 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Representations inside the Language Model
Oct 06, 2025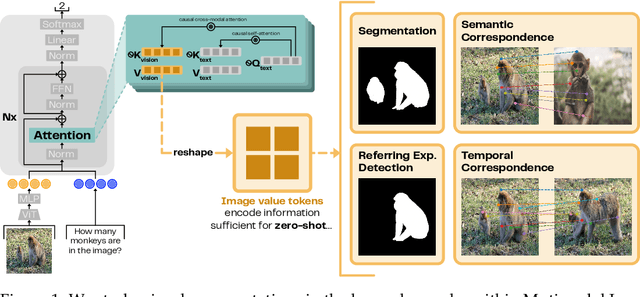

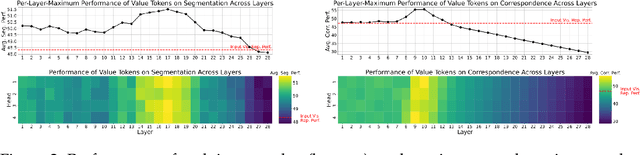
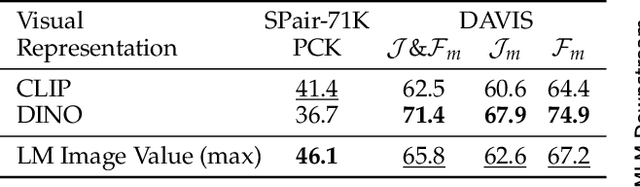
Despite interpretability work analyzing VIT encoders and transformer activations, we don't yet understand why Multimodal Language Models (MLMs) struggle on perception-heavy tasks. We offer an under-studied perspective by examining how popular MLMs (LLaVA-OneVision, Qwen2.5-VL, and Llama-3-LLaVA-NeXT) process their visual key-value tokens. We first study the flow of visual information through the language model, finding that image value tokens encode sufficient information to perform several perception-heavy tasks zero-shot: segmentation, semantic correspondence, temporal correspondence, and referring expression detection. We find that while the language model does augment the visual information received from the projection of input visual encodings-which we reveal correlates with overall MLM perception capability-it contains less visual information on several tasks than the equivalent visual encoder (SigLIP) that has not undergone MLM finetuning. Further, we find that the visual information corresponding to input-agnostic image key tokens in later layers of language models contains artifacts which reduce perception capability of the overall MLM. Next, we discuss controlling visual information in the language model, showing that adding a text prefix to the image input improves perception capabilities of visual representations. Finally, we reveal that if language models were able to better control their visual information, their perception would significantly improve; e.g., in 33.3% of Art Style questions in the BLINK benchmark, perception information present in the language model is not surfaced to the output! Our findings reveal insights into the role of key-value tokens in multimodal systems, paving the way for deeper mechanistic interpretability of MLMs and suggesting new directions for training their visual encoder and language model components.
Magentic-UI: Towards Human-in-the-loop Agentic Systems
Jul 30, 2025AI agents powered by large language models are increasingly capable of autonomously completing complex, multi-step tasks using external tools. Yet, they still fall short of human-level performance in most domains including computer use, software development, and research. Their growing autonomy and ability to interact with the outside world, also introduces safety and security risks including potentially misaligned actions and adversarial manipulation. We argue that human-in-the-loop agentic systems offer a promising path forward, combining human oversight and control with AI efficiency to unlock productivity from imperfect systems. We introduce Magentic-UI, an open-source web interface for developing and studying human-agent interaction. Built on a flexible multi-agent architecture, Magentic-UI supports web browsing, code execution, and file manipulation, and can be extended with diverse tools via Model Context Protocol (MCP). Moreover, Magentic-UI presents six interaction mechanisms for enabling effective, low-cost human involvement: co-planning, co-tasking, multi-tasking, action guards, and long-term memory. We evaluate Magentic-UI across four dimensions: autonomous task completion on agentic benchmarks, simulated user testing of its interaction capabilities, qualitative studies with real users, and targeted safety assessments. Our findings highlight Magentic-UI's potential to advance safe and efficient human-agent collaboration.
