 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheXmix: Unified Generative Pretraining for Vision Language Models in Medical Imaging
Apr 24, 2026Recent medical multimodal foundation models are built as multimodal LLMs (MLLMs) by connecting a CLIP-pretrained vision encoder to an LLM using LLaVA-style finetuning. This two-stage, decoupled approach introduces a projection layer that can distort visual features. This is especially concerning in medical imaging where subtle cues are essential for accurate diagnoses. In contrast, early-fusion generative approaches such as Chameleon eliminate the projection bottleneck by processing image and text tokens within a single unified sequence, enabling joint representation learning that leverages the inductive priors of language models. We present CheXmix, a unified early-fusion generative model trained on a large corpus of chest X-rays paired with radiology reports. We expand on Chameleon's autoregressive framework by introducing a two-stage multimodal generative pretraining strategy that combines the representational strengths of masked autoencoders with MLLMs. The resulting models are highly flexible, supporting both discriminative and generative tasks at both coarse and fine-grained scales. Our approach outperforms well-established generative models across all masking ratios by 6.0% and surpasses CheXagent by 8.6% on AUROC at high image masking ratios on the CheXpert classification task. We further inpaint images over 51.0% better than text-only generative models and outperform CheXagent by 45% on the GREEN metric for radiology report generation. These results demonstrate that CheXmix captures fine-grained information across a broad spectrum of chest X-ray tasks. Our code is at: https://github.com/StanfordMIMI/CheXmix.
A Reasoning-Enabled Vision-Language Foundation Model for Chest X-ray Interpretation
Apr 01, 2026Chest X-rays (CXRs) are among the most frequently performed imaging examinations worldwide, yet rising imaging volumes increase radiologist workload and the risk of diagnostic errors. Although artificial intelligence (AI) systems have shown promise for CXR interpretation, most generate only final predictions, without making explicit how visual evidence is translated into radiographic findings and diagnostic predictions. We present CheXOne, a reasoning-enabled vision-language model for CXR interpretation. CheXOne jointly generates diagnostic predictions and explicit, clinically grounded reasoning traces that connect visual evidence, radiographic findings, and these predictions. The model is trained on 14.7 million instruction and reasoning samples curated from 30 public datasets spanning 36 CXR interpretation tasks, using a two-stage framework that combines instruction tuning with reinforcement learning to improve reasoning quality. We evaluate CheXOne in zero-shot settings across visual question answering, report generation, visual grounding and reasoning assessment, covering 17 evaluation settings. CheXOne outperforms existing medical and general-domain foundation models and achieves strong performance on independent public benchmarks. A clinical reader study demonstrates that CheXOne-drafted reports are comparable to or better than resident-written reports in 55% of cases, while effectively addressing clinical indications and enhancing both report writing and CXR interpretation efficiency. Further analyses involving radiologists reveal that the generated reasoning traces show high clinical factuality and provide causal support for the final predictions, offering a plausible explanation for the performance gains. These results suggest that explicit reasoning can improve model performance, interpretability and clinical utility in AI-assisted CXR interpretation.
Activation Matters: Test-time Activated Negative Labels for OOD Detection with Vision-Language Models
Mar 26, 2026Out-of-distribution (OOD) detection aims to identify samples that deviate from in-distribution (ID). One popular pipeline addresses this by introducing negative labels distant from ID classes and detecting OOD based on their distance to these labels. However, such labels may present poor activation on OOD samples, failing to capture the OOD characteristics. To address this, we propose \underline{T}est-time \underline{A}ctivated \underline{N}egative \underline{L}abels (TANL) by dynamically evaluating activation levels across the corpus dataset and mining candidate labels with high activation responses during the testing process. Specifically, TANL identifies high-confidence test images online and accumulates their assignment probabilities over the corpus to construct a label activation metric. Such a metric leverages historical test samples to adaptively align with the test distribution, enabling the selection of distribution-adaptive activated negative labels. By further exploring the activation information within the current testing batch, we introduce a more fine-grained, batch-adaptive variant. To fully utilize label activation knowledge, we propose an activation-aware score function that emphasizes negative labels with stronger activations, boosting performance and enhancing its robustness to the label number. Our TANL is training-free, test-efficient, and grounded in theoretical justification. Experiments on diverse backbones and wide task settings validate its effectiveness. Notably, on the large-scale ImageNet benchmark, TANL significantly reduces the FPR95 from 17.5\% to 9.8\%. Codes are available at \href{https://github.com/YBZh/OpenOOD-VLM}{YBZh/OpenOOD-VLM}.
