 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Variance-reduced Estimation from Generative EHR Models: The SCOPE and REACH Estimators
Feb 03, 2026Generative models trained using self-supervision of tokenized electronic health record (EHR) timelines show promise for clinical outcome prediction. This is typically done using Monte Carlo simulation for future patient trajectories. However, existing approaches suffer from three key limitations: sparse estimate distributions that poorly differentiate patient risk levels, extreme computational costs, and high sampling variance. We propose two new estimators: the Sum of Conditional Outcome Probability Estimator (SCOPE) and Risk Estimation from Anticipated Conditional Hazards (REACH), that leverage next-token probability distributions discarded by standard Monte Carlo. We prove both estimators are unbiased and that REACH guarantees variance reduction over Monte Carlo sampling for any model and outcome. Empirically, on hospital mortality prediction in MIMIC-IV using the ETHOS-ARES framework, SCOPE and REACH match 100-sample Monte Carlo performance using only 10-11 samples (95% CI: [9,11]), representing a ~10x reduction in inference cost without degrading calibration. For ICU admission prediction, efficiency gains are more modest (~1.2x), which we attribute to the outcome's lower "spontaneity," a property we characterize theoretically and empirically. These methods substantially improve the feasibility of deploying generative EHR models in resource-constrained clinical settings.
Foundation Model of Electronic Medical Records for Adaptive Risk Estimation
Feb 10, 2025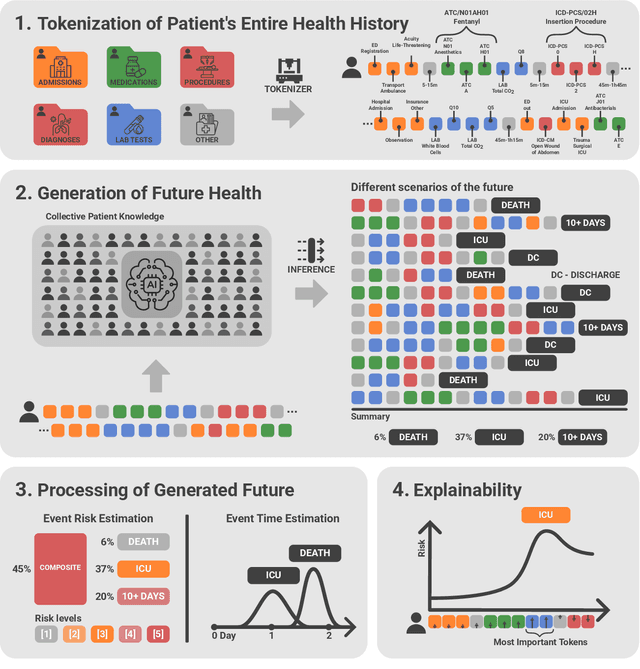
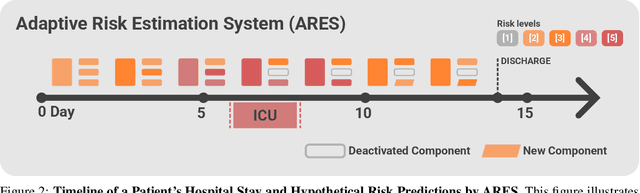
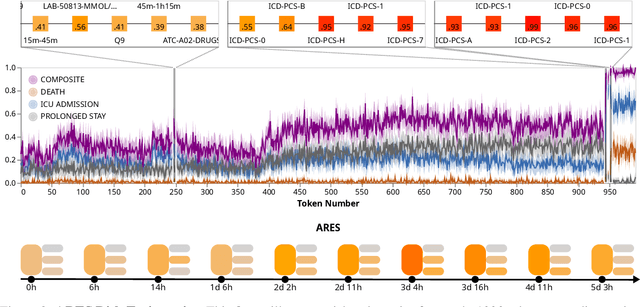
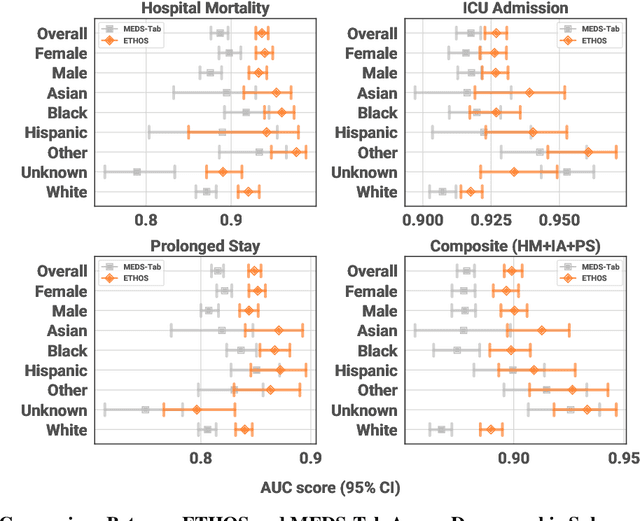
We developed the Enhanced Transformer for Health Outcome Simulation (ETHOS), an AI model that tokenizes patient health timelines (PHTs) from EHRs. ETHOS predicts future PHTs using transformer-based architectures. The Adaptive Risk Estimation System (ARES) employs ETHOS to compute dynamic and personalized risk probabilities for clinician-defined critical events. ARES incorporates a personalized explainability module that identifies key clinical factors influencing risk estimates for individual patients. ARES was evaluated on the MIMIC-IV v2.2 dataset in emergency department (ED) settings, benchmarking its performance against traditional early warning systems and machine learning models. We processed 299,721 unique patients from MIMIC-IV into 285,622 PHTs, with 60% including hospital admissions. The dataset contained over 357 million tokens. ETHOS outperformed benchmark models in predicting hospital admissions, ICU admissions, and prolonged hospital stays, achieving superior AUC scores. ETHOS-based risk estimates demonstrated robustness across demographic subgroups with strong model reliability, confirmed via calibration curves. The personalized explainability module provides insights into patient-specific factors contributing to risk. ARES, powered by ETHOS, advances predictive healthcare AI by providing dynamic, real-time, and personalized risk estimation with patient-specific explainability to enhance clinician trust. Its adaptability and superior accuracy position it as a transformative tool for clinical decision-making, potentially improving patient outcomes and resource allocation in emergency and inpatient settings. We release the full code at github.com/ipolharvard/ethos-ares to facilitate future research.
MEDS-Tab: Automated tabularization and baseline methods for MEDS datasets
Oct 31, 2024



