 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Less: Measuring the Effectiveness of RLVR in Low Data and Compute Regimes
Apr 20, 2026Fine-tuning Large Language Models (LLMs) typically relies on large quantities of high-quality annotated data, or questions with well-defined ground truth answers in the case of Reinforcement Learning with Verifiable Rewards (RLVR). While previous work has explored the benefits to model reasoning capabilities by scaling both data and compute used for RLVR, these results lack applicability in many real-world settings where annotated data and accessible compute may be scarce. In this work, we present a comprehensive empirical study of open-source Small Language Model (SLM) performance after RLVR in low data regimes. Across three novel datasets covering number counting problems, graph reasoning, and spatial reasoning, we characterize how model performance scales with dataset size, diversity, and complexity. We demonstrate that (1) procedural datasets allow for fine-grained evaluation and training dataset development with controllable properties (size, diversity, and complexity), (2) under RLVR, models trained on lower complexity tasks can generalize to higher complexity tasks, and (3) training on mixed complexity datasets is associated with the greatest benefits in low data regimes, providing up to 5x sample efficiency versus training on easy tasks. These findings inspire future work on the development of data scaling laws for RLVR and the use of procedural data generators to further understand effective data development for efficient LLM fine-tuning.
RIFT: A RubrIc Failure Mode Taxonomy and Automated Diagnostics
Apr 01, 2026Rubric-based evaluation is widely used in LLM benchmarks and training pipelines for open-ended, less verifiable tasks. While prior work has demonstrated the effectiveness of rubrics using downstream signals such as reinforcement learning outcomes, there remains no principled way to diagnose rubric quality issues from such aggregated or downstream signals alone. To address this gap, we introduce RIFT: RubrIc Failure mode Taxonomy, a taxonomy for systematically characterizing failure modes in rubric composition and design. RIFT consists of eight failure modes organized into three high-level categories: Reliability Failures, Content Validity Failures, and Consequential Validity Failures. RIFT is developed using grounded theory by iteratively annotating rubrics drawn from five diverse benchmarks spanning general instruction following, code generation, creative writing, and expert-level deep research, until no new failure modes are identified. We evaluate the consistency of the taxonomy by measuring agreement among independent human annotators, observing fair agreement overall (87% pairwise agreement and 0.64 average Cohen's kappa). Finally, to support scalable diagnosis, we propose automated rubric quality metrics and show that they align with human failure-mode annotations, achieving up to 0.86 F1.
Multi-Resolution Weak Supervision for Sequential Data
Oct 21, 2019
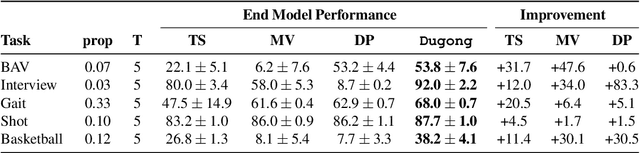
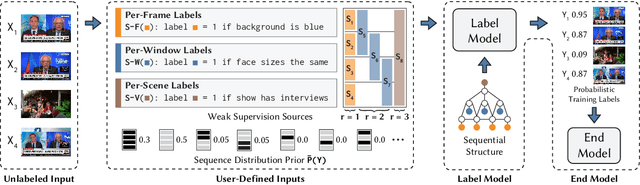

Since manually labeling training data is slow and expensive, recent industrial and scientific research efforts have turned to weaker or noisier forms of supervision sources. However, existing weak supervision approaches fail to model multi-resolution sources for sequential data, like video, that can assign labels to individual elements or collections of elements in a sequence. A key challenge in weak supervision is estimating the unknown accuracies and correlations of these sources without using labeled data. Multi-resolution sources exacerbate this challenge due to complex correlations and sample complexity that scales in the length of the sequence. We propose Dugong, the first framework to model multi-resolution weak supervision sources with complex correlations to assign probabilistic labels to training data. Theoretically, we prove that Dugong, under mild conditions, can uniquely recover the unobserved accuracy and correlation parameters and use parameter sharing to improve sample complexity. Our method assigns clinician-validated labels to population-scale biomedical video repositories, helping outperform traditional supervision by 36.8 F1 points and addressing a key use case where machine learning has been severely limited by the lack of expert labeled data. On average, Dugong improves over traditional supervision by 16.0 F1 points and existing weak supervision approaches by 24.2 F1 points across several video and sensor classification tasks.
Scene Graph Prediction with Limited Labels
Apr 25, 2019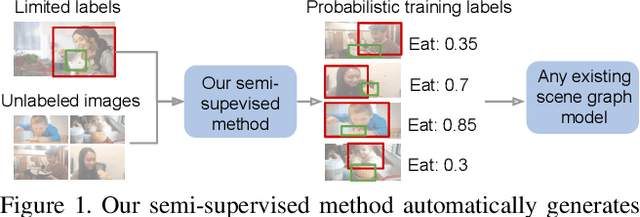
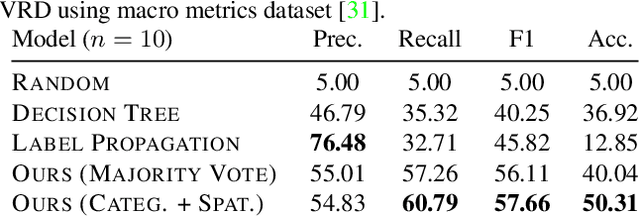
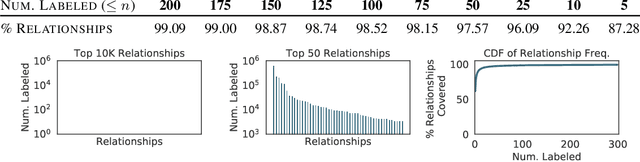

