 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Structured Radiology Report Generation
May 30, 2025Automated radiology report generation from chest X-ray (CXR) images has the potential to improve clinical efficiency and reduce radiologists' workload. However, most datasets, including the publicly available MIMIC-CXR and CheXpert Plus, consist entirely of free-form reports, which are inherently variable and unstructured. This variability poses challenges for both generation and evaluation: existing models struggle to produce consistent, clinically meaningful reports, and standard evaluation metrics fail to capture the nuances of radiological interpretation. To address this, we introduce Structured Radiology Report Generation (SRRG), a new task that reformulates free-text radiology reports into a standardized format, ensuring clarity, consistency, and structured clinical reporting. We create a novel dataset by restructuring reports using large language models (LLMs) following strict structured reporting desiderata. Additionally, we introduce SRR-BERT, a fine-grained disease classification model trained on 55 labels, enabling more precise and clinically informed evaluation of structured reports. To assess report quality, we propose F1-SRR-BERT, a metric that leverages SRR-BERT's hierarchical disease taxonomy to bridge the gap between free-text variability and structured clinical reporting. We validate our dataset through a reader study conducted by five board-certified radiologists and extensive benchmarking experiments.
An Advantage-based Optimization Method for Reinforcement Learning in Large Action Space
Dec 17, 2024
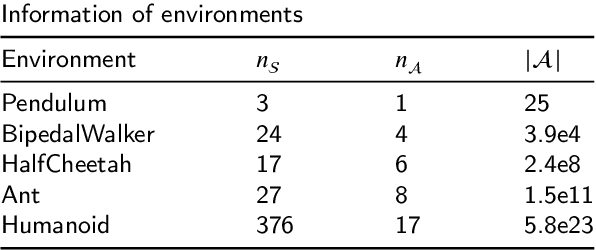
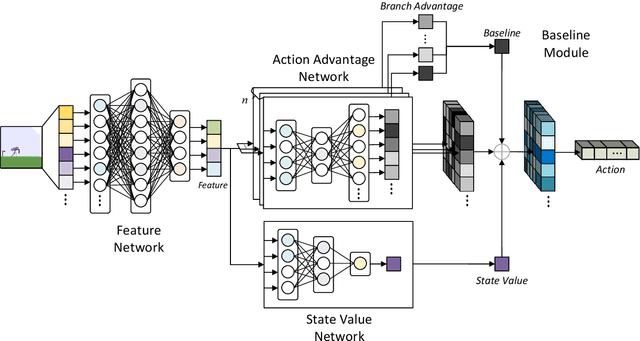
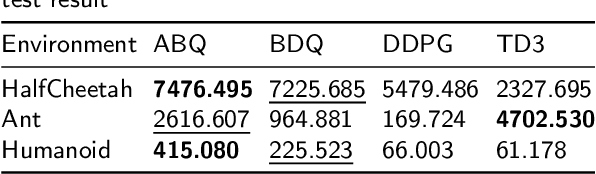
Reinforcement learning tasks in real-world scenarios often involve large, high-dimensional action spaces, leading to challenges such as convergence difficulties, instability, and high computational complexity. It is widely acknowledged that traditional value-based reinforcement learning algorithms struggle to address these issues effectively. A prevalent approach involves generating independent sub-actions within each dimension of the action space. However, this method introduces bias, hindering the learning of optimal policies. In this paper, we propose an advantage-based optimization method and an algorithm named Advantage Branching Dueling Q-network (ABQ). ABQ incorporates a baseline mechanism to tune the action value of each dimension, leveraging the advantage relationship across different sub-actions. With this approach, the learned policy can be optimized for each dimension. Empirical results demonstrate that ABQ outperforms BDQ, achieving 3%, 171%, and 84% more cumulative rewards in HalfCheetah, Ant, and Humanoid environments, respectively. Furthermore, ABQ exhibits competitive performance when compared against two continuous action benchmark algorithms, DDPG and TD3.
