 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Prosocial Ranking Challenge: Reducing Polarization on Social Media without Sacrificing Engagement
Mar 20, 2026We report the first direct comparisons of multiple alternative social media algorithms on multiple platforms on outcomes of societal interest. We used a browser extension to modify which posts were shown to desktop social media users, randomly assigning 9,386 users to a control group or one of five alternative ranking algorithms which simultaneously altered content across three platforms for six months during the US 2024 presidential election. This reduced our preregistered index of affective polarization by an average of 0.03 standard deviations (p < 0.05), including a 1.5 degree decrease in differences between the 100 point inparty and outparty feeling thermometers. We saw reductions in active use time for Facebook (-0.37 min/day) and Reddit (-0.2 min/day), but an increase of 0.32 min/day (p < 0.01) for X/Twitter. We saw an increase in reports of negative social media experiences but found no effects on well-being, news knowledge, outgroup empathy, perceptions of and support for partisan violence. This implies that bridging content can improve some societal outcomes without necessarily conflicting with the engagement-driven business model of social media.
LLM Social Simulations Are a Promising Research Method
Apr 03, 2025Accurate and verifiable large language model (LLM) simulations of human research subjects promise an accessible data source for understanding human behavior and training new AI systems. However, results to date have been limited, and few social scientists have adopted these methods. In this position paper, we argue that the promise of LLM social simulations can be achieved by addressing five tractable challenges. We ground our argument in a literature survey of empirical comparisons between LLMs and human research subjects, commentaries on the topic, and related work. We identify promising directions with prompting, fine-tuning, and complementary methods. We believe that LLM social simulations can already be used for exploratory research, such as pilot experiments for psychology, economics, sociology, and marketing. More widespread use may soon be possible with rapidly advancing LLM capabilities, and researchers should prioritize developing conceptual models and evaluations that can be iteratively deployed and refined at pace with ongoing AI advances.
Social Media Algorithms Can Shape Affective Polarization via Exposure to Antidemocratic Attitudes and Partisan Animosity
Nov 22, 2024



There is widespread concern about the negative impacts of social media feed ranking algorithms on political polarization. Leveraging advancements in large language models (LLMs), we develop an approach to re-rank feeds in real-time to test the effects of content that is likely to polarize: expressions of antidemocratic attitudes and partisan animosity (AAPA). In a preregistered 10-day field experiment on X/Twitter with 1,256 consented participants, we increase or decrease participants' exposure to AAPA in their algorithmically curated feeds. We observe more positive outparty feelings when AAPA exposure is decreased and more negative outparty feelings when AAPA exposure is increased. Exposure to AAPA content also results in an immediate increase in negative emotions, such as sadness and anger. The interventions do not significantly impact traditional engagement metrics such as re-post and favorite rates. These findings highlight a potential pathway for developing feed algorithms that mitigate affective polarization by addressing content that undermines the shared values required for a healthy democracy.
Show, Don't Tell: Aligning Language Models with Demonstrated Feedback
Jun 02, 2024Language models are aligned to emulate the collective voice of many, resulting in outputs that align with no one in particular. Steering LLMs away from generic output is possible through supervised finetuning or RLHF, but requires prohibitively large datasets for new ad-hoc tasks. We argue that it is instead possible to align an LLM to a specific setting by leveraging a very small number ($<10$) of demonstrations as feedback. Our method, Demonstration ITerated Task Optimization (DITTO), directly aligns language model outputs to a user's demonstrated behaviors. Derived using ideas from online imitation learning, DITTO cheaply generates online comparison data by treating users' demonstrations as preferred over output from the LLM and its intermediate checkpoints. We evaluate DITTO's ability to learn fine-grained style and task alignment across domains such as news articles, emails, and blog posts. Additionally, we conduct a user study soliciting a range of demonstrations from participants ($N=16$). Across our benchmarks and user study, we find that win-rates for DITTO outperform few-shot prompting, supervised fine-tuning, and other self-play methods by an average of 19% points. By using demonstrations as feedback directly, DITTO offers a novel method for effective customization of LLMs.