Visual knowledge bases such as Visual Genome power numerous applications in computer vision, including visual question answering and captioning, but suffer from sparse, incomplete relationships. All scene graph models to date are limited to training on a small set of visual relationships that have thousands of training labels each. Hiring human annotators is expensive, and using textual knowledge base completion methods are incompatible with visual data. In this paper, we introduce a semi-supervised method that assigns probabilistic relationship labels to a large number of unlabeled images using few labeled examples. We analyze visual relationships to suggest two types of image-agnostic features that are used to generate noisy heuristics, whose outputs are aggregated using a factor graph-based generative model. With as few as 10 labeled relationship examples, the generative model creates enough training data to train any existing state-of-the-art scene graph model. We demonstrate that our method for generating training data outperforms all baseline approaches by 5.16 recall@100. Since we only use a few labels, we define a complexity metric for relationships that serves as an indicator (R^2 = 0.778) for conditions under which our method succeeds over transfer learning, the de-facto approach for training with limited labels.
Learning Dependency Structures for Weak Supervision Models
Mar 14, 2019
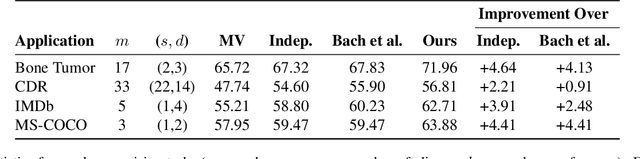
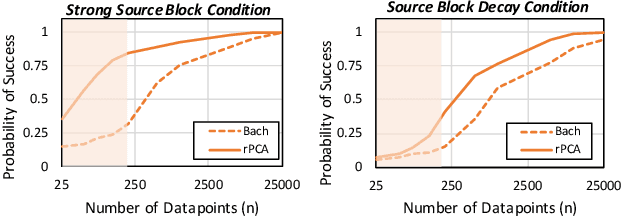
Labeling training data is a key bottleneck in the modern machine learning pipeline. Recent weak supervision approaches combine labels from multiple noisy sources by estimating their accuracies without access to ground truth labels; however, estimating the dependencies among these sources is a critical challenge. We focus on a robust PCA-based algorithm for learning these dependency structures, establish improved theoretical recovery rates, and outperform existing methods on various real-world tasks. Under certain conditions, we show that the amount of unlabeled data needed can scale sublinearly or even logarithmically with the number of sources $m$, improving over previous efforts that ignore the sparsity pattern in the dependency structure and scale linearly in $m$. We provide an information-theoretic lower bound on the minimum sample complexity of the weak supervision setting. Our method outperforms weak supervision approaches that assume conditionally-independent sources by up to 4.64 F1 points and previous structure learning approaches by up to 4.41 F1 points on real-world relation extraction and image classification tasks.
Training Classifiers with Natural Language Explanations
Aug 25, 2018