Foundation Models in Radiology: What, How, When, Why and Why Not
Nov 27, 2024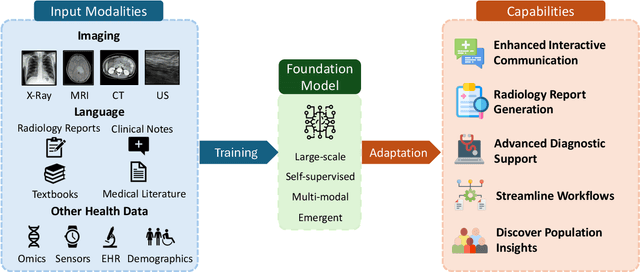
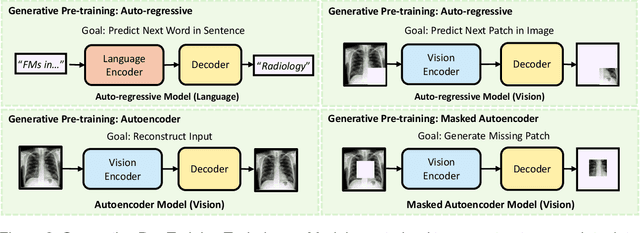
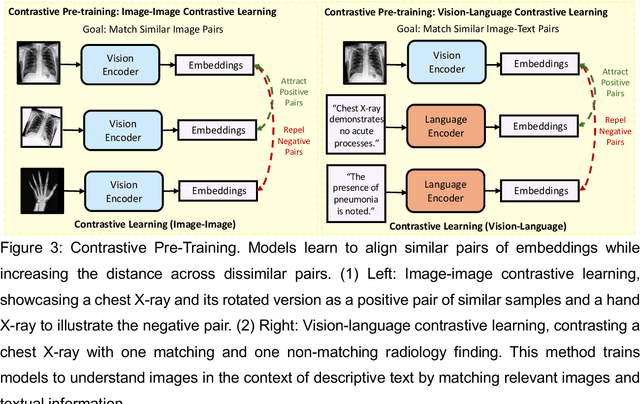
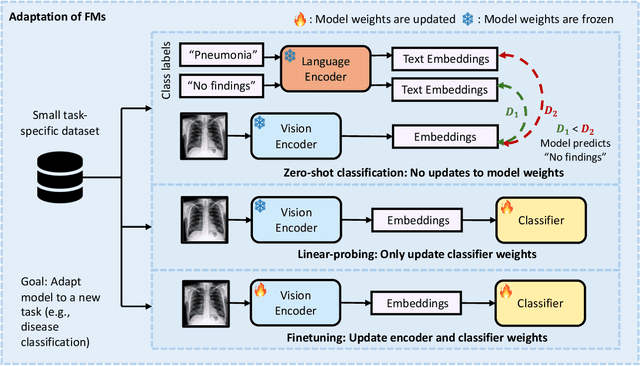
Recent advances in artificial intelligence have witnessed the emergence of large-scale deep learning models capable of interpreting and generating both textual and imaging data. Such models, typically referred to as foundation models, are trained on extensive corpora of unlabeled data and demonstrate high performance across various tasks. Foundation models have recently received extensive attention from academic, industry, and regulatory bodies. Given the potentially transformative impact that foundation models can have on the field of radiology, this review aims to establish a standardized terminology concerning foundation models, with a specific focus on the requirements of training data, model training paradigms, model capabilities, and evaluation strategies. We further outline potential pathways to facilitate the training of radiology-specific foundation models, with a critical emphasis on elucidating both the benefits and challenges associated with such models. Overall, we envision that this review can unify technical advances and clinical needs in the training of foundation models for radiology in a safe and responsible manner, for ultimately benefiting patients, providers, and radiologists.