Evaluating Human-Language Model Interaction
Dec 20, 2022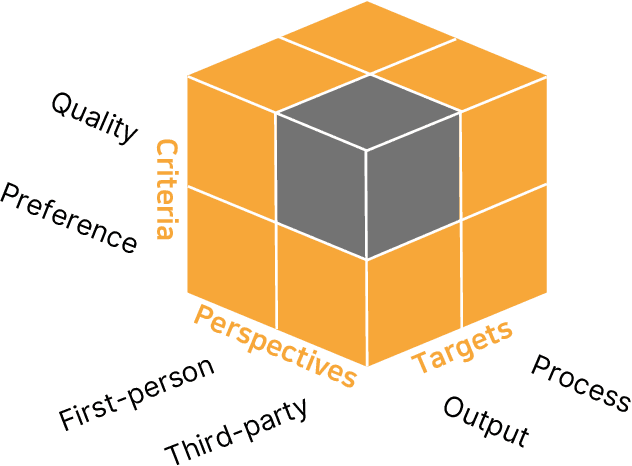
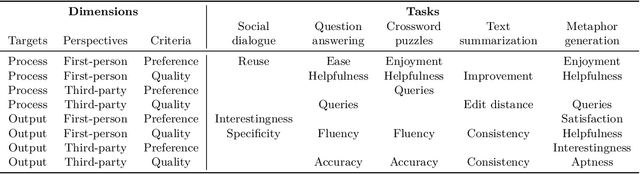
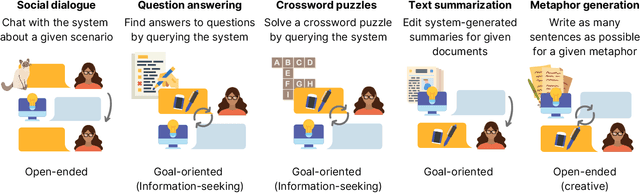

Many real-world applications of language models (LMs), such as code autocomplete and writing assistance, involve human-LM interaction. However, the main LM benchmarks are non-interactive in that a system produces output without human involvement. To evaluate human-LM interaction, we develop a new framework, Human-AI Language-based Interaction Evaluation (HALIE), that expands non-interactive evaluation along three dimensions, capturing (i) the interactive process, not only the final output; (ii) the first-person subjective experience, not just a third-party assessment; and (iii) notions of preference beyond quality. We then design five tasks ranging from goal-oriented to open-ended to capture different forms of interaction. On four state-of-the-art LMs (three variants of OpenAI's GPT-3 and AI21's J1-Jumbo), we find that non-interactive performance does not always result in better human-LM interaction and that first-person and third-party metrics can diverge, suggesting the importance of examining the nuances of human-LM interaction.
On Second Thought, Let's Not Think Step by Step! Bias and Toxicity in Zero-Shot Reasoning
Dec 15, 2022Generating a chain of thought (CoT) can increase large language model (LLM) performance on a wide range of tasks. Zero-shot CoT evaluations, however, have been conducted primarily on logical tasks (e.g. arithmetic, commonsense QA). In this paper, we perform a controlled evaluation of zero-shot CoT across two sensitive domains: harmful questions and stereotype benchmarks. We find that using zero-shot CoT reasoning in a prompt can significantly increase a model's likelihood to produce undesirable output. Without future advances in alignment or explicit mitigation instructions, zero-shot CoT should be avoided on tasks where models can make inferences about marginalized groups or harmful topics.
