 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Vision Language Models (VLMs) for Radiology: A Comprehensive Analysis
Apr 22, 2025Foundation models, trained on vast amounts of data using self-supervised techniques, have emerged as a promising frontier for advancing artificial intelligence (AI) applications in medicine. This study evaluates three different vision-language foundation models (RAD-DINO, CheXagent, and BiomedCLIP) on their ability to capture fine-grained imaging features for radiology tasks. The models were assessed across classification, segmentation, and regression tasks for pneumothorax and cardiomegaly on chest radiographs. Self-supervised RAD-DINO consistently excelled in segmentation tasks, while text-supervised CheXagent demonstrated superior classification performance. BiomedCLIP showed inconsistent performance across tasks. A custom segmentation model that integrates global and local features substantially improved performance for all foundation models, particularly for challenging pneumothorax segmentation. The findings highlight that pre-training methodology significantly influences model performance on specific downstream tasks. For fine-grained segmentation tasks, models trained without text supervision performed better, while text-supervised models offered advantages in classification and interpretability. These insights provide guidance for selecting foundation models based on specific clinical applications in radiology.
A Multi-Modal AI System for Screening Mammography: Integrating 2D and 3D Imaging to Improve Breast Cancer Detection in a Prospective Clinical Study
Apr 08, 2025Although digital breast tomosynthesis (DBT) improves diagnostic performance over full-field digital mammography (FFDM), false-positive recalls remain a concern in breast cancer screening. We developed a multi-modal artificial intelligence system integrating FFDM, synthetic mammography, and DBT to provide breast-level predictions and bounding-box localizations of suspicious findings. Our AI system, trained on approximately 500,000 mammography exams, achieved 0.945 AUROC on an internal test set. It demonstrated capacity to reduce recalls by 31.7% and radiologist workload by 43.8% while maintaining 100% sensitivity, underscoring its potential to improve clinical workflows. External validation confirmed strong generalizability, reducing the gap to a perfect AUROC by 35.31%-69.14% relative to strong baselines. In prospective deployment across 18 sites, the system reduced recall rates for low-risk cases. An improved version, trained on over 750,000 exams with additional labels, further reduced the gap by 18.86%-56.62% across large external datasets. Overall, these results underscore the importance of utilizing all available imaging modalities, demonstrate the potential for clinical impact, and indicate feasibility of further reduction of the test error with increased training set when using large-capacity neural networks.
Novel AI-Based Quantification of Breast Arterial Calcification to Predict Cardiovascular Risk
Mar 17, 2025Women are underdiagnosed and undertreated for cardiovascular disease. Automatic quantification of breast arterial calcification on screening mammography can identify women at risk for cardiovascular disease and enable earlier treatment and management of disease. In this retrospective study of 116,135 women from two healthcare systems, a transformer-based neural network quantified BAC severity (no BAC, mild, moderate, and severe) on screening mammograms. Outcomes included major adverse cardiovascular events (MACE) and all-cause mortality. BAC severity was independently associated with MACE after adjusting for cardiovascular risk factors, with increasing hazard ratios from mild (HR 1.18-1.22), moderate (HR 1.38-1.47), to severe BAC (HR 2.03-2.22) across datasets (all p<0.001). This association remained significant across all age groups, with even mild BAC indicating increased risk in women under 50. BAC remained an independent predictor when analyzed alongside ASCVD risk scores, showing significant associations with myocardial infarction, stroke, heart failure, and mortality (all p<0.005). Automated BAC quantification enables opportunistic cardiovascular risk assessment during routine mammography without additional radiation or cost. This approach provides value beyond traditional risk factors, particularly in younger women, offering potential for early CVD risk stratification in the millions of women undergoing annual mammography.
AI and the Future of Work in Africa White Paper
Nov 15, 2024
This white paper is the output of a multidisciplinary workshop in Nairobi (Nov 2023). Led by a cross-organisational team including Microsoft Research, NEPAD, Lelapa AI, and University of Oxford. The workshop brought together diverse thought-leaders from various sectors and backgrounds to discuss the implications of Generative AI for the future of work in Africa. Discussions centred around four key themes: Macroeconomic Impacts; Jobs, Skills and Labour Markets; Workers' Perspectives and Africa-Centris AI Platforms. The white paper provides an overview of the current state and trends of generative AI and its applications in different domains, as well as the challenges and risks associated with its adoption and regulation. It represents a diverse set of perspectives to create a set of insights and recommendations which aim to encourage debate and collaborative action towards creating a dignified future of work for everyone across Africa.
