 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Performance of Radiology Report De-identification with Large-Scale Training and Benchmarking Against Cloud Vendor Methods
Nov 06, 2025


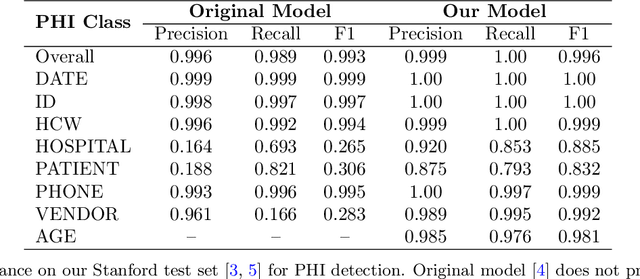
Objective: To enhance automated de-identification of radiology reports by scaling transformer-based models through extensive training datasets and benchmarking performance against commercial cloud vendor systems for protected health information (PHI) detection. Materials and Methods: In this retrospective study, we built upon a state-of-the-art, transformer-based, PHI de-identification pipeline by fine-tuning on two large annotated radiology corpora from Stanford University, encompassing chest X-ray, chest CT, abdomen/pelvis CT, and brain MR reports and introducing an additional PHI category (AGE) into the architecture. Model performance was evaluated on test sets from Stanford and the University of Pennsylvania (Penn) for token-level PHI detection. We further assessed (1) the stability of synthetic PHI generation using a "hide-in-plain-sight" method and (2) performance against commercial systems. Precision, recall, and F1 scores were computed across all PHI categories. Results: Our model achieved overall F1 scores of 0.973 on the Penn dataset and 0.996 on the Stanford dataset, outperforming or maintaining the previous state-of-the-art model performance. Synthetic PHI evaluation showed consistent detectability (overall F1: 0.959 [0.958-0.960]) across 50 independently de-identified Penn datasets. Our model outperformed all vendor systems on synthetic Penn reports (overall F1: 0.960 vs. 0.632-0.754). Discussion: Large-scale, multimodal training improved cross-institutional generalization and robustness. Synthetic PHI generation preserved data utility while ensuring privacy. Conclusion: A transformer-based de-identification model trained on diverse radiology datasets outperforms prior academic and commercial systems in PHI detection and establishes a new benchmark for secure clinical text processing.
Scaling laws for activation steering with Llama 2 models and refusal mechanisms
Jul 15, 2025As large language models (LLMs) evolve in complexity and capability, the efficacy of less widely deployed alignment techniques are uncertain. Building on previous work on activation steering and contrastive activation addition (CAA), this paper explores the effectiveness of CAA with model scale using the family of Llama 2 models (7B, 13B, and 70B). CAA works by finding desirable 'directions' in the model's residual stream vector space using contrastive pairs (for example, hate to love) and adding this direction to the residual stream during the forward pass. It directly manipulates the residual stream and aims to extract features from language models to better control their outputs. Using answer matching questions centered around the refusal behavior, we found that 1) CAA is most effective when applied at early-mid layers. 2) The effectiveness of CAA diminishes with model size. 3) Negative steering has more pronounced effects than positive steering across all model sizes.
Automated Structured Radiology Report Generation
May 30, 2025Automated radiology report generation from chest X-ray (CXR) images has the potential to improve clinical efficiency and reduce radiologists' workload. However, most datasets, including the publicly available MIMIC-CXR and CheXpert Plus, consist entirely of free-form reports, which are inherently variable and unstructured. This variability poses challenges for both generation and evaluation: existing models struggle to produce consistent, clinically meaningful reports, and standard evaluation metrics fail to capture the nuances of radiological interpretation. To address this, we introduce Structured Radiology Report Generation (SRRG), a new task that reformulates free-text radiology reports into a standardized format, ensuring clarity, consistency, and structured clinical reporting. We create a novel dataset by restructuring reports using large language models (LLMs) following strict structured reporting desiderata. Additionally, we introduce SRR-BERT, a fine-grained disease classification model trained on 55 labels, enabling more precise and clinically informed evaluation of structured reports. To assess report quality, we propose F1-SRR-BERT, a metric that leverages SRR-BERT's hierarchical disease taxonomy to bridge the gap between free-text variability and structured clinical reporting. We validate our dataset through a reader study conducted by five board-certified radiologists and extensive benchmarking experiments.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Preference Fine-Tuning for Factuality in Chest X-Ray Interpretation Models Without Human Feedback
Oct 09, 2024



