 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Bayesian Active Learning for Multiple Correct Outputs
Paper and Code
Dec 08, 2019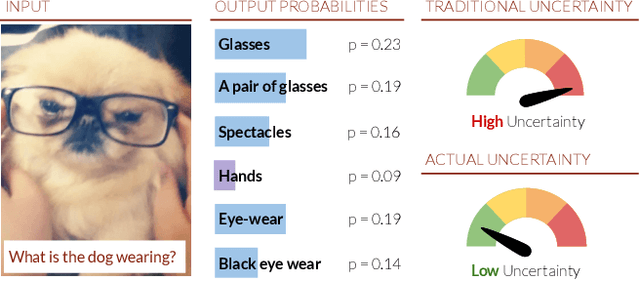
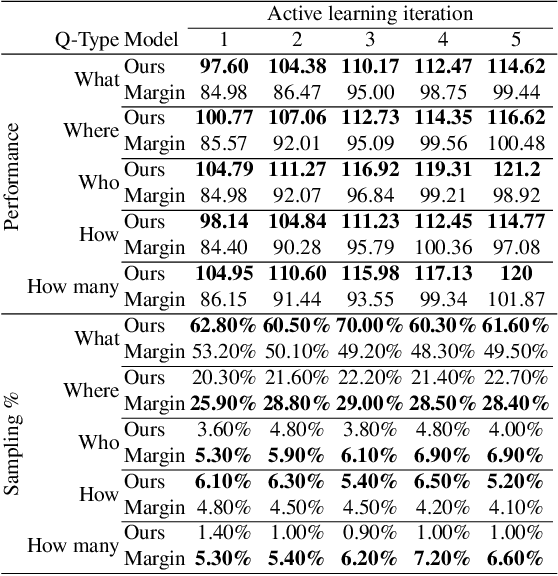
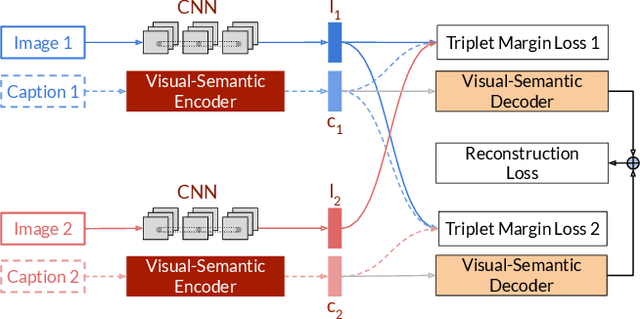
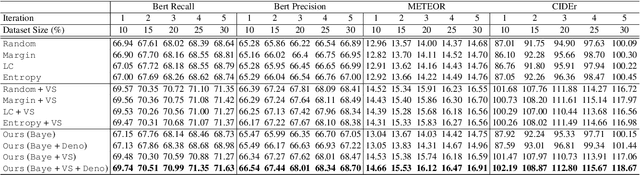
Typical active learning strategies are designed for tasks, such as classification, with the assumption that the output space is mutually exclusive. The assumption that these tasks always have exactly one correct answer has resulted in the creation of numerous uncertainty-based measurements, such as entropy and least confidence, which operate over a model's outputs. Unfortunately, many real-world vision tasks, like visual question answering and image captioning, have multiple correct answers, causing these measurements to overestimate uncertainty and sometimes perform worse than a random sampling baseline. In this paper, we propose a new paradigm that estimates uncertainty in the model's internal hidden space instead of the model's output space. We specifically study a manifestation of this problem for visual question answer generation (VQA), where the aim is not to classify the correct answer but to produce a natural language answer, given an image and a question. Our method overcomes the paraphrastic nature of language. It requires a semantic space that structures the model's output concepts and that enables the usage of techniques like dropout-based Bayesian uncertainty. We build a visual-semantic space that embeds paraphrases close together for any existing VQA model. We empirically show state-of-art active learning results on the task of VQA on two datasets, being 5 times more cost-efficient on Visual Genome and 3 times more cost-efficient on VQA 2.0.