 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlice-based Learning: A Programming Model for Residual Learning in Critical Data Slices
Sep 13, 2019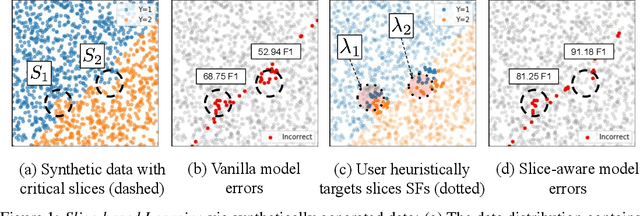
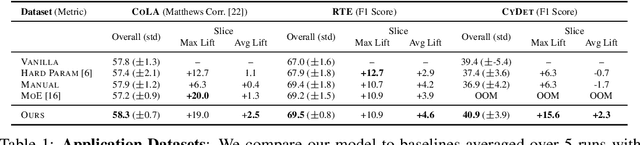
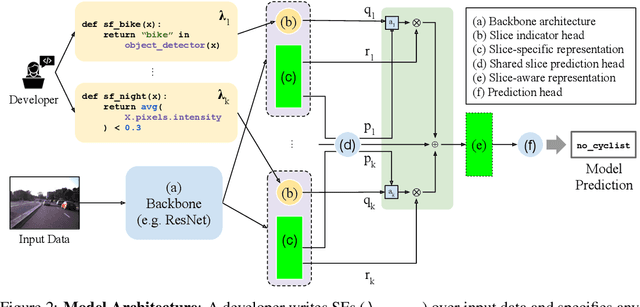
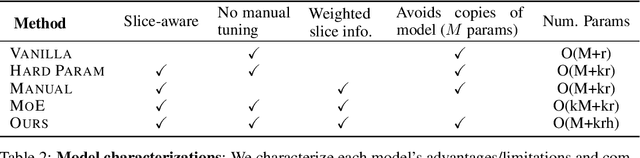
In real-world machine learning applications, data subsets correspond to especially critical outcomes: vulnerable cyclist detections are safety-critical in an autonomous driving task, and "question" sentences might be important to a dialogue agent's language understanding for product purposes. While machine learning models can achieve high quality performance on coarse-grained metrics like F1-score and overall accuracy, they may underperform on critical subsets---we define these as slices, the key abstraction in our approach. To address slice-level performance, practitioners often train separate "expert" models on slice subsets or use multi-task hard parameter sharing. We propose Slice-based Learning, a new programming model in which the slicing function (SF), a programming interface, specifies critical data subsets for which the model should commit additional capacity. Any model can leverage SFs to learn slice expert representations, which are combined with an attention mechanism to make slice-aware predictions. We show that our approach maintains a parameter-efficient representation while improving over baselines by up to 19.0 F1 on slices and 4.6 F1 overall on datasets spanning language understanding (e.g. SuperGLUE), computer vision, and production-scale industrial systems.
Scene Graph Prediction with Limited Labels
Apr 25, 2019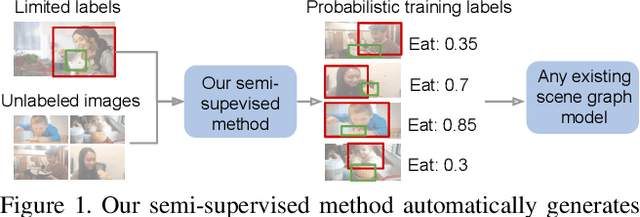
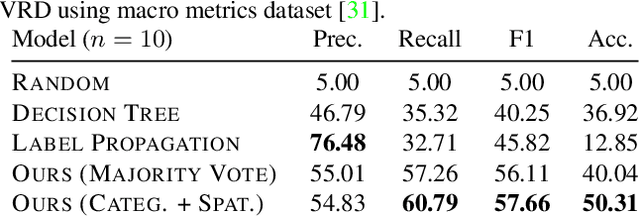
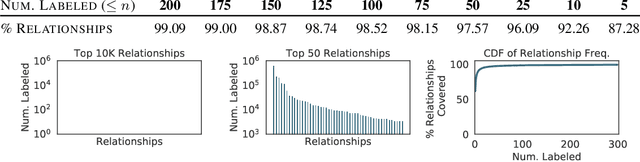

Visual knowledge bases such as Visual Genome power numerous applications in computer vision, including visual question answering and captioning, but suffer from sparse, incomplete relationships. All scene graph models to date are limited to training on a small set of visual relationships that have thousands of training labels each. Hiring human annotators is expensive, and using textual knowledge base completion methods are incompatible with visual data. In this paper, we introduce a semi-supervised method that assigns probabilistic relationship labels to a large number of unlabeled images using few labeled examples. We analyze visual relationships to suggest two types of image-agnostic features that are used to generate noisy heuristics, whose outputs are aggregated using a factor graph-based generative model. With as few as 10 labeled relationship examples, the generative model creates enough training data to train any existing state-of-the-art scene graph model. We demonstrate that our method for generating training data outperforms all baseline approaches by 5.16 recall@100. Since we only use a few labels, we define a complexity metric for relationships that serves as an indicator (R^2 = 0.778) for conditions under which our method succeeds over transfer learning, the de-facto approach for training with limited labels.