Evaluating and Improving the Effectiveness of Synthetic Chest X-Rays for Medical Image Analysis
Nov 27, 2024Purpose: To explore best-practice approaches for generating synthetic chest X-ray images and augmenting medical imaging datasets to optimize the performance of deep learning models in downstream tasks like classification and segmentation. Materials and Methods: We utilized a latent diffusion model to condition the generation of synthetic chest X-rays on text prompts and/or segmentation masks. We explored methods like using a proxy model and using radiologist feedback to improve the quality of synthetic data. These synthetic images were then generated from relevant disease information or geometrically transformed segmentation masks and added to ground truth training set images from the CheXpert, CANDID-PTX, SIIM, and RSNA Pneumonia datasets to measure improvements in classification and segmentation model performance on the test sets. F1 and Dice scores were used to evaluate classification and segmentation respectively. One-tailed t-tests with Bonferroni correction assessed the statistical significance of performance improvements with synthetic data. Results: Across all experiments, the synthetic data we generated resulted in a maximum mean classification F1 score improvement of 0.150453 (CI: 0.099108-0.201798; P=0.0031) compared to using only real data. For segmentation, the maximum Dice score improvement was 0.14575 (CI: 0.108267-0.183233; P=0.0064). Conclusion: Best practices for generating synthetic chest X-ray images for downstream tasks include conditioning on single-disease labels or geometrically transformed segmentation masks, as well as potentially using proxy modeling for fine-tuning such generations.
RaVL: Discovering and Mitigating Spurious Correlations in Fine-Tuned Vision-Language Models
Nov 06, 2024



Fine-tuned vision-language models (VLMs) often capture spurious correlations between image features and textual attributes, resulting in degraded zero-shot performance at test time. Existing approaches for addressing spurious correlations (i) primarily operate at the global image-level rather than intervening directly on fine-grained image features and (ii) are predominantly designed for unimodal settings. In this work, we present RaVL, which takes a fine-grained perspective on VLM robustness by discovering and mitigating spurious correlations using local image features rather than operating at the global image level. Given a fine-tuned VLM, RaVL first discovers spurious correlations by leveraging a region-level clustering approach to identify precise image features contributing to zero-shot classification errors. Then, RaVL mitigates the identified spurious correlation with a novel region-aware loss function that enables the VLM to focus on relevant regions and ignore spurious relationships during fine-tuning. We evaluate RaVL on 654 VLMs with various model architectures, data domains, and learned spurious correlations. Our results show that RaVL accurately discovers (191% improvement over the closest baseline) and mitigates (8.2% improvement on worst-group image classification accuracy) spurious correlations. Qualitative evaluations on general-domain and medical-domain VLMs confirm our findings.
Preference Fine-Tuning for Factuality in Chest X-Ray Interpretation Models Without Human Feedback
Oct 09, 2024



Radiologists play a crucial role by translating medical images into medical reports. However, the field faces staffing shortages and increasing workloads. While automated approaches using vision-language models (VLMs) show promise as assistants, they require exceptionally high accuracy. Most current VLMs in radiology rely solely on supervised fine-tuning (SFT). Meanwhile, in the general domain, additional preference fine-tuning has become standard practice. The challenge in radiology lies in the prohibitive cost of obtaining radiologist feedback. We propose a scalable automated preference alignment technique for VLMs in radiology, focusing on chest X-ray (CXR) report generation. Our method leverages publicly available datasets with an LLM-as-a-Judge mechanism, eliminating the need for additional expert radiologist feedback. We evaluate and benchmark five direct alignment algorithms (DAAs). Our results show up to a 57.4% improvement in average GREEN scores, a LLM-based metric for evaluating CXR reports, and a 9.2% increase in an average across six metrics (domain specific and general), compared to the SFT baseline. We study reward overoptimization via length exploitation, with reports lengthening by up to 3.2x. To assess a potential alignment tax, we benchmark on six additional diverse tasks, finding no significant degradations. A reader study involving four board-certified radiologists indicates win rates of up to 0.62 over the SFT baseline, while significantly penalizing verbosity. Our analysis provides actionable insights for the development of VLMs in high-stakes fields like radiology.