Learning Generalizable 3D Medical Image Representations from Mask-Guided Self-Supervision
Mar 14, 2026Foundation models have transformed vision and language by learning general-purpose representations from large-scale unlabeled data, yet 3D medical imaging lacks analogous approaches. Existing self-supervised methods rely on low-level reconstruction or contrastive objectives that fail to capture the anatomical semantics critical for medical image analysis, limiting transfer to downstream tasks. We present MASS (MAsk-guided Self-Supervised learning), which treats in-context segmentation as the pretext task for learning general-purpose medical imaging representations. MASS's key insight is that automatically generated class-agnostic masks provide sufficient structural supervision for learning semantically rich representations. By training on thousands of diverse mask proposals spanning anatomical structures and pathological findings, MASS learns what semantically defines medical structures: the holistic combination of appearance, shape, spatial context, and anatomical relationships. We demonstrate effectiveness across data regimes: from small-scale pretraining on individual datasets (20-200 scans) to large-scale multi-modal pretraining on 5K CT, MRI, and PET volumes, all without annotations. MASS demonstrates: (i) few-shot segmentation on novel structures, (ii) matching full supervision with only 20-40\% labeled data while outperforming self-supervised baselines by over 20 in Dice score in low-data regimes, and (iii) frozen-encoder classification on unseen pathologies that matches full supervised training with thousands of samples. Mask-guided self-supervised pretraining captures broadly generalizable knowledge, opening a path toward 3D medical imaging foundation models without expert annotations. Code is available: https://github.com/Stanford-AIMI/MASS.
A data- and compute-efficient chest X-ray foundation model beyond aggressive scaling
Feb 26, 2026Foundation models for medical imaging are typically pretrained on increasingly large datasets, following a "scale-at-all-costs" paradigm. However, this strategy faces two critical challenges: large-scale medical datasets often contain substantial redundancy and severe class imbalance that bias representation learning toward over-represented patterns, and indiscriminate training regardless of heterogeneity in data quality incurs considerable computational inefficiency. Here we demonstrate that active, principled data curation during pretraining can serve as a viable, cost-effective alternative to brute-force dataset enlargement. We introduce CheXficient, a chest X-ray (CXR) foundation model that selectively prioritizes informative training samples. CheXficient is pretrained on only 22.7% of 1,235,004 paired CXR images and reports while consuming under 27.3% of the total compute budget, yet achieving comparable or superior performance to its full-data counterpart and other large-scale pretrained models. We assess CheXficient across 20 individual benchmarks spanning 5 task types, including non-adapted off-the-shelf evaluations (zero-shot findings classification and crossmodal retrieval) and adapted downstream tasks (disease prediction, semantic segmentation, and radiology report generation). Further analyses show that CheXficient systematically prioritizes under-represented training samples, improving generalizability on long-tailed or rare conditions. Overall, our work offers practical insights into the data and computation demands for efficient pretraining and downstream adaptation of medical vision-language foundation models.
Attention Head Entropy of LLMs Predicts Answer Correctness
Feb 14, 2026Large language models (LLMs) often generate plausible yet incorrect answers, posing risks in safety-critical settings such as medicine. Human evaluation is expensive, and LLM-as-judge approaches risk introducing hidden errors. Recent white-box methods detect contextual hallucinations using model internals, focusing on the localization of the attention mass, but two questions remain open: do these approaches extend to predicting answer correctness, and do they generalize out-of-domains? We introduce Head Entropy, a method that predicts answer correctness from attention entropy patterns, specifically measuring the spread of the attention mass. Using sparse logistic regression on per-head 2-Renyi entropies, Head Entropy matches or exceeds baselines in-distribution and generalizes substantially better on out-of-domains, it outperforms the closest baseline on average by +8.5% AUROC. We further show that attention patterns over the question/context alone, before answer generation, already carry predictive signal using Head Entropy with on average +17.7% AUROC over the closest baseline. We evaluate across 5 instruction-tuned LLMs and 3 QA datasets spanning general knowledge, multi-hop reasoning, and medicine.
RadDiff: Describing Differences in Radiology Image Sets with Natural Language
Jan 07, 2026Understanding how two radiology image sets differ is critical for generating clinical insights and for interpreting medical AI systems. We introduce RadDiff, a multimodal agentic system that performs radiologist-style comparative reasoning to describe clinically meaningful differences between paired radiology studies. RadDiff builds on a proposer-ranker framework from VisDiff, and incorporates four innovations inspired by real diagnostic workflows: (1) medical knowledge injection through domain-adapted vision-language models; (2) multimodal reasoning that integrates images with their clinical reports; (3) iterative hypothesis refinement across multiple reasoning rounds; and (4) targeted visual search that localizes and zooms in on salient regions to capture subtle findings. To evaluate RadDiff, we construct RadDiffBench, a challenging benchmark comprising 57 expert-validated radiology study pairs with ground-truth difference descriptions. On RadDiffBench, RadDiff achieves 47% accuracy, and 50% accuracy when guided by ground-truth reports, significantly outperforming the general-domain VisDiff baseline. We further demonstrate RadDiff's versatility across diverse clinical tasks, including COVID-19 phenotype comparison, racial subgroup analysis, and discovery of survival-related imaging features. Together, RadDiff and RadDiffBench provide the first method-and-benchmark foundation for systematically uncovering meaningful differences in radiological data.
