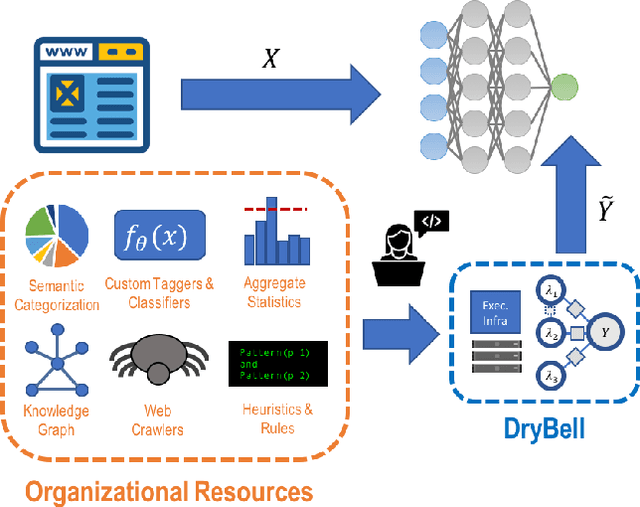


Labeling training data is one of the most costly bottlenecks in developing or modifying machine learning-based applications. We survey how resources from across an organization can be used as weak supervision sources for three classification tasks at Google, in order to bring development time and cost down by an order of magnitude. We build on the Snorkel framework, extending it as a new system, Snorkel DryBell, which integrates with Google's distributed production systems and enables engineers to develop and execute weak supervision strategies over millions of examples in less than thirty minutes. We find that Snorkel DryBell creates classifiers of comparable quality to ones trained using up to tens of thousands of hand-labeled examples, in part by leveraging organizational resources not servable in production which contribute an average 52% performance improvement to the weakly supervised classifiers.
Training Classifiers with Natural Language Explanations
Aug 25, 2018

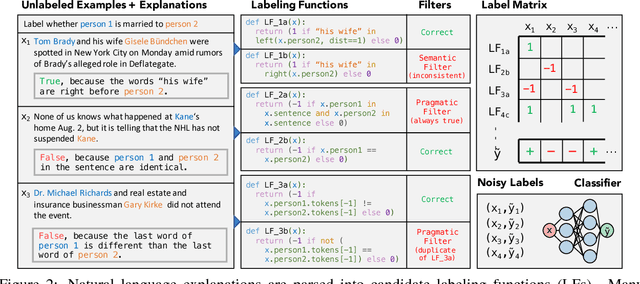
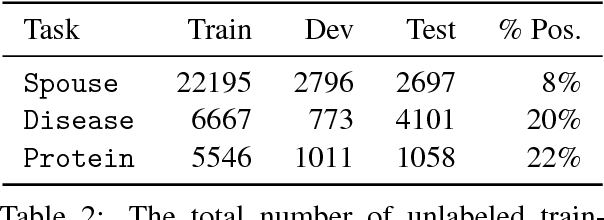
Training accurate classifiers requires many labels, but each label provides only limited information (one bit for binary classification). In this work, we propose BabbleLabble, a framework for training classifiers in which an annotator provides a natural language explanation for each labeling decision. A semantic parser converts these explanations into programmatic labeling functions that generate noisy labels for an arbitrary amount of unlabeled data, which is used to train a classifier. On three relation extraction tasks, we find that users are able to train classifiers with comparable F1 scores from 5-100$\times$ faster by providing explanations instead of just labels. Furthermore, given the inherent imperfection of labeling functions, we find that a simple rule-based semantic parser suffices.
Title Generation for Web Tables
Jun 30, 2018


Descriptive titles provide crucial context for interpreting tables that are extracted from web pages and are a key component of table-based web applications. Prior approaches have attempted to produce titles by selecting existing text snippets associated with the table. These approaches, however, are limited by their dependence on suitable titles existing a priori. In our user study, we observe that the relevant information for the title tends to be scattered across the page, and often---more than 80% of time---does not appear verbatim anywhere in the page. We propose instead the application of a sequence-to-sequence neural network model as a more generalizable means of generating high-quality titles. This is accomplished by extracting many text snippets that have potentially relevant information to the table, encoding them into an input sequence, and using both copy and generation mechanisms in the decoder to balance relevance and readability of the generated title. We validate this approach with human evaluation on sample web tables and report that while sequence models with only a copy mechanism or only a generation mechanism are easily outperformed by simple selection-based baselines, the model with both capabilities outperforms them all, approaching the quality of crowdsourced titles while training on fewer than ten thousand examples. To the best of our knowledge, the proposed technique is the first to consider text-generation methods for table titles, and establishes a new state of the art.