Designing LLM Chains by Adapting Techniques from Crowdsourcing Workflows
Dec 20, 2023


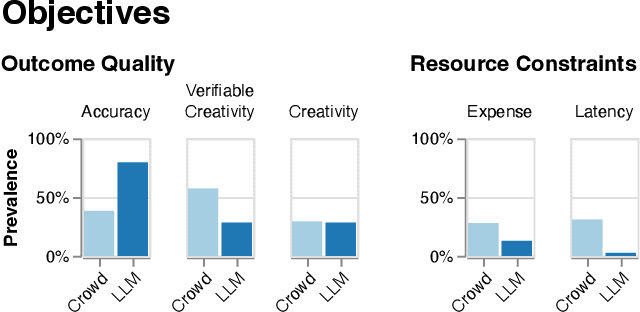
LLM chains enable complex tasks by decomposing work into a sequence of sub-tasks. Crowdsourcing workflows similarly decompose complex tasks into smaller tasks for human crowdworkers. Chains address LLM errors analogously to the way crowdsourcing workflows address human error. To characterize opportunities for LLM chaining, we survey 107 papers across the crowdsourcing and chaining literature to construct a design space for chain development. The design space connects an LLM designer's objectives to strategies they can use to achieve those objectives, and tactics to implement each strategy. To explore how techniques from crowdsourcing may apply to chaining, we adapt crowdsourcing workflows to implement LLM chains across three case studies: creating a taxonomy, shortening text, and writing a short story. From the design space and our case studies, we identify which techniques transfer from crowdsourcing to LLM chaining and raise implications for future research and development.
Explanations Can Reduce Overreliance on AI Systems During Decision-Making
Dec 13, 2022Prior work has identified a resilient phenomenon that threatens the performance of human-AI decision-making teams: overreliance, when people agree with an AI, even when it is incorrect. Surprisingly, overreliance does not reduce when the AI produces explanations for its predictions, compared to only providing predictions. Some have argued that overreliance results from cognitive biases or uncalibrated trust, attributing overreliance to an inevitability of human cognition. By contrast, our paper argues that people strategically choose whether or not to engage with an AI explanation, demonstrating empirically that there are scenarios where AI explanations reduce overreliance. To achieve this, we formalize this strategic choice in a cost-benefit framework, where the costs and benefits of engaging with the task are weighed against the costs and benefits of relying on the AI. We manipulate the costs and benefits in a maze task, where participants collaborate with a simulated AI to find the exit of a maze. Through 5 studies (N = 731), we find that costs such as task difficulty (Study 1), explanation difficulty (Study 2, 3), and benefits such as monetary compensation (Study 4) affect overreliance. Finally, Study 5 adapts the Cognitive Effort Discounting paradigm to quantify the utility of different explanations, providing further support for our framework. Our results suggest that some of the null effects found in literature could be due in part to the explanation not sufficiently reducing the costs of verifying the AI's prediction.
Measuring Compositional Consistency for Video Question Answering
Apr 14, 2022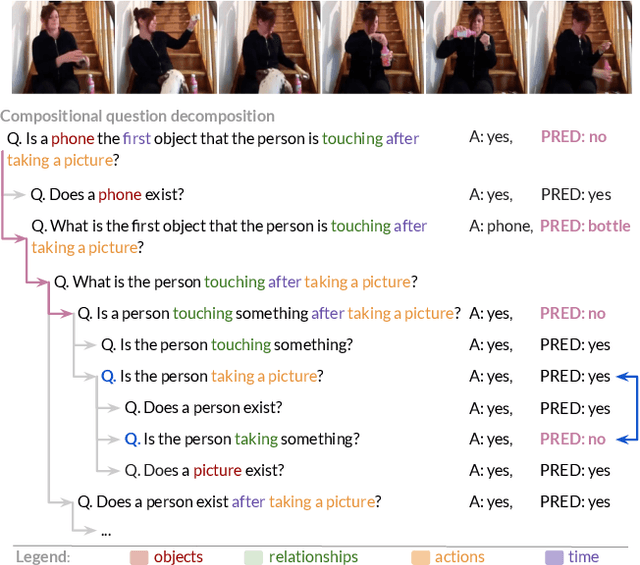
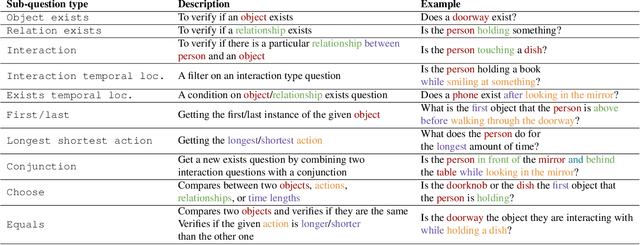
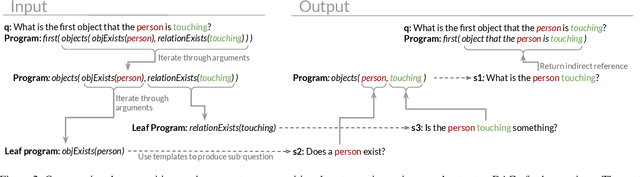
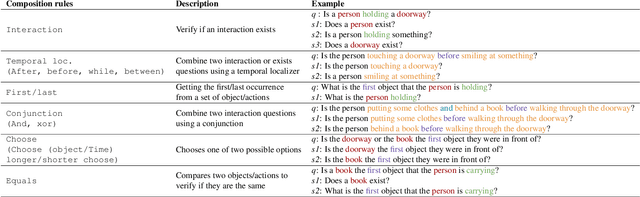
Recent video question answering benchmarks indicate that state-of-the-art models struggle to answer compositional questions. However, it remains unclear which types of compositional reasoning cause models to mispredict. Furthermore, it is difficult to discern whether models arrive at answers using compositional reasoning or by leveraging data biases. In this paper, we develop a question decomposition engine that programmatically deconstructs a compositional question into a directed acyclic graph of sub-questions. The graph is designed such that each parent question is a composition of its children. We present AGQA-Decomp, a benchmark containing $2.3M$ question graphs, with an average of $11.49$ sub-questions per graph, and $4.55M$ total new sub-questions. Using question graphs, we evaluate three state-of-the-art models with a suite of novel compositional consistency metrics. We find that models either cannot reason correctly through most compositions or are reliant on incorrect reasoning to reach answers, frequently contradicting themselves or achieving high accuracies when failing at intermediate reasoning steps.
