 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Large Language Models Consistent over Value-laden Questions?
Jul 03, 2024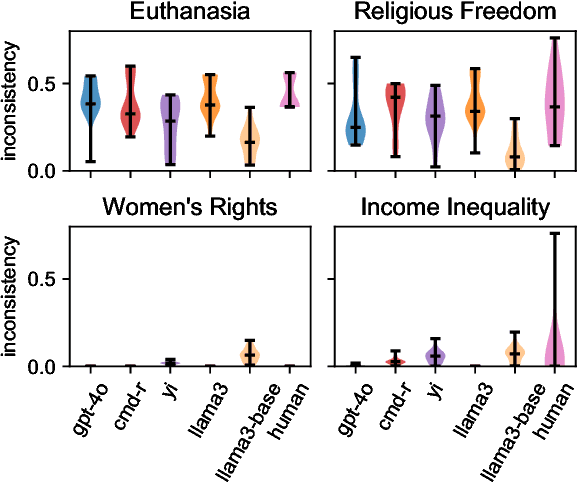


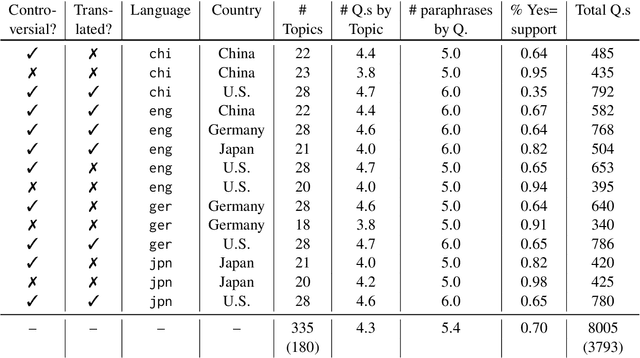
Large language models (LLMs) appear to bias their survey answers toward certain values. Nonetheless, some argue that LLMs are too inconsistent to simulate particular values. Are they? To answer, we first define value consistency as the similarity of answers across (1) paraphrases of one question, (2) related questions under one topic, (3) multiple-choice and open-ended use-cases of one question, and (4) multilingual translations of a question to English, Chinese, German, and Japanese. We apply these measures to a few large ($>=34b$), open LLMs including llama-3, as well as gpt-4o, using eight thousand questions spanning more than 300 topics. Unlike prior work, we find that models are relatively consistent across paraphrases, use-cases, translations, and within a topic. Still, some inconsistencies remain. Models are more consistent on uncontroversial topics (e.g., in the U.S., "Thanksgiving") than on controversial ones ("euthanasia"). Base models are both more consistent compared to fine-tuned models and are uniform in their consistency across topics, while fine-tuned models are more inconsistent about some topics ("euthanasia") than others ("women's rights") like our human subjects (n=165).
Auto-Generating Weak Labels for Real & Synthetic Data to Improve Label-Scarce Medical Image Segmentation
Apr 25, 2024



The high cost of creating pixel-by-pixel gold-standard labels, limited expert availability, and presence of diverse tasks make it challenging to generate segmentation labels to train deep learning models for medical imaging tasks. In this work, we present a new approach to overcome the hurdle of costly medical image labeling by leveraging foundation models like Segment Anything Model (SAM) and its medical alternate MedSAM. Our pipeline has the ability to generate weak labels for any unlabeled medical image and subsequently use it to augment label-scarce datasets. We perform this by leveraging a model trained on a few gold-standard labels and using it to intelligently prompt MedSAM for weak label generation. This automation eliminates the manual prompting step in MedSAM, creating a streamlined process for generating labels for both real and synthetic images, regardless of quantity. We conduct experiments on label-scarce settings for multiple tasks pertaining to modalities ranging from ultrasound, dermatology, and X-rays to demonstrate the usefulness of our pipeline. The code is available at https://github.com/stanfordmlgroup/Auto-Generate-WLs/.
An Interpretable Approach to Hateful Meme Detection
Aug 09, 2021
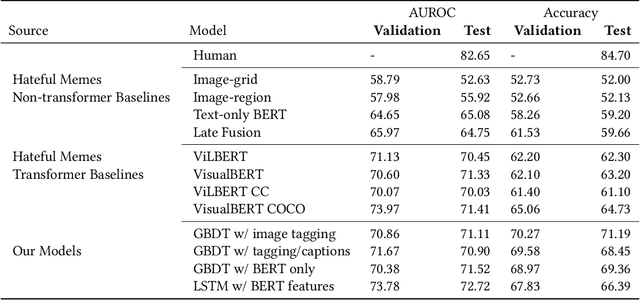

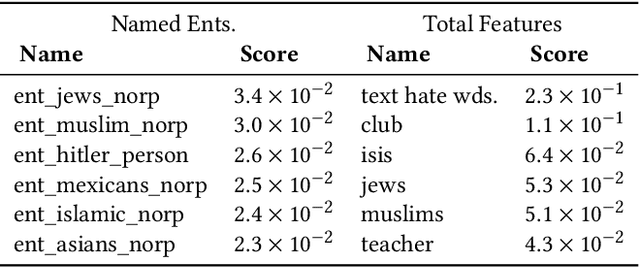
Hateful memes are an emerging method of spreading hate on the internet, relying on both images and text to convey a hateful message. We take an interpretable approach to hateful meme detection, using machine learning and simple heuristics to identify the features most important to classifying a meme as hateful. In the process, we build a gradient-boosted decision tree and an LSTM-based model that achieve comparable performance (73.8 validation and 72.7 test auROC) to the gold standard of humans and state-of-the-art transformer models on this challenging task.