Effective, reliable, and scalable development of machine learning (ML) solutions for structured electronic health record (EHR) data requires the ability to reliably generate high-quality baseline models for diverse supervised learning tasks in an efficient and performant manner. Historically, producing such baseline models has been a largely manual effort--individual researchers would need to decide on the particular featurization and tabularization processes to apply to their individual raw, longitudinal data; and then train a supervised model over those data to produce a baseline result to compare novel methods against, all for just one task and one dataset. In this work, powered by complementary advances in core data standardization through the MEDS framework, we dramatically simplify and accelerate this process of tabularizing irregularly sampled time-series data, providing researchers the ability to automatically and scalably featurize and tabularize their longitudinal EHR data across tens of thousands of individual features, hundreds of millions of clinical events, and diverse windowing horizons and aggregation strategies, all before ultimately leveraging these tabular data to automatically produce high-caliber XGBoost baselines in a highly computationally efficient manner. This system scales to dramatically larger datasets than tabularization tools currently available to the community and enables researchers with any MEDS format dataset to immediately begin producing reliable and performant baseline prediction results on various tasks, with minimal human effort required. This system will greatly enhance the reliability, reproducibility, and ease of development of powerful ML solutions for health problems across diverse datasets and clinical settings.
meds_reader: A fast and efficient EHR processing library
Sep 12, 2024



The growing demand for machine learning in healthcare requires processing increasingly large electronic health record (EHR) datasets, but existing pipelines are not computationally efficient or scalable. In this paper, we introduce meds_reader, an optimized Python package for efficient EHR data processing that is designed to take advantage of many intrinsic properties of EHR data for improved speed. We then demonstrate the benefits of meds_reader by reimplementing key components of two major EHR processing pipelines, achieving 10-100x improvements in memory, speed, and disk usage. The code for meds_reader can be found at https://github.com/som-shahlab/meds_reader.
ACES: Automatic Cohort Extraction System for Event-Stream Datasets
Jun 28, 2024Reproducibility remains a significant challenge in machine learning (ML) for healthcare. In this field, datasets, model pipelines, and even task/cohort definitions are often private, leading to a significant barrier in sharing, iterating, and understanding ML results on electronic health record (EHR) datasets. In this paper, we address a significant part of this problem by introducing the Automatic Cohort Extraction System for Event-Stream Datasets (ACES). This tool is designed to simultaneously simplify the development of task/cohorts for ML in healthcare and enable the reproduction of these cohorts, both at an exact level for single datasets and at a conceptual level across datasets. To accomplish this, ACES provides (1) a highly intuitive and expressive configuration language for defining both dataset-specific concepts and dataset-agnostic inclusion/exclusion criteria, and (2) a pipeline to automatically extract patient records that meet these defined criteria from real-world data. ACES can be automatically applied to any dataset in either the Medical Event Data Standard (MEDS) or EventStreamGPT (ESGPT) formats, or to *any* dataset for which the necessary task-specific predicates can be extracted in an event-stream form. ACES has the potential to significantly lower the barrier to entry for defining ML tasks, redefine the way researchers interact with EHR datasets, and significantly improve the state of reproducibility for ML studies in this modality. ACES is available at https://github.com/justin13601/aces.