Radiologists play a crucial role by translating medical images into medical reports. However, the field faces staffing shortages and increasing workloads. While automated approaches using vision-language models (VLMs) show promise as assistants, they require exceptionally high accuracy. Most current VLMs in radiology rely solely on supervised fine-tuning (SFT). Meanwhile, in the general domain, additional preference fine-tuning has become standard practice. The challenge in radiology lies in the prohibitive cost of obtaining radiologist feedback. We propose a scalable automated preference alignment technique for VLMs in radiology, focusing on chest X-ray (CXR) report generation. Our method leverages publicly available datasets with an LLM-as-a-Judge mechanism, eliminating the need for additional expert radiologist feedback. We evaluate and benchmark five direct alignment algorithms (DAAs). Our results show up to a 57.4% improvement in average GREEN scores, a LLM-based metric for evaluating CXR reports, and a 9.2% increase in an average across six metrics (domain specific and general), compared to the SFT baseline. We study reward overoptimization via length exploitation, with reports lengthening by up to 3.2x. To assess a potential alignment tax, we benchmark on six additional diverse tasks, finding no significant degradations. A reader study involving four board-certified radiologists indicates win rates of up to 0.62 over the SFT baseline, while significantly penalizing verbosity. Our analysis provides actionable insights for the development of VLMs in high-stakes fields like radiology.
Overview of the First Shared Task on Clinical Text Generation: RRG24 and "Discharge Me!"
Sep 25, 2024



Recent developments in natural language generation have tremendous implications for healthcare. For instance, state-of-the-art systems could automate the generation of sections in clinical reports to alleviate physician workload and streamline hospital documentation. To explore these applications, we present a shared task consisting of two subtasks: (1) Radiology Report Generation (RRG24) and (2) Discharge Summary Generation ("Discharge Me!"). RRG24 involves generating the 'Findings' and 'Impression' sections of radiology reports given chest X-rays. "Discharge Me!" involves generating the 'Brief Hospital Course' and 'Discharge Instructions' sections of discharge summaries for patients admitted through the emergency department. "Discharge Me!" submissions were subsequently reviewed by a team of clinicians. Both tasks emphasize the goal of reducing clinician burnout and repetitive workloads by generating documentation. We received 201 submissions from across 8 teams for RRG24, and 211 submissions from across 16 teams for "Discharge Me!".
* ACL Proceedings. BioNLP workshop
ACES: Automatic Cohort Extraction System for Event-Stream Datasets
Jun 28, 2024Reproducibility remains a significant challenge in machine learning (ML) for healthcare. In this field, datasets, model pipelines, and even task/cohort definitions are often private, leading to a significant barrier in sharing, iterating, and understanding ML results on electronic health record (EHR) datasets. In this paper, we address a significant part of this problem by introducing the Automatic Cohort Extraction System for Event-Stream Datasets (ACES). This tool is designed to simultaneously simplify the development of task/cohorts for ML in healthcare and enable the reproduction of these cohorts, both at an exact level for single datasets and at a conceptual level across datasets. To accomplish this, ACES provides (1) a highly intuitive and expressive configuration language for defining both dataset-specific concepts and dataset-agnostic inclusion/exclusion criteria, and (2) a pipeline to automatically extract patient records that meet these defined criteria from real-world data. ACES can be automatically applied to any dataset in either the Medical Event Data Standard (MEDS) or EventStreamGPT (ESGPT) formats, or to *any* dataset for which the necessary task-specific predicates can be extracted in an event-stream form. ACES has the potential to significantly lower the barrier to entry for defining ML tasks, redefine the way researchers interact with EHR datasets, and significantly improve the state of reproducibility for ML studies in this modality. ACES is available at https://github.com/justin13601/aces.
GREEN: Generative Radiology Report Evaluation and Error Notation
May 06, 2024


Evaluating radiology reports is a challenging problem as factual correctness is extremely important due to the need for accurate medical communication about medical images. Existing automatic evaluation metrics either suffer from failing to consider factual correctness (e.g., BLEU and ROUGE) or are limited in their interpretability (e.g., F1CheXpert and F1RadGraph). In this paper, we introduce GREEN (Generative Radiology Report Evaluation and Error Notation), a radiology report generation metric that leverages the natural language understanding of language models to identify and explain clinically significant errors in candidate reports, both quantitatively and qualitatively. Compared to current metrics, GREEN offers: 1) a score aligned with expert preferences, 2) human interpretable explanations of clinically significant errors, enabling feedback loops with end-users, and 3) a lightweight open-source method that reaches the performance of commercial counterparts. We validate our GREEN metric by comparing it to GPT-4, as well as to error counts of 6 experts and preferences of 2 experts. Our method demonstrates not only higher correlation with expert error counts, but simultaneously higher alignment with expert preferences when compared to previous approaches."