 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocratic Learning: Augmenting Generative Models to Incorporate Latent Subsets in Training Data
Paper and Code
Sep 28, 2017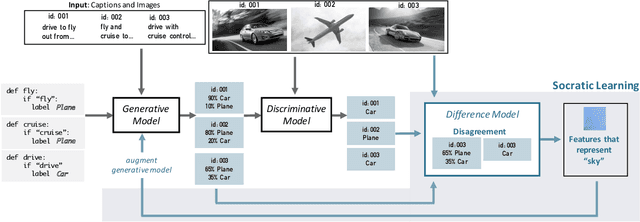


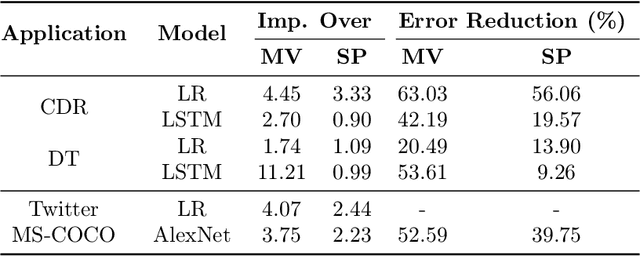
A challenge in training discriminative models like neural networks is obtaining enough labeled training data. Recent approaches use generative models to combine weak supervision sources, like user-defined heuristics or knowledge bases, to label training data. Prior work has explored learning accuracies for these sources even without ground truth labels, but they assume that a single accuracy parameter is sufficient to model the behavior of these sources over the entire training set. In particular, they fail to model latent subsets in the training data in which the supervision sources perform differently than on average. We present Socratic learning, a paradigm that uses feedback from a corresponding discriminative model to automatically identify these subsets and augments the structure of the generative model accordingly. Experimentally, we show that without any ground truth labels, the augmented generative model reduces error by up to 56.06% for a relation extraction task compared to a state-of-the-art weak supervision technique that utilizes generative models.