 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeds of Stereotypes: A Large-Scale Textual Analysis of Race and Gender Associations with Diseases in Online Sources
May 08, 2024Background Advancements in Large Language Models (LLMs) hold transformative potential in healthcare, however, recent work has raised concern about the tendency of these models to produce outputs that display racial or gender biases. Although training data is a likely source of such biases, exploration of disease and demographic associations in text data at scale has been limited. Methods We conducted a large-scale textual analysis using a dataset comprising diverse web sources, including Arxiv, Wikipedia, and Common Crawl. The study analyzed the context in which various diseases are discussed alongside markers of race and gender. Given that LLMs are pre-trained on similar datasets, this approach allowed us to examine the potential biases that LLMs may learn and internalize. We compared these findings with actual demographic disease prevalence as well as GPT-4 outputs in order to evaluate the extent of bias representation. Results Our findings indicate that demographic terms are disproportionately associated with specific disease concepts in online texts. gender terms are prominently associated with disease concepts, while racial terms are much less frequently associated. We find widespread disparities in the associations of specific racial and gender terms with the 18 diseases analyzed. Most prominently, we see an overall significant overrepresentation of Black race mentions in comparison to population proportions. Conclusions Our results highlight the need for critical examination and transparent reporting of biases in LLM pretraining datasets. Our study suggests the need to develop mitigation strategies to counteract the influence of biased training data in LLMs, particularly in sensitive domains such as healthcare.
A Closer Look at AUROC and AUPRC under Class Imbalance
Jan 11, 2024

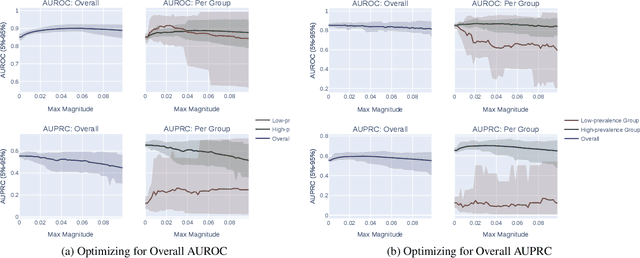
In machine learning (ML), a widespread adage is that the area under the precision-recall curve (AUPRC) is a superior metric for model comparison to the area under the receiver operating characteristic (AUROC) for binary classification tasks with class imbalance. This paper challenges this notion through novel mathematical analysis, illustrating that AUROC and AUPRC can be concisely related in probabilistic terms. We demonstrate that AUPRC, contrary to popular belief, is not superior in cases of class imbalance and might even be a harmful metric, given its inclination to unduly favor model improvements in subpopulations with more frequent positive labels. This bias can inadvertently heighten algorithmic disparities. Prompted by these insights, a thorough review of existing ML literature was conducted, utilizing large language models to analyze over 1.5 million papers from arXiv. Our investigation focused on the prevalence and substantiation of the purported AUPRC superiority. The results expose a significant deficit in empirical backing and a trend of misattributions that have fuelled the widespread acceptance of AUPRC's supposed advantages. Our findings represent a dual contribution: a significant technical advancement in understanding metric behaviors and a stark warning about unchecked assumptions in the ML community. All experiments are accessible at https://github.com/mmcdermott/AUC_is_all_you_need.