Explanations Can Reduce Overreliance on AI Systems During Decision-Making
Dec 13, 2022Prior work has identified a resilient phenomenon that threatens the performance of human-AI decision-making teams: overreliance, when people agree with an AI, even when it is incorrect. Surprisingly, overreliance does not reduce when the AI produces explanations for its predictions, compared to only providing predictions. Some have argued that overreliance results from cognitive biases or uncalibrated trust, attributing overreliance to an inevitability of human cognition. By contrast, our paper argues that people strategically choose whether or not to engage with an AI explanation, demonstrating empirically that there are scenarios where AI explanations reduce overreliance. To achieve this, we formalize this strategic choice in a cost-benefit framework, where the costs and benefits of engaging with the task are weighed against the costs and benefits of relying on the AI. We manipulate the costs and benefits in a maze task, where participants collaborate with a simulated AI to find the exit of a maze. Through 5 studies (N = 731), we find that costs such as task difficulty (Study 1), explanation difficulty (Study 2, 3), and benefits such as monetary compensation (Study 4) affect overreliance. Finally, Study 5 adapts the Cognitive Effort Discounting paradigm to quantify the utility of different explanations, providing further support for our framework. Our results suggest that some of the null effects found in literature could be due in part to the explanation not sufficiently reducing the costs of verifying the AI's prediction.
ELIGN: Expectation Alignment as a Multi-Agent Intrinsic Reward
Oct 09, 2022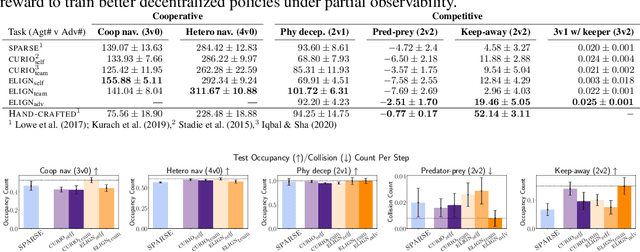

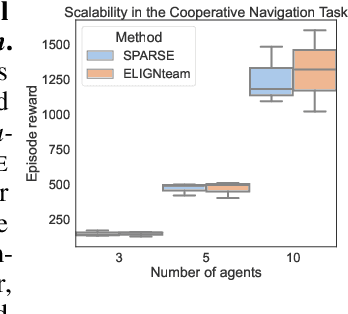

Modern multi-agent reinforcement learning frameworks rely on centralized training and reward shaping to perform well. However, centralized training and dense rewards are not readily available in the real world. Current multi-agent algorithms struggle to learn in the alternative setup of decentralized training or sparse rewards. To address these issues, we propose a self-supervised intrinsic reward ELIGN - expectation alignment - inspired by the self-organization principle in Zoology. Similar to how animals collaborate in a decentralized manner with those in their vicinity, agents trained with expectation alignment learn behaviors that match their neighbors' expectations. This allows the agents to learn collaborative behaviors without any external reward or centralized training. We demonstrate the efficacy of our approach across 6 tasks in the multi-agent particle and the complex Google Research football environments, comparing ELIGN to sparse and curiosity-based intrinsic rewards. When the number of agents increases, ELIGN scales well in all multi-agent tasks except for one where agents have different capabilities. We show that agent coordination improves through expectation alignment because agents learn to divide tasks amongst themselves, break coordination symmetries, and confuse adversaries. These results identify tasks where expectation alignment is a more useful strategy than curiosity-driven exploration for multi-agent coordination, enabling agents to do zero-shot coordination.
Visual Intelligence through Human Interaction
Nov 12, 2021Over the last decade, Computer Vision, the branch of Artificial Intelligence aimed at understanding the visual world, has evolved from simply recognizing objects in images to describing pictures, answering questions about images, aiding robots maneuver around physical spaces and even generating novel visual content. As these tasks and applications have modernized, so too has the reliance on more data, either for model training or for evaluation. In this chapter, we demonstrate that novel interaction strategies can enable new forms of data collection and evaluation for Computer Vision. First, we present a crowdsourcing interface for speeding up paid data collection by an order of magnitude, feeding the data-hungry nature of modern vision models. Second, we explore a method to increase volunteer contributions using automated social interventions. Third, we develop a system to ensure human evaluation of generative vision models are reliable, affordable and grounded in psychophysics theory. We conclude with future opportunities for Human-Computer Interaction to aid Computer Vision.