* To appear in CVPR 2022. 23 pages, 12 figures and 12 tables
AGQA 2.0: An Updated Benchmark for Compositional Spatio-Temporal Reasoning
Apr 12, 2022



Prior benchmarks have analyzed models' answers to questions about videos in order to measure visual compositional reasoning. Action Genome Question Answering (AGQA) is one such benchmark. AGQA provides a training/test split with balanced answer distributions to reduce the effect of linguistic biases. However, some biases remain in several AGQA categories. We introduce AGQA 2.0, a version of this benchmark with several improvements, most namely a stricter balancing procedure. We then report results on the updated benchmark for all experiments.
AGQA: A Benchmark for Compositional Spatio-Temporal Reasoning
Mar 30, 2021

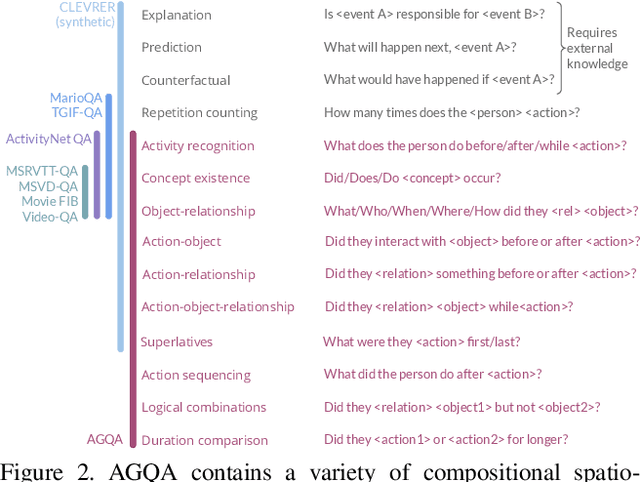
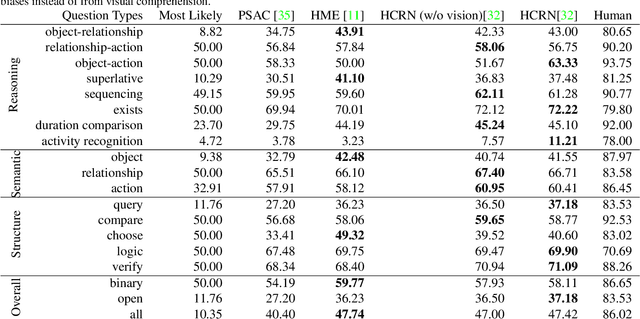
Visual events are a composition of temporal actions involving actors spatially interacting with objects. When developing computer vision models that can reason about compositional spatio-temporal events, we need benchmarks that can analyze progress and uncover shortcomings. Existing video question answering benchmarks are useful, but they often conflate multiple sources of error into one accuracy metric and have strong biases that models can exploit, making it difficult to pinpoint model weaknesses. We present Action Genome Question Answering (AGQA), a new benchmark for compositional spatio-temporal reasoning. AGQA contains $192M$ unbalanced question answer pairs for $9.6K$ videos. We also provide a balanced subset of $3.9M$ question answer pairs, $3$ orders of magnitude larger than existing benchmarks, that minimizes bias by balancing the answer distributions and types of question structures. Although human evaluators marked $86.02\%$ of our question-answer pairs as correct, the best model achieves only $47.74\%$ accuracy. In addition, AGQA introduces multiple training/test splits to test for various reasoning abilities, including generalization to novel compositions, to indirect references, and to more compositional steps. Using AGQA, we evaluate modern visual reasoning systems, demonstrating that the best models barely perform better than non-visual baselines exploiting linguistic biases and that none of the existing models generalize to novel compositions unseen during training.