Overview of the First Shared Task on Clinical Text Generation: RRG24 and "Discharge Me!"
Sep 25, 2024



Recent developments in natural language generation have tremendous implications for healthcare. For instance, state-of-the-art systems could automate the generation of sections in clinical reports to alleviate physician workload and streamline hospital documentation. To explore these applications, we present a shared task consisting of two subtasks: (1) Radiology Report Generation (RRG24) and (2) Discharge Summary Generation ("Discharge Me!"). RRG24 involves generating the 'Findings' and 'Impression' sections of radiology reports given chest X-rays. "Discharge Me!" involves generating the 'Brief Hospital Course' and 'Discharge Instructions' sections of discharge summaries for patients admitted through the emergency department. "Discharge Me!" submissions were subsequently reviewed by a team of clinicians. Both tasks emphasize the goal of reducing clinician burnout and repetitive workloads by generating documentation. We received 201 submissions from across 8 teams for RRG24, and 211 submissions from across 16 teams for "Discharge Me!".
* ACL Proceedings. BioNLP workshop
Merlin: A Vision Language Foundation Model for 3D Computed Tomography
Jun 10, 2024



Over 85 million computed tomography (CT) scans are performed annually in the US, of which approximately one quarter focus on the abdomen. Given the current radiologist shortage, there is a large impetus to use artificial intelligence to alleviate the burden of interpreting these complex imaging studies. Prior state-of-the-art approaches for automated medical image interpretation leverage vision language models (VLMs). However, current medical VLMs are generally limited to 2D images and short reports, and do not leverage electronic health record (EHR) data for supervision. We introduce Merlin - a 3D VLM that we train using paired CT scans (6+ million images from 15,331 CTs), EHR diagnosis codes (1.8+ million codes), and radiology reports (6+ million tokens). We evaluate Merlin on 6 task types and 752 individual tasks. The non-adapted (off-the-shelf) tasks include zero-shot findings classification (31 findings), phenotype classification (692 phenotypes), and zero-shot cross-modal retrieval (image to findings and image to impressions), while model adapted tasks include 5-year disease prediction (6 diseases), radiology report generation, and 3D semantic segmentation (20 organs). We perform internal validation on a test set of 5,137 CTs, and external validation on 7,000 clinical CTs and on two public CT datasets (VerSe, TotalSegmentator). Beyond these clinically-relevant evaluations, we assess the efficacy of various network architectures and training strategies to depict that Merlin has favorable performance to existing task-specific baselines. We derive data scaling laws to empirically assess training data needs for requisite downstream task performance. Furthermore, unlike conventional VLMs that require hundreds of GPUs for training, we perform all training on a single GPU.
CheXpert Plus: Augmenting a Large Chest X-ray Dataset with Text Radiology Reports, Patient Demographics and Additional Image Formats
