 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Performance of Radiology Report De-identification with Large-Scale Training and Benchmarking Against Cloud Vendor Methods
Nov 06, 2025


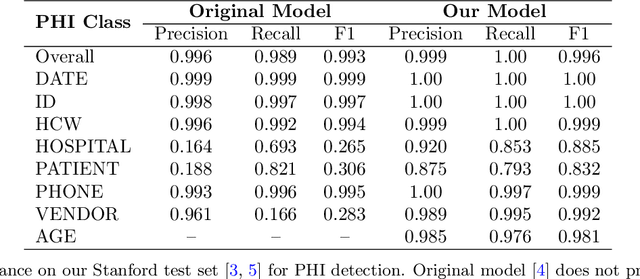
Objective: To enhance automated de-identification of radiology reports by scaling transformer-based models through extensive training datasets and benchmarking performance against commercial cloud vendor systems for protected health information (PHI) detection. Materials and Methods: In this retrospective study, we built upon a state-of-the-art, transformer-based, PHI de-identification pipeline by fine-tuning on two large annotated radiology corpora from Stanford University, encompassing chest X-ray, chest CT, abdomen/pelvis CT, and brain MR reports and introducing an additional PHI category (AGE) into the architecture. Model performance was evaluated on test sets from Stanford and the University of Pennsylvania (Penn) for token-level PHI detection. We further assessed (1) the stability of synthetic PHI generation using a "hide-in-plain-sight" method and (2) performance against commercial systems. Precision, recall, and F1 scores were computed across all PHI categories. Results: Our model achieved overall F1 scores of 0.973 on the Penn dataset and 0.996 on the Stanford dataset, outperforming or maintaining the previous state-of-the-art model performance. Synthetic PHI evaluation showed consistent detectability (overall F1: 0.959 [0.958-0.960]) across 50 independently de-identified Penn datasets. Our model outperformed all vendor systems on synthetic Penn reports (overall F1: 0.960 vs. 0.632-0.754). Discussion: Large-scale, multimodal training improved cross-institutional generalization and robustness. Synthetic PHI generation preserved data utility while ensuring privacy. Conclusion: A transformer-based de-identification model trained on diverse radiology datasets outperforms prior academic and commercial systems in PHI detection and establishes a new benchmark for secure clinical text processing.
Cost and Reward Infused Metric Elicitation
Jan 01, 2025



In machine learning, metric elicitation refers to the selection of performance metrics that best reflect an individual's implicit preferences for a given application. Currently, metric elicitation methods only consider metrics that depend on the accuracy values encoded within a given model's confusion matrix. However, focusing solely on confusion matrices does not account for other model feasibility considerations such as varied monetary costs or latencies. In our work, we build upon the multiclass metric elicitation framework of Hiranandani et al., extrapolating their proposed Diagonal Linear Performance Metric Elicitation (DLPME) algorithm to account for additional bounded costs and rewards. Our experimental results with synthetic data demonstrate our approach's ability to quickly converge to the true metric.
Evaluating and Improving the Effectiveness of Synthetic Chest X-Rays for Medical Image Analysis
Nov 27, 2024Purpose: To explore best-practice approaches for generating synthetic chest X-ray images and augmenting medical imaging datasets to optimize the performance of deep learning models in downstream tasks like classification and segmentation. Materials and Methods: We utilized a latent diffusion model to condition the generation of synthetic chest X-rays on text prompts and/or segmentation masks. We explored methods like using a proxy model and using radiologist feedback to improve the quality of synthetic data. These synthetic images were then generated from relevant disease information or geometrically transformed segmentation masks and added to ground truth training set images from the CheXpert, CANDID-PTX, SIIM, and RSNA Pneumonia datasets to measure improvements in classification and segmentation model performance on the test sets. F1 and Dice scores were used to evaluate classification and segmentation respectively. One-tailed t-tests with Bonferroni correction assessed the statistical significance of performance improvements with synthetic data. Results: Across all experiments, the synthetic data we generated resulted in a maximum mean classification F1 score improvement of 0.150453 (CI: 0.099108-0.201798; P=0.0031) compared to using only real data. For segmentation, the maximum Dice score improvement was 0.14575 (CI: 0.108267-0.183233; P=0.0064). Conclusion: Best practices for generating synthetic chest X-ray images for downstream tasks include conditioning on single-disease labels or geometrically transformed segmentation masks, as well as potentially using proxy modeling for fine-tuning such generations.
Auto-Generating Weak Labels for Real & Synthetic Data to Improve Label-Scarce Medical Image Segmentation
Apr 25, 2024



