 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperhuman performance of a large language model on the reasoning tasks of a physician
Dec 14, 2024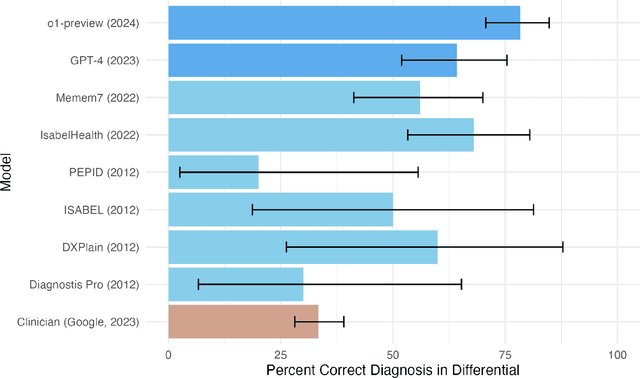
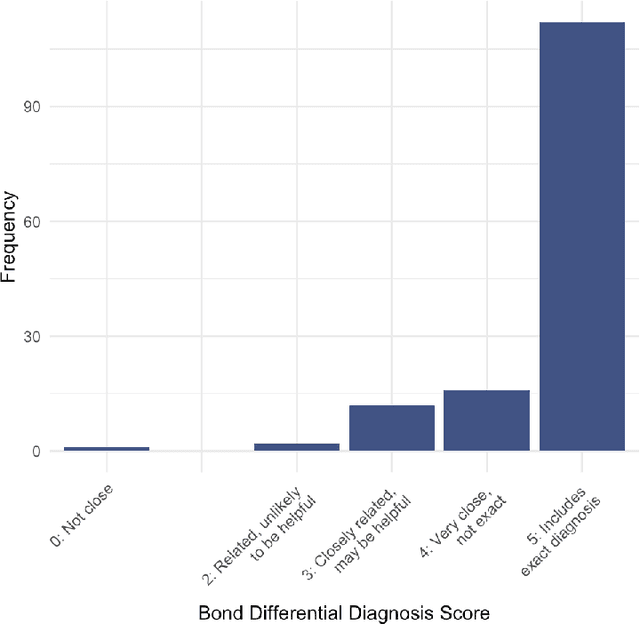

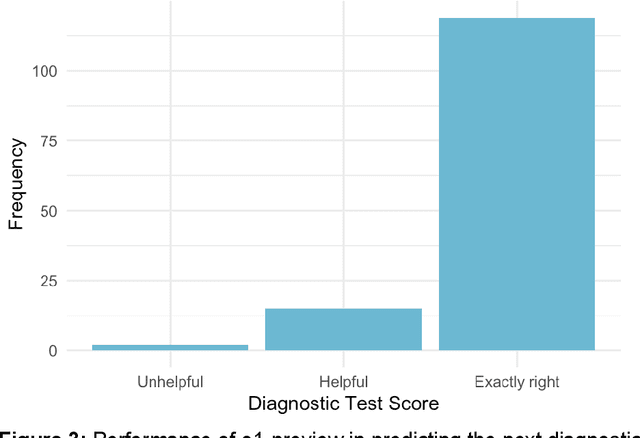
Performance of large language models (LLMs) on medical tasks has traditionally been evaluated using multiple choice question benchmarks. However, such benchmarks are highly constrained, saturated with repeated impressive performance by LLMs, and have an unclear relationship to performance in real clinical scenarios. Clinical reasoning, the process by which physicians employ critical thinking to gather and synthesize clinical data to diagnose and manage medical problems, remains an attractive benchmark for model performance. Prior LLMs have shown promise in outperforming clinicians in routine and complex diagnostic scenarios. We sought to evaluate OpenAI's o1-preview model, a model developed to increase run-time via chain of thought processes prior to generating a response. We characterize the performance of o1-preview with five experiments including differential diagnosis generation, display of diagnostic reasoning, triage differential diagnosis, probabilistic reasoning, and management reasoning, adjudicated by physician experts with validated psychometrics. Our primary outcome was comparison of the o1-preview output to identical prior experiments that have historical human controls and benchmarks of previous LLMs. Significant improvements were observed with differential diagnosis generation and quality of diagnostic and management reasoning. No improvements were observed with probabilistic reasoning or triage differential diagnosis. This study highlights o1-preview's ability to perform strongly on tasks that require complex critical thinking such as diagnosis and management while its performance on probabilistic reasoning tasks was similar to past models. New robust benchmarks and scalable evaluation of LLM capabilities compared to human physicians are needed along with trials evaluating AI in real clinical settings.