A Closer Look at AUROC and AUPRC under Class Imbalance
Jan 11, 2024
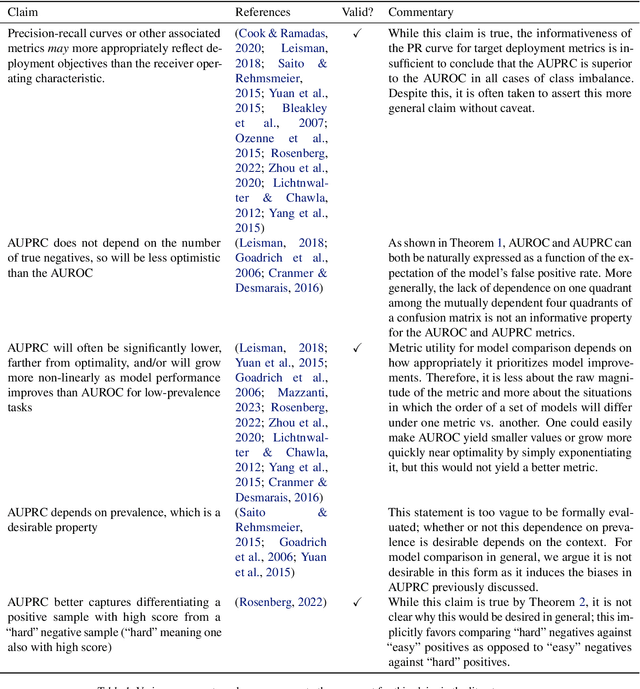

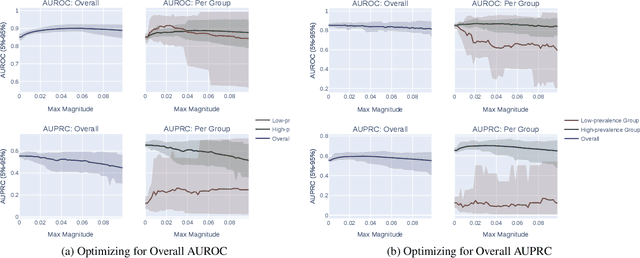
In machine learning (ML), a widespread adage is that the area under the precision-recall curve (AUPRC) is a superior metric for model comparison to the area under the receiver operating characteristic (AUROC) for binary classification tasks with class imbalance. This paper challenges this notion through novel mathematical analysis, illustrating that AUROC and AUPRC can be concisely related in probabilistic terms. We demonstrate that AUPRC, contrary to popular belief, is not superior in cases of class imbalance and might even be a harmful metric, given its inclination to unduly favor model improvements in subpopulations with more frequent positive labels. This bias can inadvertently heighten algorithmic disparities. Prompted by these insights, a thorough review of existing ML literature was conducted, utilizing large language models to analyze over 1.5 million papers from arXiv. Our investigation focused on the prevalence and substantiation of the purported AUPRC superiority. The results expose a significant deficit in empirical backing and a trend of misattributions that have fuelled the widespread acceptance of AUPRC's supposed advantages. Our findings represent a dual contribution: a significant technical advancement in understanding metric behaviors and a stark warning about unchecked assumptions in the ML community. All experiments are accessible at https://github.com/mmcdermott/AUC_is_all_you_need.
Event Stream GPT: A Data Pre-processing and Modeling Library for Generative, Pre-trained Transformers over Continuous-time Sequences of Complex Events
Jun 21, 2023Generative, pre-trained transformers (GPTs, a.k.a. "Foundation Models") have reshaped natural language processing (NLP) through their versatility in diverse downstream tasks. However, their potential extends far beyond NLP. This paper provides a software utility to help realize this potential, extending the applicability of GPTs to continuous-time sequences of complex events with internal dependencies, such as medical record datasets. Despite their potential, the adoption of foundation models in these domains has been hampered by the lack of suitable tools for model construction and evaluation. To bridge this gap, we introduce Event Stream GPT (ESGPT), an open-source library designed to streamline the end-to-end process for building GPTs for continuous-time event sequences. ESGPT allows users to (1) build flexible, foundation-model scale input datasets by specifying only a minimal configuration file, (2) leverage a Hugging Face compatible modeling API for GPTs over this modality that incorporates intra-event causal dependency structures and autoregressive generation capabilities, and (3) evaluate models via standardized processes that can assess few and even zero-shot performance of pre-trained models on user-specified fine-tuning tasks.
A collection of the accepted abstracts for the Machine Learning for Health symposium 2021
Nov 30, 2021A collection of the accepted abstracts for the Machine Learning for Health (ML4H) symposium 2021. This index is not complete, as some accepted abstracts chose to opt-out of inclusion.