The high cost of creating pixel-by-pixel gold-standard labels, limited expert availability, and presence of diverse tasks make it challenging to generate segmentation labels to train deep learning models for medical imaging tasks. In this work, we present a new approach to overcome the hurdle of costly medical image labeling by leveraging foundation models like Segment Anything Model (SAM) and its medical alternate MedSAM. Our pipeline has the ability to generate weak labels for any unlabeled medical image and subsequently use it to augment label-scarce datasets. We perform this by leveraging a model trained on a few gold-standard labels and using it to intelligently prompt MedSAM for weak label generation. This automation eliminates the manual prompting step in MedSAM, creating a streamlined process for generating labels for both real and synthetic images, regardless of quantity. We conduct experiments on label-scarce settings for multiple tasks pertaining to modalities ranging from ultrasound, dermatology, and X-rays to demonstrate the usefulness of our pipeline. The code is available at https://github.com/stanfordmlgroup/Auto-Generate-WLs/.
Measuring Compositional Consistency for Video Question Answering
Apr 14, 2022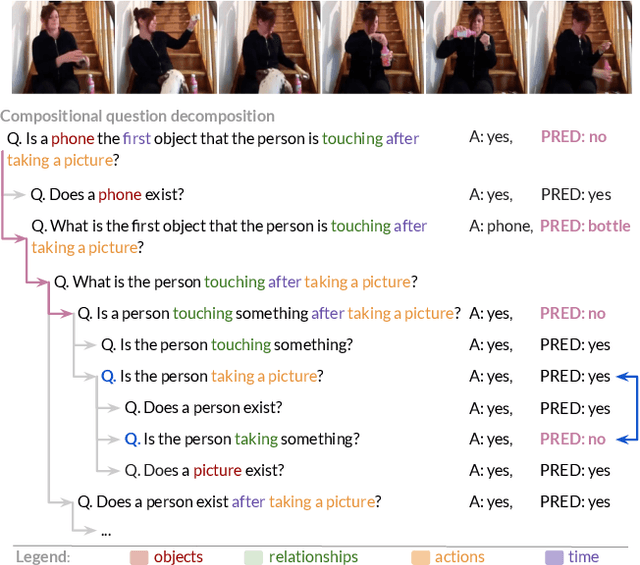
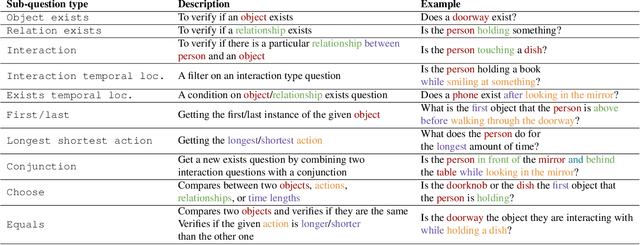
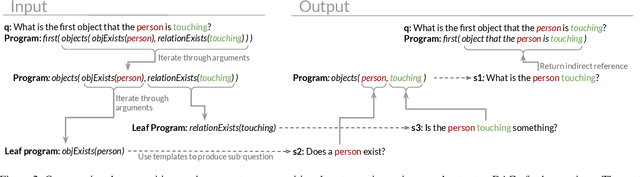
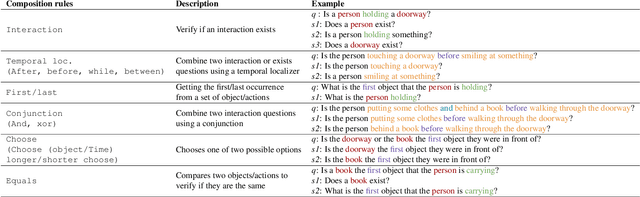
Recent video question answering benchmarks indicate that state-of-the-art models struggle to answer compositional questions. However, it remains unclear which types of compositional reasoning cause models to mispredict. Furthermore, it is difficult to discern whether models arrive at answers using compositional reasoning or by leveraging data biases. In this paper, we develop a question decomposition engine that programmatically deconstructs a compositional question into a directed acyclic graph of sub-questions. The graph is designed such that each parent question is a composition of its children. We present AGQA-Decomp, a benchmark containing $2.3M$ question graphs, with an average of $11.49$ sub-questions per graph, and $4.55M$ total new sub-questions. Using question graphs, we evaluate three state-of-the-art models with a suite of novel compositional consistency metrics. We find that models either cannot reason correctly through most compositions or are reliant on incorrect reasoning to reach answers, frequently contradicting themselves or achieving high accuracies when failing at intermediate reasoning steps.
* To appear in CVPR 2022. 23 pages, 12 figures and 12 tables