Overview of the First Shared Task on Clinical Text Generation: RRG24 and "Discharge Me!"
Sep 25, 2024



Recent developments in natural language generation have tremendous implications for healthcare. For instance, state-of-the-art systems could automate the generation of sections in clinical reports to alleviate physician workload and streamline hospital documentation. To explore these applications, we present a shared task consisting of two subtasks: (1) Radiology Report Generation (RRG24) and (2) Discharge Summary Generation ("Discharge Me!"). RRG24 involves generating the 'Findings' and 'Impression' sections of radiology reports given chest X-rays. "Discharge Me!" involves generating the 'Brief Hospital Course' and 'Discharge Instructions' sections of discharge summaries for patients admitted through the emergency department. "Discharge Me!" submissions were subsequently reviewed by a team of clinicians. Both tasks emphasize the goal of reducing clinician burnout and repetitive workloads by generating documentation. We received 201 submissions from across 8 teams for RRG24, and 211 submissions from across 16 teams for "Discharge Me!".
* ACL Proceedings. BioNLP workshop
Detecting Underdiagnosed Medical Conditions with Deep Learning-Based Opportunistic CT Imaging
Sep 18, 2024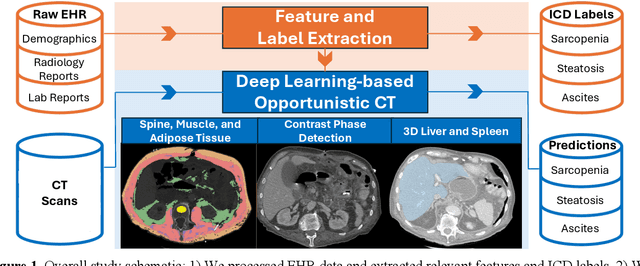
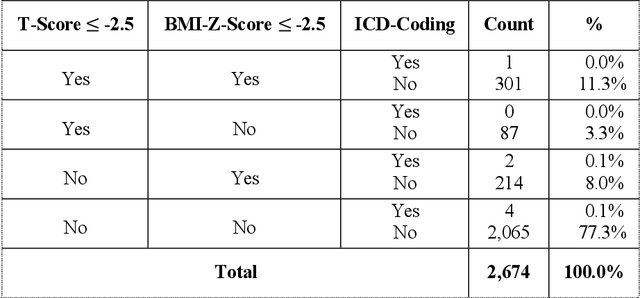
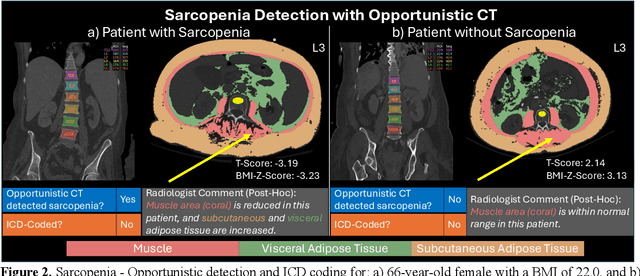
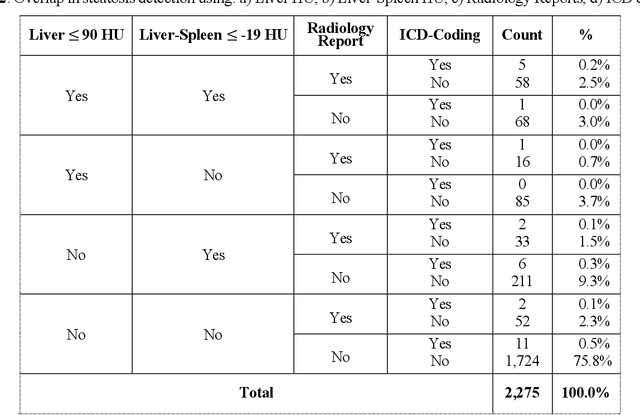
Abdominal computed tomography (CT) scans are frequently performed in clinical settings. Opportunistic CT involves repurposing routine CT images to extract diagnostic information and is an emerging tool for detecting underdiagnosed conditions such as sarcopenia, hepatic steatosis, and ascites. This study utilizes deep learning methods to promote accurate diagnosis and clinical documentation. We analyze 2,674 inpatient CT scans to identify discrepancies between imaging phenotypes (characteristics derived from opportunistic CT scans) and their corresponding documentation in radiology reports and ICD coding. Through our analysis, we find that only 0.5%, 3.2%, and 30.7% of scans diagnosed with sarcopenia, hepatic steatosis, and ascites (respectively) through either opportunistic imaging or radiology reports were ICD-coded. Our findings demonstrate opportunistic CT's potential to enhance diagnostic precision and accuracy of risk adjustment models, offering advancements in precision medicine.