Emory Knee Radiograph (MRKR) Dataset
Oct 30, 2024The Emory Knee Radiograph (MRKR) dataset is a large, demographically diverse collection of 503,261 knee radiographs from 83,011 patients, 40% of which are African American. This dataset provides imaging data in DICOM format along with detailed clinical information, including patient-reported pain scores, diagnostic codes, and procedural codes, which are not commonly available in similar datasets. The MRKR dataset also features imaging metadata such as image laterality, view type, and presence of hardware, enhancing its value for research and model development. MRKR addresses significant gaps in existing datasets by offering a more representative sample for studying osteoarthritis and related outcomes, particularly among minority populations, thereby providing a valuable resource for clinicians and researchers.
Seeds of Stereotypes: A Large-Scale Textual Analysis of Race and Gender Associations with Diseases in Online Sources
May 08, 2024Background Advancements in Large Language Models (LLMs) hold transformative potential in healthcare, however, recent work has raised concern about the tendency of these models to produce outputs that display racial or gender biases. Although training data is a likely source of such biases, exploration of disease and demographic associations in text data at scale has been limited. Methods We conducted a large-scale textual analysis using a dataset comprising diverse web sources, including Arxiv, Wikipedia, and Common Crawl. The study analyzed the context in which various diseases are discussed alongside markers of race and gender. Given that LLMs are pre-trained on similar datasets, this approach allowed us to examine the potential biases that LLMs may learn and internalize. We compared these findings with actual demographic disease prevalence as well as GPT-4 outputs in order to evaluate the extent of bias representation. Results Our findings indicate that demographic terms are disproportionately associated with specific disease concepts in online texts. gender terms are prominently associated with disease concepts, while racial terms are much less frequently associated. We find widespread disparities in the associations of specific racial and gender terms with the 18 diseases analyzed. Most prominently, we see an overall significant overrepresentation of Black race mentions in comparison to population proportions. Conclusions Our results highlight the need for critical examination and transparent reporting of biases in LLM pretraining datasets. Our study suggests the need to develop mitigation strategies to counteract the influence of biased training data in LLMs, particularly in sensitive domains such as healthcare.
Early Diagnosis of Chronic Obstructive Pulmonary Disease from Chest X-Rays using Transfer Learning and Fusion Strategies
Nov 13, 2022Chronic obstructive pulmonary disease (COPD) is one of the most common chronic illnesses in the world and the third leading cause of mortality worldwide. It is often underdiagnosed or not diagnosed until later in the disease course. Spirometry tests are the gold standard for diagnosing COPD but can be difficult to obtain, especially in resource-poor countries. Chest X-rays (CXRs), however, are readily available and may serve as a screening tool to identify patients with COPD who should undergo further testing. Currently, no research applies deep learning (DL) algorithms that use large multi-site and multi-modal data to detect COPD patients and evaluate fairness across demographic groups. We use three CXR datasets in our study, CheXpert to pre-train models, MIMIC-CXR to develop, and Emory-CXR to validate our models. The CXRs from patients in the early stage of COPD and not on mechanical ventilation are selected for model training and validation. We visualize the Grad-CAM heatmaps of the true positive cases on the base model for both MIMIC-CXR and Emory-CXR test datasets. We further propose two fusion schemes, (1) model-level fusion, including bagging and stacking methods using MIMIC-CXR, and (2) data-level fusion, including multi-site data using MIMIC-CXR and Emory-CXR, and multi-modal using MIMIC-CXRs and MIMIC-IV EHR, to improve the overall model performance. Fairness analysis is performed to evaluate if the fusion schemes have a discrepancy in the performance among different demographic groups. The results demonstrate that DL models can detect COPD using CXRs, which can facilitate early screening, especially in low-resource regions where CXRs are more accessible than spirometry. The multi-site data fusion scheme could improve the model generalizability on the Emory-CXR test data. Further studies on using CXR or other modalities to predict COPD ought to be in future work.