SMMILE: An Expert-Driven Benchmark for Multimodal Medical In-Context Learning
Jun 26, 2025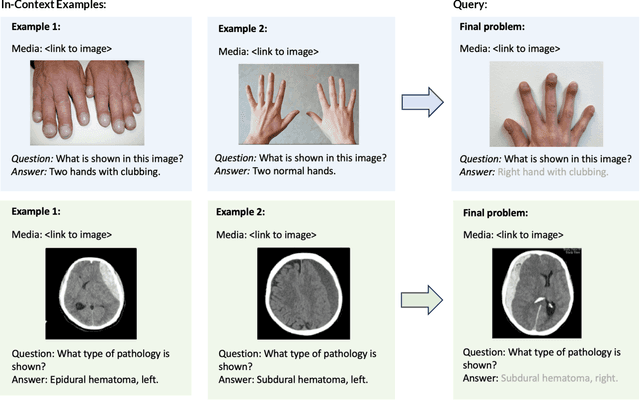



Multimodal in-context learning (ICL) remains underexplored despite significant potential for domains such as medicine. Clinicians routinely encounter diverse, specialized tasks requiring adaptation from limited examples, such as drawing insights from a few relevant prior cases or considering a constrained set of differential diagnoses. While multimodal large language models (MLLMs) have shown advances in medical visual question answering (VQA), their ability to learn multimodal tasks from context is largely unknown. We introduce SMMILE, the first expert-driven multimodal ICL benchmark for medical tasks. Eleven medical experts curated problems, each including a multimodal query and multimodal in-context examples as task demonstrations. SMMILE encompasses 111 problems (517 question-image-answer triplets) covering 6 medical specialties and 13 imaging modalities. We further introduce SMMILE++, an augmented variant with 1038 permuted problems. A comprehensive evaluation of 15 MLLMs demonstrates that most models exhibit moderate to poor multimodal ICL ability in medical tasks. In open-ended evaluations, ICL contributes only 8% average improvement over zero-shot on SMMILE and 9.4% on SMMILE++. We observe a susceptibility for irrelevant in-context examples: even a single noisy or irrelevant example can degrade performance by up to 9.5%. Moreover, example ordering exhibits a recency bias, i.e., placing the most relevant example last can lead to substantial performance improvements by up to 71%. Our findings highlight critical limitations and biases in current MLLMs when learning multimodal medical tasks from context.
Automated Structured Radiology Report Generation
May 30, 2025Automated radiology report generation from chest X-ray (CXR) images has the potential to improve clinical efficiency and reduce radiologists' workload. However, most datasets, including the publicly available MIMIC-CXR and CheXpert Plus, consist entirely of free-form reports, which are inherently variable and unstructured. This variability poses challenges for both generation and evaluation: existing models struggle to produce consistent, clinically meaningful reports, and standard evaluation metrics fail to capture the nuances of radiological interpretation. To address this, we introduce Structured Radiology Report Generation (SRRG), a new task that reformulates free-text radiology reports into a standardized format, ensuring clarity, consistency, and structured clinical reporting. We create a novel dataset by restructuring reports using large language models (LLMs) following strict structured reporting desiderata. Additionally, we introduce SRR-BERT, a fine-grained disease classification model trained on 55 labels, enabling more precise and clinically informed evaluation of structured reports. To assess report quality, we propose F1-SRR-BERT, a metric that leverages SRR-BERT's hierarchical disease taxonomy to bridge the gap between free-text variability and structured clinical reporting. We validate our dataset through a reader study conducted by five board-certified radiologists and extensive benchmarking experiments.
MedVAE: Efficient Automated Interpretation of Medical Images with Large-Scale Generalizable Autoencoders
Feb 20, 2025



Medical images are acquired at high resolutions with large fields of view in order to capture fine-grained features necessary for clinical decision-making. Consequently, training deep learning models on medical images can incur large computational costs. In this work, we address the challenge of downsizing medical images in order to improve downstream computational efficiency while preserving clinically-relevant features. We introduce MedVAE, a family of six large-scale 2D and 3D autoencoders capable of encoding medical images as downsized latent representations and decoding latent representations back to high-resolution images. We train MedVAE autoencoders using a novel two-stage training approach with 1,052,730 medical images. Across diverse tasks obtained from 20 medical image datasets, we demonstrate that (1) utilizing MedVAE latent representations in place of high-resolution images when training downstream models can lead to efficiency benefits (up to 70x improvement in throughput) while simultaneously preserving clinically-relevant features and (2) MedVAE can decode latent representations back to high-resolution images with high fidelity. Our work demonstrates that large-scale, generalizable autoencoders can help address critical efficiency challenges in the medical domain. Our code is available at https://github.com/StanfordMIMI/MedVAE.