Rethinking Relational Encoding in Language Model: Pre-Training for General Sequences
Mar 18, 2021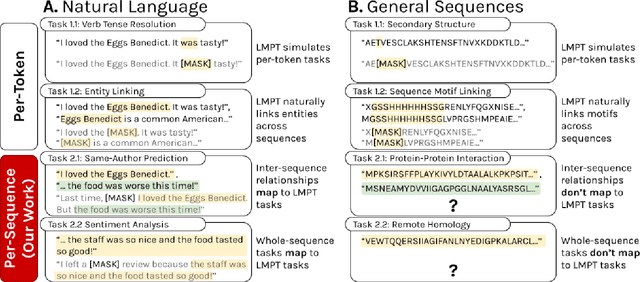
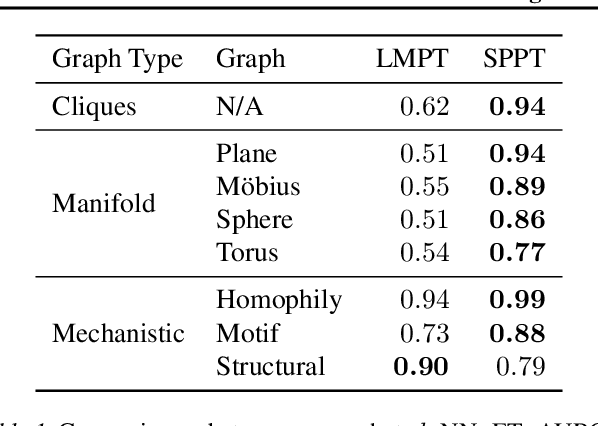
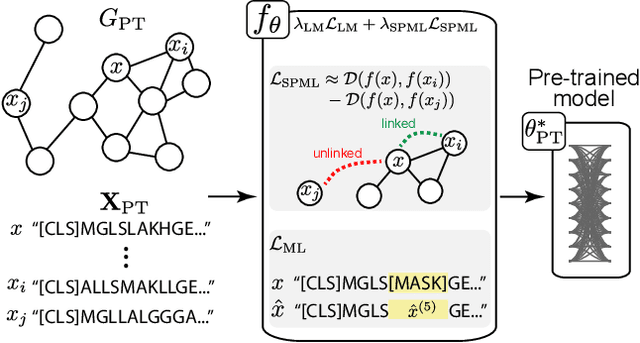
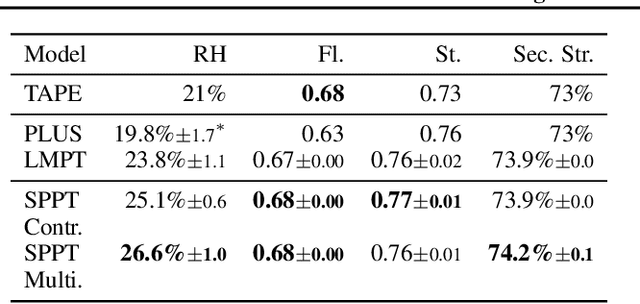
Language model pre-training (LMPT) has achieved remarkable results in natural language understanding. However, LMPT is much less successful in non-natural language domains like protein sequences, revealing a crucial discrepancy between the various sequential domains. Here, we posit that while LMPT can effectively model per-token relations, it fails at modeling per-sequence relations in non-natural language domains. To this end, we develop a framework that couples LMPT with deep structure-preserving metric learning to produce richer embeddings than can be obtained from LMPT alone. We examine new and existing pre-training models in this framework and theoretically analyze the framework overall. We also design experiments on a variety of synthetic datasets and new graph-augmented datasets of proteins and scientific abstracts. Our approach offers notable performance improvements on downstream tasks, including prediction of protein remote homology and classification of citation intent.
Adversarial Contrastive Pre-training for Protein Sequences
Jan 31, 2021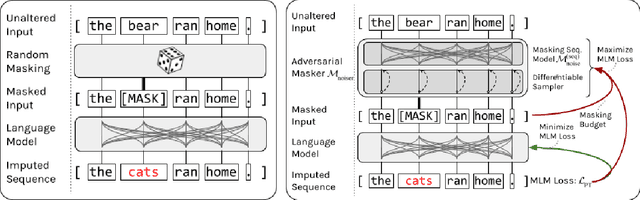

Recent developments in Natural Language Processing (NLP) demonstrate that large-scale, self-supervised pre-training can be extremely beneficial for downstream tasks. These ideas have been adapted to other domains, including the analysis of the amino acid sequences of proteins. However, to date most attempts on protein sequences rely on direct masked language model style pre-training. In this work, we design a new, adversarial pre-training method for proteins, extending and specializing similar advances in NLP. We show compelling results in comparison to traditional MLM pre-training, though further development is needed to ensure the gains are worth the significant computational cost.