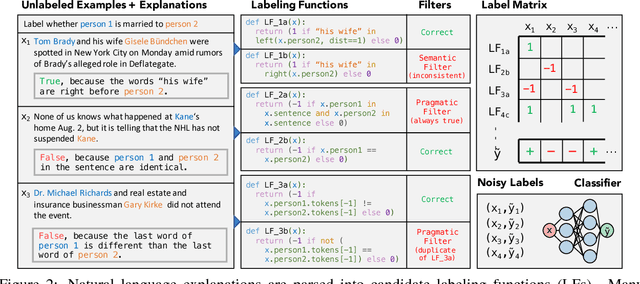
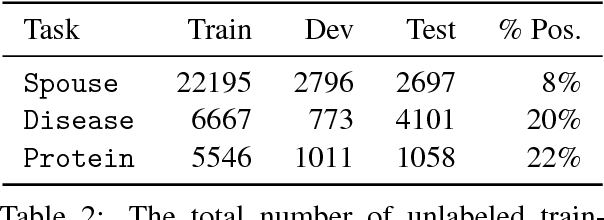
Training accurate classifiers requires many labels, but each label provides only limited information (one bit for binary classification). In this work, we propose BabbleLabble, a framework for training classifiers in which an annotator provides a natural language explanation for each labeling decision. A semantic parser converts these explanations into programmatic labeling functions that generate noisy labels for an arbitrary amount of unlabeled data, which is used to train a classifier. On three relation extraction tasks, we find that users are able to train classifiers with comparable F1 scores from 5-100$\times$ faster by providing explanations instead of just labels. Furthermore, given the inherent imperfection of labeling functions, we find that a simple rule-based semantic parser suffices.
Socratic Learning: Augmenting Generative Models to Incorporate Latent Subsets in Training Data
Sep 28, 2017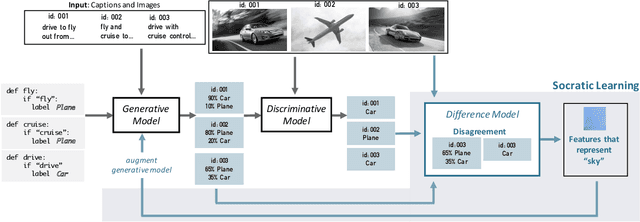


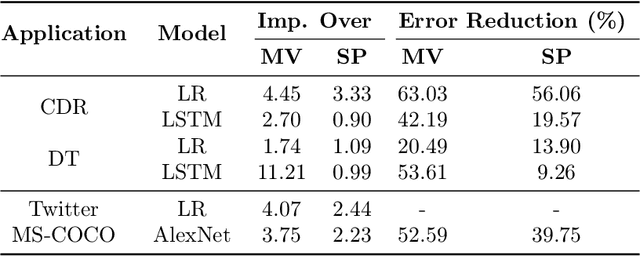
A challenge in training discriminative models like neural networks is obtaining enough labeled training data. Recent approaches use generative models to combine weak supervision sources, like user-defined heuristics or knowledge bases, to label training data. Prior work has explored learning accuracies for these sources even without ground truth labels, but they assume that a single accuracy parameter is sufficient to model the behavior of these sources over the entire training set. In particular, they fail to model latent subsets in the training data in which the supervision sources perform differently than on average. We present Socratic learning, a paradigm that uses feedback from a corresponding discriminative model to automatically identify these subsets and augments the structure of the generative model accordingly. Experimentally, we show that without any ground truth labels, the augmented generative model reduces error by up to 56.06% for a relation extraction task compared to a state-of-the-art weak supervision technique that utilizes generative models.
Inferring Generative Model Structure with Static Analysis
Sep 07, 2017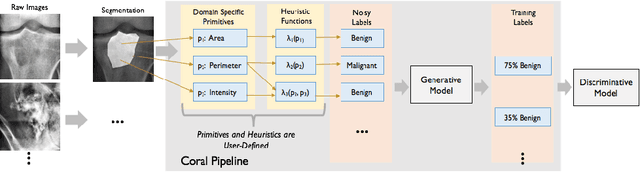


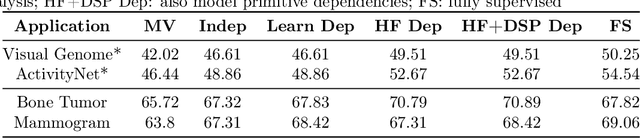
Obtaining enough labeled data to robustly train complex discriminative models is a major bottleneck in the machine learning pipeline. A popular solution is combining multiple sources of weak supervision using generative models. The structure of these models affects training label quality, but is difficult to learn without any ground truth labels. We instead rely on these weak supervision sources having some structure by virtue of being encoded programmatically. We present Coral, a paradigm that infers generative model structure by statically analyzing the code for these heuristics, thus reducing the data required to learn structure significantly. We prove that Coral's sample complexity scales quasilinearly with the number of heuristics and number of relations found, improving over the standard sample complexity, which is exponential in $n$ for identifying $n^{\textrm{th}}$ degree relations. Experimentally, Coral matches or outperforms traditional structure learning approaches by up to 3.81 F1 points. Using Coral to model dependencies instead of assuming independence results in better performance than a fully supervised model by 3.07 accuracy points when heuristics are used to label radiology data without ground truth labels.