Advances in Prediction of Readmission Rates Using Long Term Short Term Memory Networks on Healthcare Insurance Data
Jun 30, 2022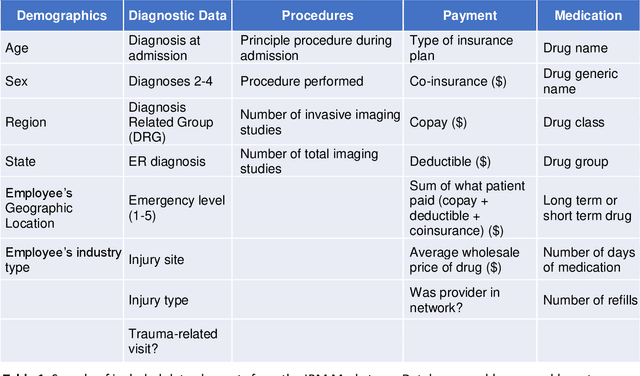
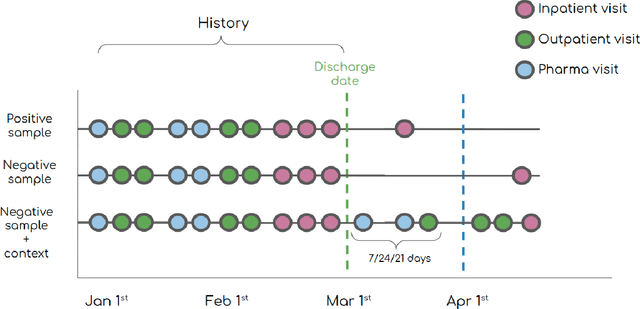
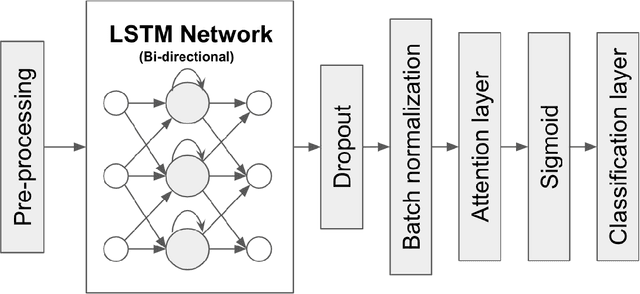
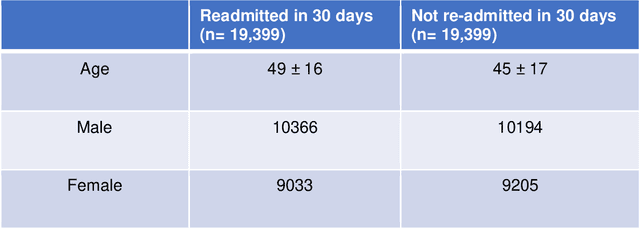
30-day hospital readmission is a long standing medical problem that affects patients' morbidity and mortality and costs billions of dollars annually. Recently, machine learning models have been created to predict risk of inpatient readmission for patients with specific diseases, however no model exists to predict this risk across all patients. We developed a bi-directional Long Short Term Memory (LSTM) Network that is able to use readily available insurance data (inpatient visits, outpatient visits, and drug prescriptions) to predict 30 day re-admission for any admitted patient, regardless of reason. The top-performing model achieved an ROC AUC of 0.763 (0.011) when using historical, inpatient, and post-discharge data. The LSTM model significantly outperformed a baseline random forest classifier, indicating that understanding the sequence of events is important for model prediction. Incorporation of 30-days of historical data also significantly improved model performance compared to inpatient data alone, indicating that a patients clinical history prior to admission, including outpatient visits and pharmacy data is a strong contributor to readmission. Our results demonstrate that a machine learning model is able to predict risk of inpatient readmission with reasonable accuracy for all patients using structured insurance billing data. Because billing data or equivalent surrogates can be extracted from sites, such a model could be deployed to identify patients at risk for readmission before they are discharged, or to assign more robust follow up (closer follow up, home health, mailed medications) to at-risk patients after discharge.