Merlin: A Vision Language Foundation Model for 3D Computed Tomography
Jun 10, 2024



Over 85 million computed tomography (CT) scans are performed annually in the US, of which approximately one quarter focus on the abdomen. Given the current radiologist shortage, there is a large impetus to use artificial intelligence to alleviate the burden of interpreting these complex imaging studies. Prior state-of-the-art approaches for automated medical image interpretation leverage vision language models (VLMs). However, current medical VLMs are generally limited to 2D images and short reports, and do not leverage electronic health record (EHR) data for supervision. We introduce Merlin - a 3D VLM that we train using paired CT scans (6+ million images from 15,331 CTs), EHR diagnosis codes (1.8+ million codes), and radiology reports (6+ million tokens). We evaluate Merlin on 6 task types and 752 individual tasks. The non-adapted (off-the-shelf) tasks include zero-shot findings classification (31 findings), phenotype classification (692 phenotypes), and zero-shot cross-modal retrieval (image to findings and image to impressions), while model adapted tasks include 5-year disease prediction (6 diseases), radiology report generation, and 3D semantic segmentation (20 organs). We perform internal validation on a test set of 5,137 CTs, and external validation on 7,000 clinical CTs and on two public CT datasets (VerSe, TotalSegmentator). Beyond these clinically-relevant evaluations, we assess the efficacy of various network architectures and training strategies to depict that Merlin has favorable performance to existing task-specific baselines. We derive data scaling laws to empirically assess training data needs for requisite downstream task performance. Furthermore, unlike conventional VLMs that require hundreds of GPUs for training, we perform all training on a single GPU.
A Benchmark of Domain-Adapted Large Language Models for Generating Brief Hospital Course Summaries
Mar 08, 2024



Brief hospital course (BHC) summaries are common clinical documents generated by summarizing clinical notes. While large language models (LLMs) depict remarkable capabilities in automating real-world tasks, their capabilities for healthcare applications such as BHC synthesis have not been shown. To enable the adaptation of LLMs for BHC synthesis, we introduce a novel benchmark consisting of a pre-processed dataset extracted from MIMIC-IV notes, encapsulating clinical note, and brief hospital course (BHC) pairs. We assess the performance of two general-purpose LLMs and three healthcare-adapted LLMs to improve BHC synthesis from clinical notes. Using clinical notes as input for generating BHCs, we apply prompting-based (using in-context learning) and fine-tuning-based adaptation strategies to three open-source LLMs (Clinical-T5-Large, Llama2-13B, FLAN-UL2) and two proprietary LLMs (GPT-3.5, GPT-4). We quantitatively evaluate the performance of these LLMs across varying context-length inputs using conventional natural language similarity metrics. We further perform a qualitative study where five diverse clinicians blindly compare clinician-written BHCs and two LLM-generated BHCs for 30 samples across metrics of comprehensiveness, conciseness, factual correctness, and fluency. Overall, we present a new benchmark and pre-processed dataset for using LLMs in BHC synthesis from clinical notes. We observe high-quality summarization performance for both in-context proprietary and fine-tuned open-source LLMs using both quantitative metrics and a qualitative clinical reader study. We propose our work as a benchmark to motivate future works to adapt and assess the performance of LLMs in BHC synthesis.
Clinical Text Summarization: Adapting Large Language Models Can Outperform Human Experts
Sep 14, 2023Sifting through vast textual data and summarizing key information imposes a substantial burden on how clinicians allocate their time. Although large language models (LLMs) have shown immense promise in natural language processing (NLP) tasks, their efficacy across diverse clinical summarization tasks has not yet been rigorously examined. In this work, we employ domain adaptation methods on eight LLMs, spanning six datasets and four distinct summarization tasks: radiology reports, patient questions, progress notes, and doctor-patient dialogue. Our thorough quantitative assessment reveals trade-offs between models and adaptation methods in addition to instances where recent advances in LLMs may not lead to improved results. Further, in a clinical reader study with six physicians, we depict that summaries from the best adapted LLM are preferable to human summaries in terms of completeness and correctness. Our ensuing qualitative analysis delineates mutual challenges faced by both LLMs and human experts. Lastly, we correlate traditional quantitative NLP metrics with reader study scores to enhance our understanding of how these metrics align with physician preferences. Our research marks the first evidence of LLMs outperforming human experts in clinical text summarization across multiple tasks. This implies that integrating LLMs into clinical workflows could alleviate documentation burden, empowering clinicians to focus more on personalized patient care and other irreplaceable human aspects of medicine.