Conceptual Metaphors Impact Perceptions of Human-AI Collaboration
Aug 05, 2020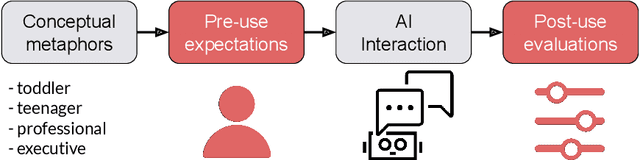
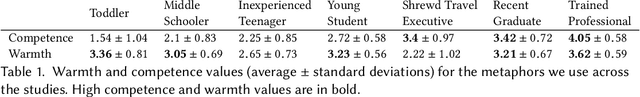
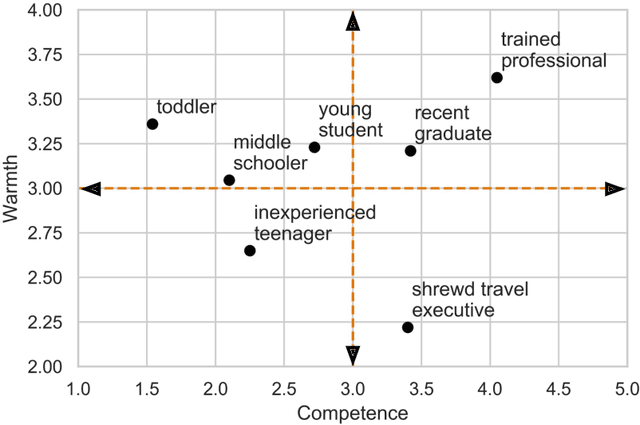
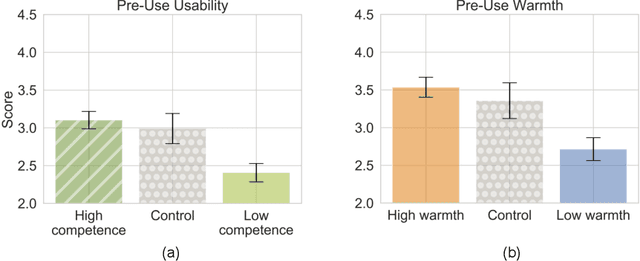
With the emergence of conversational artificial intelligence (AI) agents, it is important to understand the mechanisms that influence users' experiences of these agents. We study a common tool in the designer's toolkit: conceptual metaphors. Metaphors can present an agent as akin to a wry teenager, a toddler, or an experienced butler. How might a choice of metaphor influence our experience of the AI agent? Sampling metaphors along the dimensions of warmth and competence---defined by psychological theories as the primary axes of variation for human social perception---we perform a study (N=260) where we manipulate the metaphor, but not the behavior, of a Wizard-of-Oz conversational agent. Following the experience, participants are surveyed about their intention to use the agent, their desire to cooperate with the agent, and the agent's usability. Contrary to the current tendency of designers to use high competence metaphors to describe AI products, we find that metaphors that signal low competence lead to better evaluations of the agent than metaphors that signal high competence. This effect persists despite both high and low competence agents featuring human-level performance and the wizards being blind to condition. A second study confirms that intention to adopt decreases rapidly as competence projected by the metaphor increases. In a third study, we assess effects of metaphor choices on potential users' desire to try out the system and find that users are drawn to systems that project higher competence and warmth. These results suggest that projecting competence may help attract new users, but those users may discard the agent unless it can quickly correct with a lower competence metaphor. We close with a retrospective analysis that finds similar patterns between metaphors and user attitudes towards past conversational agents such as Xiaoice, Replika, Woebot, Mitsuku, and Tay.
* CSCW 2020