The EMory BrEast imaging Dataset : A Racially Diverse, Granular Dataset of 3.5M Screening and Diagnostic Mammograms
Feb 08, 2022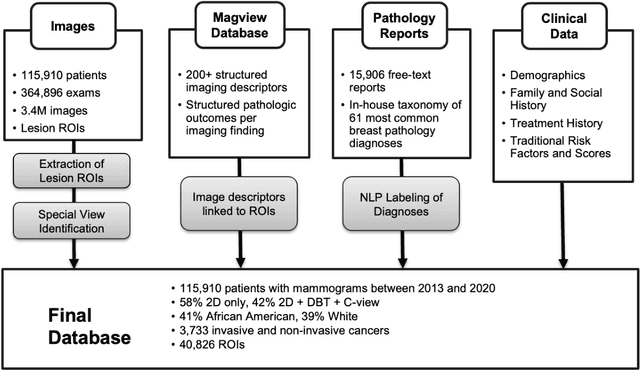
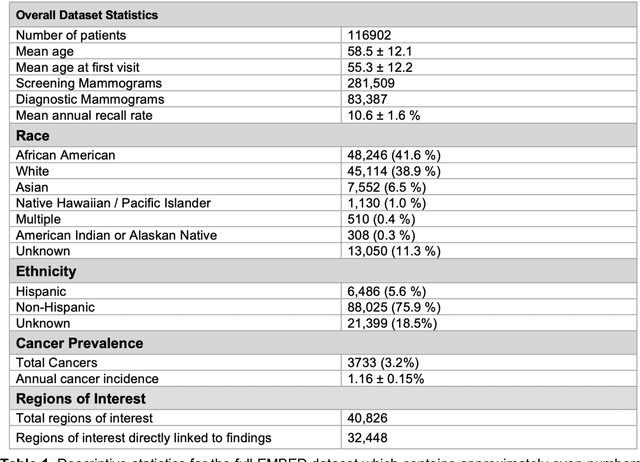
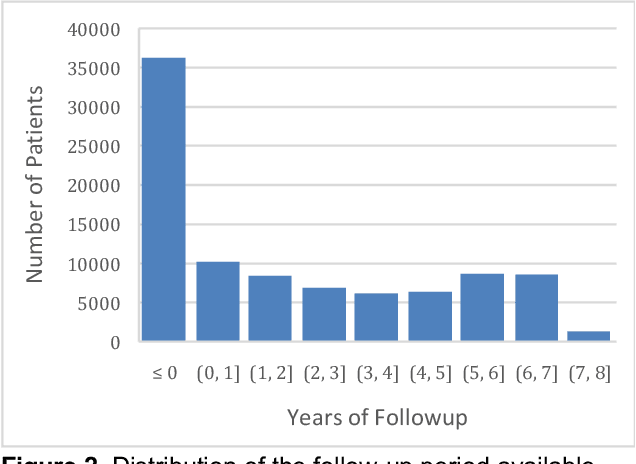

Developing and validating artificial intelligence models in medical imaging requires datasets that are large, granular, and diverse. To date, the majority of publicly available breast imaging datasets lack in one or more of these areas. Models trained on these data may therefore underperform on patient populations or pathologies that have not previously been encountered. The EMory BrEast imaging Dataset (EMBED) addresses these gaps by providing 3650,000 2D and DBT screening and diagnostic mammograms for 116,000 women divided equally between White and African American patients. The dataset also contains 40,000 annotated lesions linked to structured imaging descriptors and 61 ground truth pathologic outcomes grouped into six severity classes. Our goal is to share this dataset with research partners to aid in development and validation of breast AI models that will serve all patients fairly and help decrease bias in medical AI.
A Modern Non-SQL Approach to Radiology-Centric Search Engine Design with Clinical Validation
Jul 04, 2020
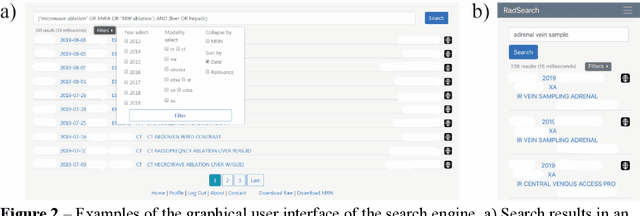
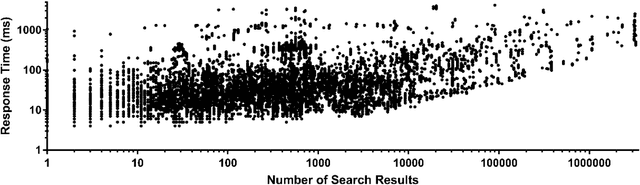

Healthcare data is increasing in size at an unprecedented speed with much attention on big data analysis and Artificial Intelligence application for quality assurance, clinical training, severity triaging, and decision support. Radiology is well-suited for innovation given its intrinsically paired linguistic and visual data. Previous attempts to unlock this information goldmine were encumbered by heterogeneity of human language, proprietary search algorithms, and lack of medicine-specific search performance matrices. We present a de novo process of developing a document-based, secure, efficient, and accurate search engine in the context of Radiology. We assess our implementation of the search engine with comparison to pre-existing manually collected clinical databases used previously for clinical research projects in addition to computational performance benchmarks and survey feedback. By leveraging efficient database architecture, search capability, and clinical thinking, radiologists are at the forefront of harnessing the power of healthcare data.