Jun 03, 2024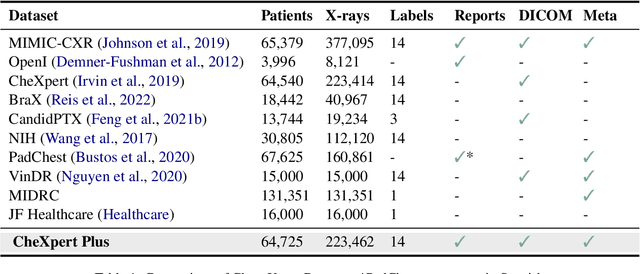

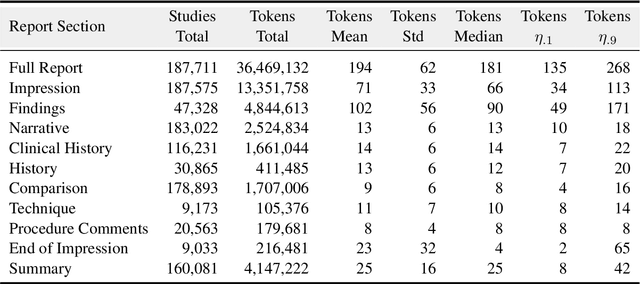
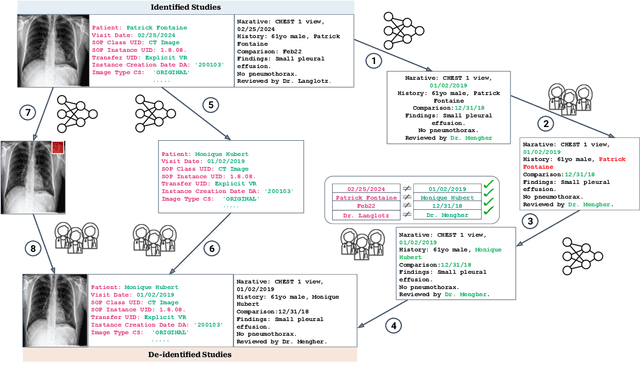
Since the release of the original CheXpert paper five years ago, CheXpert has become one of the most widely used and cited clinical AI datasets. The emergence of vision language models has sparked an increase in demands for sharing reports linked to CheXpert images, along with a growing interest among AI fairness researchers in obtaining demographic data. To address this, CheXpert Plus serves as a new collection of radiology data sources, made publicly available to enhance the scaling, performance, robustness, and fairness of models for all subsequent machine learning tasks in the field of radiology. CheXpert Plus is the largest text dataset publicly released in radiology, with a total of 36 million text tokens, including 13 million impression tokens. To the best of our knowledge, it represents the largest text de-identification effort in radiology, with almost 1 million PHI spans anonymized. It is only the second time that a large-scale English paired dataset has been released in radiology, thereby enabling, for the first time, cross-institution training at scale. All reports are paired with high-quality images in DICOM format, along with numerous image and patient metadata covering various clinical and socio-economic groups, as well as many pathology labels and RadGraph annotations. We hope this dataset will boost research for AI models that can further assist radiologists and help improve medical care. Data is available at the following URL: https://stanfordaimi.azurewebsites.net/datasets/5158c524-d3ab-4e02-96e9-6ee9efc110a1 Models are available at the following URL: https://github.com/Stanford-AIMI/chexpert-plus
GREEN: Generative Radiology Report Evaluation and Error Notation
May 06, 2024
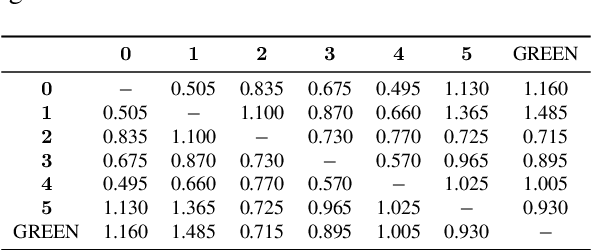


Evaluating radiology reports is a challenging problem as factual correctness is extremely important due to the need for accurate medical communication about medical images. Existing automatic evaluation metrics either suffer from failing to consider factual correctness (e.g., BLEU and ROUGE) or are limited in their interpretability (e.g., F1CheXpert and F1RadGraph). In this paper, we introduce GREEN (Generative Radiology Report Evaluation and Error Notation), a radiology report generation metric that leverages the natural language understanding of language models to identify and explain clinically significant errors in candidate reports, both quantitatively and qualitatively. Compared to current metrics, GREEN offers: 1) a score aligned with expert preferences, 2) human interpretable explanations of clinically significant errors, enabling feedback loops with end-users, and 3) a lightweight open-source method that reaches the performance of commercial counterparts. We validate our GREEN metric by comparing it to GPT-4, as well as to error counts of 6 experts and preferences of 2 experts. Our method demonstrates not only higher correlation with expert error counts, but simultaneously higher alignment with expert preferences when compared to previous approaches."